 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNineRec: A Benchmark Dataset Suite for Evaluating Transferable Recommendation
Sep 20, 2023



Learning a recommender system model from an item's raw modality features (such as image, text, audio, etc.), called MoRec, has attracted growing interest recently. One key advantage of MoRec is that it can easily benefit from advances in other fields, such as natural language processing (NLP) and computer vision (CV). Moreover, it naturally supports transfer learning across different systems through modality features, known as transferable recommender systems, or TransRec. However, so far, TransRec has made little progress, compared to groundbreaking foundation models in the fields of NLP and CV. The lack of large-scale, high-quality recommendation datasets poses a major obstacle. To this end, we introduce NineRec, a TransRec dataset suite that includes a large-scale source domain recommendation dataset and nine diverse target domain recommendation datasets. Each item in NineRec is represented by a text description and a high-resolution cover image. With NineRec, we can implement TransRec models in an end-to-end training manner instead of using pre-extracted invariant features. We conduct a benchmark study and empirical analysis of TransRec using NineRec, and our findings provide several valuable insights. To support further research, we make our code, datasets, benchmarks, and leaderboards publicly available at https://github.com/westlake-repl/NineRec.
An Image Dataset for Benchmarking Recommender Systems with Raw Pixels
Sep 17, 2023



Recommender systems (RS) have achieved significant success by leveraging explicit identification (ID) features. However, the full potential of content features, especially the pure image pixel features, remains relatively unexplored. The limited availability of large, diverse, and content-driven image recommendation datasets has hindered the use of raw images as item representations. In this regard, we present PixelRec, a massive image-centric recommendation dataset that includes approximately 200 million user-image interactions, 30 million users, and 400,000 high-quality cover images. By providing direct access to raw image pixels, PixelRec enables recommendation models to learn item representation directly from them. To demonstrate its utility, we begin by presenting the results of several classical pure ID-based baseline models, termed IDNet, trained on PixelRec. Then, to show the effectiveness of the dataset's image features, we substitute the itemID embeddings (from IDNet) with a powerful vision encoder that represents items using their raw image pixels. This new model is dubbed PixelNet.Our findings indicate that even in standard, non-cold start recommendation settings where IDNet is recognized as highly effective, PixelNet can already perform equally well or even better than IDNet. Moreover, PixelNet has several other notable advantages over IDNet, such as being more effective in cold-start and cross-domain recommendation scenarios. These results underscore the importance of visual features in PixelRec. We believe that PixelRec can serve as a critical resource and testing ground for research on recommendation models that emphasize image pixel content. The dataset, code, and leaderboard will be available at https://github.com/westlake-repl/PixelRec.
Learning and Optimization of Implicit Negative Feedback for Industrial Short-video Recommender System
Aug 25, 2023Short-video recommendation is one of the most important recommendation applications in today's industrial information systems. Compared with other recommendation tasks, the enormous amount of feedback is the most typical characteristic. Specifically, in short-video recommendation, the easiest-to-collect user feedback is from the skipping behaviors, which leads to two critical challenges for the recommendation model. First, the skipping behavior reflects implicit user preferences, and thus it is challenging for interest extraction. Second, the kind of special feedback involves multiple objectives, such as total watching time, which is also very challenging. In this paper, we present our industrial solution in Kuaishou, which serves billion-level users every day. Specifically, we deploy a feedback-aware encoding module which well extracts user preference taking the impact of context into consideration. We further design a multi-objective prediction module which well distinguishes the relation and differences among different model objectives in the short-video recommendation. We conduct extensive online A/B testing, along with detailed and careful analysis, which verifies the effectiveness of our solution.
Understanding and Modeling Passive-Negative Feedback for Short-video Sequential Recommendation
Aug 08, 2023Sequential recommendation is one of the most important tasks in recommender systems, which aims to recommend the next interacted item with historical behaviors as input. Traditional sequential recommendation always mainly considers the collected positive feedback such as click, purchase, etc. However, in short-video platforms such as TikTok, video viewing behavior may not always represent positive feedback. Specifically, the videos are played automatically, and users passively receive the recommended videos. In this new scenario, users passively express negative feedback by skipping over videos they do not like, which provides valuable information about their preferences. Different from the negative feedback studied in traditional recommender systems, this passive-negative feedback can reflect users' interests and serve as an important supervision signal in extracting users' preferences. Therefore, it is essential to carefully design and utilize it in this novel recommendation scenario. In this work, we first conduct analyses based on a large-scale real-world short-video behavior dataset and illustrate the significance of leveraging passive feedback. We then propose a novel method that deploys the sub-interest encoder, which incorporates positive feedback and passive-negative feedback as supervision signals to learn the user's current active sub-interest. Moreover, we introduce an adaptive fusion layer to integrate various sub-interests effectively. To enhance the robustness of our model, we then introduce a multi-task learning module to simultaneously optimize two kinds of feedback -- passive-negative feedback and traditional randomly-sampled negative feedback. The experiments on two large-scale datasets verify that the proposed method can significantly outperform state-of-the-art approaches. The code is released at https://github.com/tsinghua-fib-lab/RecSys2023-SINE.
Exploring Adapter-based Transfer Learning for Recommender Systems: Empirical Studies and Practical Insights
May 24, 2023Adapters, a plug-in neural network module with some tunable parameters, have emerged as a parameter-efficient transfer learning technique for adapting pre-trained models to downstream tasks, especially for natural language processing (NLP) and computer vision (CV) fields. Meanwhile, learning recommendation models directly from raw item modality features -- e.g., texts of NLP and images of CV -- can enable effective and transferable recommender systems (called TransRec). In view of this, a natural question arises: can adapter-based learning techniques achieve parameter-efficient TransRec with good performance? To this end, we perform empirical studies to address several key sub-questions. First, we ask whether the adapter-based TransRec performs comparably to TransRec based on standard full-parameter fine-tuning? does it hold for recommendation with different item modalities, e.g., textual RS and visual RS. If yes, we benchmark these existing adapters, which have been shown to be effective in NLP and CV tasks, in the item recommendation settings. Third, we carefully study several key factors for the adapter-based TransRec in terms of where and how to insert these adapters? Finally, we look at the effects of adapter-based TransRec by either scaling up its source training data or scaling down its target training data. Our paper provides key insights and practical guidance on unified & transferable recommendation -- a less studied recommendation scenario. We promise to release all code & datasets for future research.
Where to Go Next for Recommender Systems? ID- vs. Modality-based recommender models revisited
Mar 24, 2023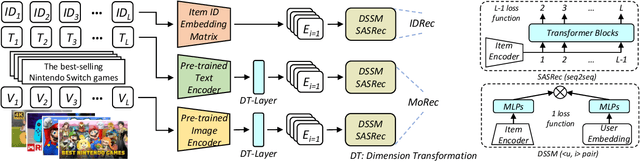


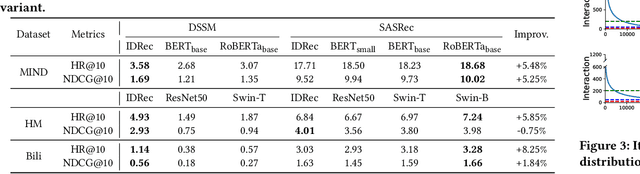
Recommendation models that utilize unique identities (IDs) to represent distinct users and items have been state-of-the-art (SOTA) and dominated the recommender systems (RS) literature for over a decade. Meanwhile, the pre-trained modality encoders, such as BERT and ViT, have become increasingly powerful in modeling the raw modality features of an item, such as text and images. Given this, a natural question arises: can a purely modality-based recommendation model (MoRec) outperforms or matches a pure ID-based model (IDRec) by replacing the itemID embedding with a SOTA modality encoder? In fact, this question was answered ten years ago when IDRec beats MoRec by a strong margin in both recommendation accuracy and efficiency. We aim to revisit this `old' question and systematically study MoRec from several aspects. Specifically, we study several sub-questions: (i) which recommendation paradigm, MoRec or IDRec, performs better in practical scenarios, especially in the general setting and warm item scenarios where IDRec has a strong advantage? does this hold for items with different modality features? (ii) can the latest technical advances from other communities (i.e., natural language processing and computer vision) translate into accuracy improvement for MoRec? (iii) how to effectively utilize item modality representation, can we use it directly or do we have to adjust it with new data? (iv) are there some key challenges for MoRec to be solved in practical applications? To answer them, we conduct rigorous experiments for item recommendations with two popular modalities, i.e., text and vision. We provide the first empirical evidence that MoRec is already comparable to its IDRec counterpart with an expensive end-to-end training method, even for warm item recommendation. Our results potentially imply that the dominance of IDRec in the RS field may be greatly challenged in the future.
Multi-Dimensional Self Attention based Approach for Remaining Useful Life Estimation
Dec 12, 2022Remaining Useful Life (RUL) estimation plays a critical role in Prognostics and Health Management (PHM). Traditional machine health maintenance systems are often costly, requiring sufficient prior expertise, and are difficult to fit into highly complex and changing industrial scenarios. With the widespread deployment of sensors on industrial equipment, building the Industrial Internet of Things (IIoT) to interconnect these devices has become an inexorable trend in the development of the digital factory. Using the device's real-time operational data collected by IIoT to get the estimated RUL through the RUL prediction algorithm, the PHM system can develop proactive maintenance measures for the device, thus, reducing maintenance costs and decreasing failure times during operation. This paper carries out research into the remaining useful life prediction model for multi-sensor devices in the IIoT scenario. We investigated the mainstream RUL prediction models and summarized the basic steps of RUL prediction modeling in this scenario. On this basis, a data-driven approach for RUL estimation is proposed in this paper. It employs a Multi-Head Attention Mechanism to fuse the multi-dimensional time-series data output from multiple sensors, in which the attention on features is used to capture the interactions between features and attention on sequences is used to learn the weights of time steps. Then, the Long Short-Term Memory Network is applied to learn the features of time series. We evaluate the proposed model on two benchmark datasets (C-MAPSS and PHM08), and the results demonstrate that it outperforms the state-of-art models. Moreover, through the interpretability of the multi-head attention mechanism, the proposed model can provide a preliminary explanation of engine degradation. Therefore, this approach is promising for predictive maintenance in IIoT scenarios.
Feng-Shui Compass: A Modern Exploration of Traditional Chinese Environmental Analysis
Oct 25, 2022



The technological advancement in data analysis and sensor technology has contributed to a growth in knowledge of the surrounding environments. Feng Shui, the Chinese philosophy of evaluating a certain environment and how it influences human well-being, can only be determined by self-claimed specialists for the past thousands of years. We developed a device as well as a procedure to evaluate the ambient environment of a room to perform a study that attempts to use sensor data to predict the well-being score of a person in that environment, therefore evaluating the primary aspect of Feng Shui. Our study revealed preliminary results showing great potential for further research with larger experiments.