 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiBerNAC: Hierarchical Brain-emulated Robotic Neural Agent Collective for Disentangling Complex Manipulation
Jun 11, 2025



Recent advances in multimodal vision-language-action (VLA) models have revolutionized traditional robot learning, enabling systems to interpret vision, language, and action in unified frameworks for complex task planning. However, mastering complex manipulation tasks remains an open challenge, constrained by limitations in persistent contextual memory, multi-agent coordination under uncertainty, and dynamic long-horizon planning across variable sequences. To address this challenge, we propose \textbf{HiBerNAC}, a \textbf{Hi}erarchical \textbf{B}rain-\textbf{e}mulated \textbf{r}obotic \textbf{N}eural \textbf{A}gent \textbf{C}ollective, inspired by breakthroughs in neuroscience, particularly in neural circuit mechanisms and hierarchical decision-making. Our framework combines: (1) multimodal VLA planning and reasoning with (2) neuro-inspired reflection and multi-agent mechanisms, specifically designed for complex robotic manipulation tasks. By leveraging neuro-inspired functional modules with decentralized multi-agent collaboration, our approach enables robust and enhanced real-time execution of complex manipulation tasks. In addition, the agentic system exhibits scalable collective intelligence via dynamic agent specialization, adapting its coordination strategy to variable task horizons and complexity. Through extensive experiments on complex manipulation tasks compared with state-of-the-art VLA models, we demonstrate that \textbf{HiBerNAC} reduces average long-horizon task completion time by 23\%, and achieves non-zero success rates (12\textendash 31\%) on multi-path tasks where prior state-of-the-art VLA models consistently fail. These results provide indicative evidence for bridging biological cognition and robotic learning mechanisms.
Soften the Mask: Adaptive Temporal Soft Mask for Efficient Dynamic Facial Expression Recognition
Feb 28, 2025Dynamic Facial Expression Recognition (DFER) facilitates the understanding of psychological intentions through non-verbal communication. Existing methods struggle to manage irrelevant information, such as background noise and redundant semantics, which impacts both efficiency and effectiveness. In this work, we propose a novel supervised temporal soft masked autoencoder network for DFER, namely AdaTosk, which integrates a parallel supervised classification branch with the self-supervised reconstruction branch. The self-supervised reconstruction branch applies random binary hard mask to generate diverse training samples, encouraging meaningful feature representations in visible tokens. Meanwhile the classification branch employs an adaptive temporal soft mask to flexibly mask visible tokens based on their temporal significance. Its two key components, respectively of, class-agnostic and class-semantic soft masks, serve to enhance critical expression moments and reduce semantic redundancy over time. Extensive experiments conducted on widely-used benchmarks demonstrate that our AdaTosk remarkably reduces computational costs compared with current state-of-the-art methods while still maintaining competitive performance.
Aligning in a Compact Space: Contrastive Knowledge Distillation between Heterogeneous Architectures
May 28, 2024



Knowledge distillation is commonly employed to compress neural networks, reducing the inference costs and memory footprint. In the scenario of homogenous architecture, feature-based methods have been widely validated for their effectiveness. However, in scenarios where the teacher and student models are of heterogeneous architectures, the inherent differences in feature representation significantly degrade the performance of these methods. Recent studies have highlighted that low-frequency components constitute the majority of image features. Motivated by this, we propose a Low-Frequency Components-based Contrastive Knowledge Distillation (LFCC) framework that significantly enhances the performance of feature-based distillation between heterogeneous architectures. Specifically, we designe a set of multi-scale low-pass filters to extract the low-frequency components of intermediate features from both the teacher and student models, aligning them in a compact space to overcome architectural disparities. Moreover, leveraging the intrinsic pairing characteristic of the teacher-student framework, we design an innovative sample-level contrastive learning framework that adeptly restructures the constraints of within-sample feature similarity and between-sample feature divergence into a contrastive learning task. This strategy enables the student model to capitalize on intra-sample feature congruence while simultaneously enhancing the discrimination of features among disparate samples. Consequently, our LFCC framework accurately captures the commonalities in feature representation across heterogeneous architectures. Extensive evaluations and empirical analyses across three architectures (CNNs, Transformers, and MLPs) demonstrate that LFCC achieves superior performance on the challenging benchmarks of ImageNet-1K and CIFAR-100. All codes will be publicly available.
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024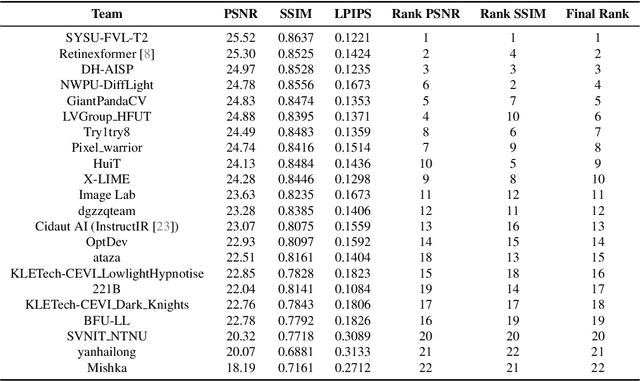


This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
Worst-Case Analysis is Maximum-A-Posteriori Estimation
Oct 15, 2023



The worst-case resource usage of a program can provide useful information for many software-engineering tasks, such as performance optimization and algorithmic-complexity-vulnerability discovery. This paper presents a generic, adaptive, and sound fuzzing framework, called DSE-SMC, for estimating worst-case resource usage. DSE-SMC is generic because it is black-box as long as the user provides an interface for retrieving resource-usage information on a given input; adaptive because it automatically balances between exploration and exploitation of candidate inputs; and sound because it is guaranteed to converge to the true resource-usage distribution of the analyzed program. DSE-SMC is built upon a key observation: resource accumulation in a program is isomorphic to the soft-conditioning mechanism in Bayesian probabilistic programming; thus, worst-case resource analysis is isomorphic to the maximum-a-posteriori-estimation problem of Bayesian statistics. DSE-SMC incorporates sequential Monte Carlo (SMC) -- a generic framework for Bayesian inference -- with adaptive evolutionary fuzzing algorithms, in a sound manner, i.e., DSE-SMC asymptotically converges to the posterior distribution induced by resource-usage behavior of the analyzed program. Experimental evaluation on Java applications demonstrates that DSE-SMC is significantly more effective than existing black-box fuzzing methods for worst-case analysis.
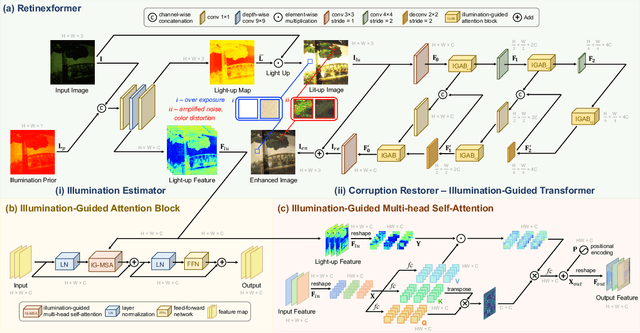
FourLLIE: Boosting Low-Light Image Enhancement by Fourier Frequency Information
Aug 06, 2023Recently, Fourier frequency information has attracted much attention in Low-Light Image Enhancement (LLIE). Some researchers noticed that, in the Fourier space, the lightness degradation mainly exists in the amplitude component and the rest exists in the phase component. By incorporating both the Fourier frequency and the spatial information, these researchers proposed remarkable solutions for LLIE. In this work, we further explore the positive correlation between the magnitude of amplitude and the magnitude of lightness, which can be effectively leveraged to improve the lightness of low-light images in the Fourier space. Moreover, we find that the Fourier transform can extract the global information of the image, and does not introduce massive neural network parameters like Multi-Layer Perceptrons (MLPs) or Transformer. To this end, a two-stage Fourier-based LLIE network (FourLLIE) is proposed. In the first stage, we improve the lightness of low-light images by estimating the amplitude transform map in the Fourier space. In the second stage, we introduce the Signal-to-Noise-Ratio (SNR) map to provide the prior for integrating the global Fourier frequency and the local spatial information, which recovers image details in the spatial space. With this ingenious design, FourLLIE outperforms the existing state-of-the-art (SOTA) LLIE methods on four representative datasets while maintaining good model efficiency.
Learning Graph ODE for Continuous-Time Sequential Recommendation
Apr 14, 2023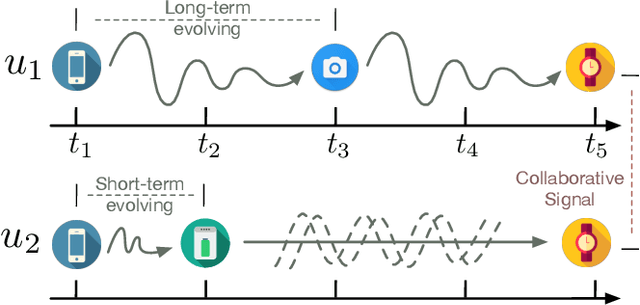
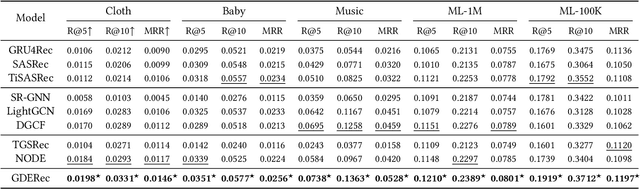
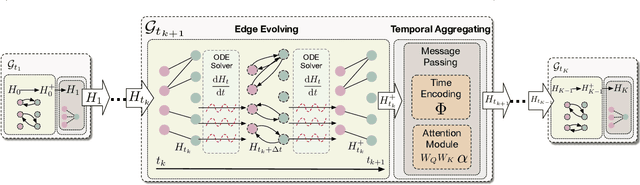
Sequential recommendation aims at understanding user preference by capturing successive behavior correlations, which are usually represented as the item purchasing sequences based on their past interactions. Existing efforts generally predict the next item via modeling the sequential patterns. Despite effectiveness, there exist two natural deficiencies: (i) user preference is dynamic in nature, and the evolution of collaborative signals is often ignored; and (ii) the observed interactions are often irregularly-sampled, while existing methods model item transitions assuming uniform intervals. Thus, how to effectively model and predict the underlying dynamics for user preference becomes a critical research problem. To tackle the above challenges, in this paper, we focus on continuous-time sequential recommendation and propose a principled graph ordinary differential equation framework named GDERec. Technically, GDERec is characterized by an autoregressive graph ordinary differential equation consisting of two components, which are parameterized by two tailored graph neural networks (GNNs) respectively to capture user preference from the perspective of hybrid dynamical systems. The two customized GNNs are trained alternately in an autoregressive manner to track the evolution of the underlying system from irregular observations, and thus learn effective representations of users and items beneficial to the sequential recommendation. Extensive experiments on five benchmark datasets demonstrate the superiority of our model over various state-of-the-art recommendation methods.
A Diffusion model for POI recommendation
Apr 14, 2023Next Point-of-Interest (POI) recommendation is a critical task in location-based services that aim to provide personalized suggestions for the user's next destination. Previous works on POI recommendation have laid focused on modeling the user's spatial preference. However, existing works that leverage spatial information are only based on the aggregation of users' previous visited positions, which discourages the model from recommending POIs in novel areas. This trait of position-based methods will harm the model's performance in many situations. Additionally, incorporating sequential information into the user's spatial preference remains a challenge. In this paper, we propose Diff-POI: a Diffusion-based model that samples the user's spatial preference for the next POI recommendation. Inspired by the wide application of diffusion algorithm in sampling from distributions, Diff-POI encodes the user's visiting sequence and spatial character with two tailor-designed graph encoding modules, followed by a diffusion-based sampling strategy to explore the user's spatial visiting trends. We leverage the diffusion process and its reversed form to sample from the posterior distribution and optimized the corresponding score function. We design a joint training and inference framework to optimize and evaluate the proposed Diff-POI. Extensive experiments on four real-world POI recommendation datasets demonstrate the superiority of our Diff-POI over state-of-the-art baseline methods. Further ablation and parameter studies on Diff-POI reveal the functionality and effectiveness of the proposed diffusion-based sampling strategy for addressing the limitations of existing methods.
Feng-Shui Compass: A Modern Exploration of Traditional Chinese Environmental Analysis
Oct 25, 2022



The technological advancement in data analysis and sensor technology has contributed to a growth in knowledge of the surrounding environments. Feng Shui, the Chinese philosophy of evaluating a certain environment and how it influences human well-being, can only be determined by self-claimed specialists for the past thousands of years. We developed a device as well as a procedure to evaluate the ambient environment of a room to perform a study that attempts to use sensor data to predict the well-being score of a person in that environment, therefore evaluating the primary aspect of Feng Shui. Our study revealed preliminary results showing great potential for further research with larger experiments.
A Survey of Toxic Comment Classification Methods
Dec 13, 2021


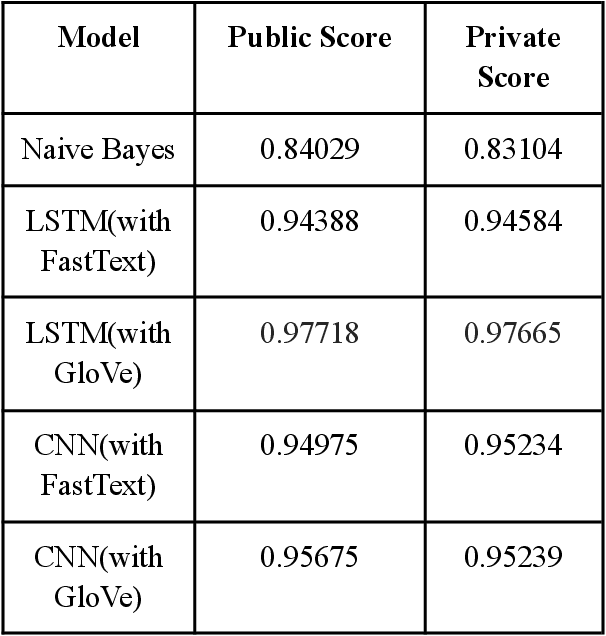
While in real life everyone behaves themselves at least to some extent, it is much more difficult to expect people to behave themselves on the internet, because there are few checks or consequences for posting something toxic to others. Yet, for people on the other side, toxic texts often lead to serious psychological consequences. Detecting such toxic texts is challenging. In this paper, we attempt to build a toxicity detector using machine learning methods including CNN, Naive Bayes model, as well as LSTM. While there has been numerous groundwork laid by others, we aim to build models that provide higher accuracy than the predecessors. We produced very high accuracy models using LSTM and CNN, and compared them to the go-to solutions in language processing, the Naive Bayes model. A word embedding approach is also applied to empower the accuracy of our models.