 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning in a Compact Space: Contrastive Knowledge Distillation between Heterogeneous Architectures
May 28, 2024



Knowledge distillation is commonly employed to compress neural networks, reducing the inference costs and memory footprint. In the scenario of homogenous architecture, feature-based methods have been widely validated for their effectiveness. However, in scenarios where the teacher and student models are of heterogeneous architectures, the inherent differences in feature representation significantly degrade the performance of these methods. Recent studies have highlighted that low-frequency components constitute the majority of image features. Motivated by this, we propose a Low-Frequency Components-based Contrastive Knowledge Distillation (LFCC) framework that significantly enhances the performance of feature-based distillation between heterogeneous architectures. Specifically, we designe a set of multi-scale low-pass filters to extract the low-frequency components of intermediate features from both the teacher and student models, aligning them in a compact space to overcome architectural disparities. Moreover, leveraging the intrinsic pairing characteristic of the teacher-student framework, we design an innovative sample-level contrastive learning framework that adeptly restructures the constraints of within-sample feature similarity and between-sample feature divergence into a contrastive learning task. This strategy enables the student model to capitalize on intra-sample feature congruence while simultaneously enhancing the discrimination of features among disparate samples. Consequently, our LFCC framework accurately captures the commonalities in feature representation across heterogeneous architectures. Extensive evaluations and empirical analyses across three architectures (CNNs, Transformers, and MLPs) demonstrate that LFCC achieves superior performance on the challenging benchmarks of ImageNet-1K and CIFAR-100. All codes will be publicly available.
Visual tracking brain computer interface
Nov 21, 2023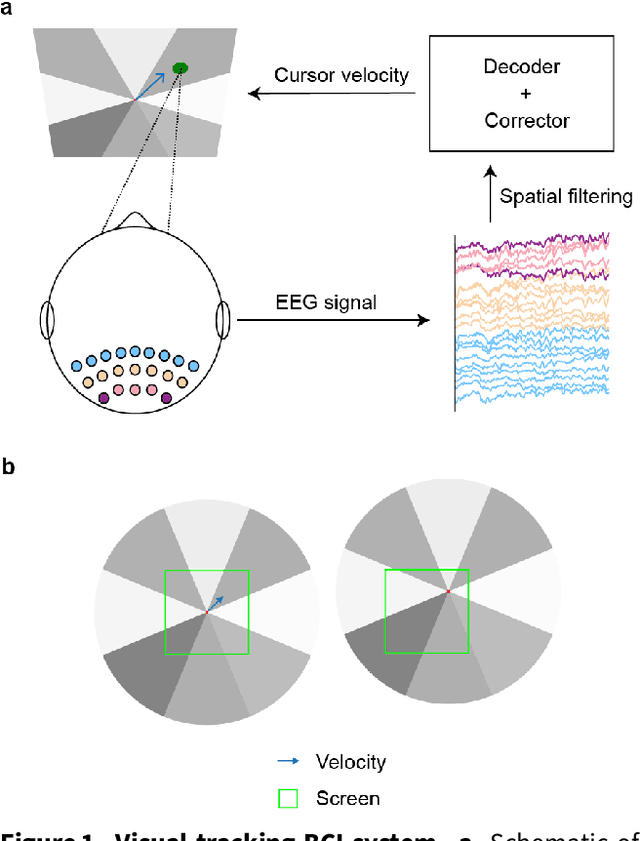
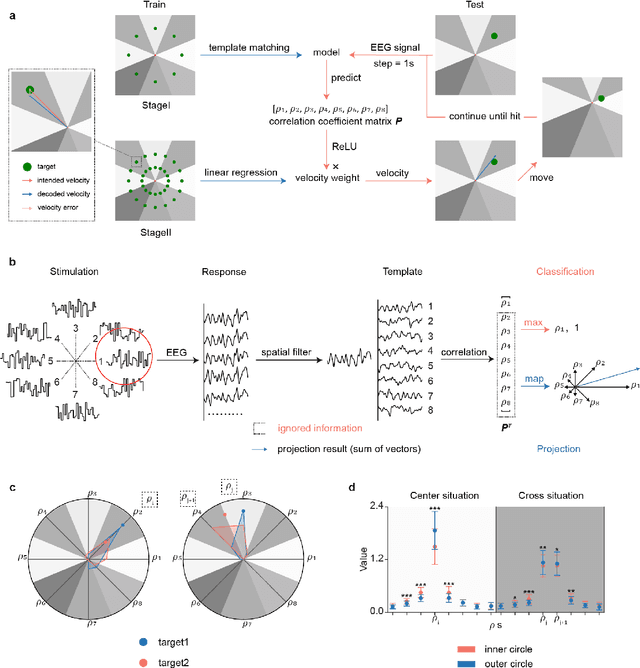
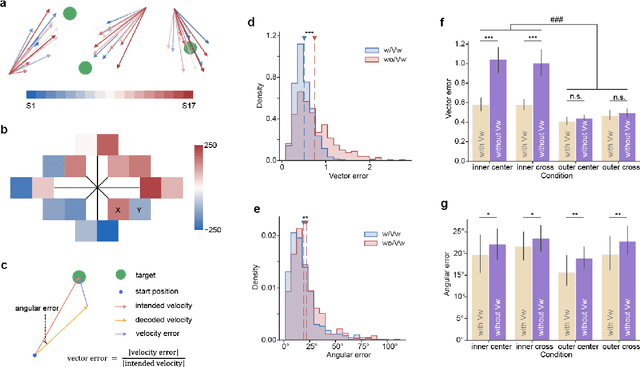
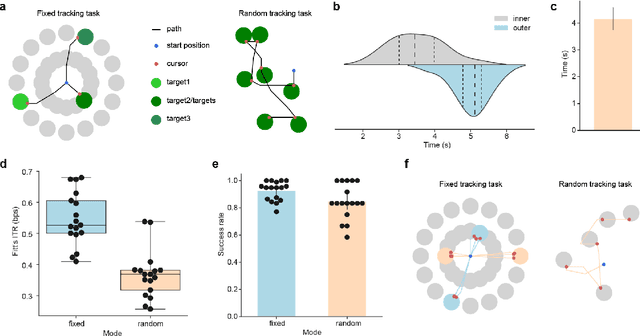
Brain-computer interfaces (BCIs) offer a way to interact with computers without relying on physical movements. Non-invasive electroencephalography (EEG)-based visual BCIs, known for efficient speed and calibration ease, face limitations in continuous tasks due to discrete stimulus design and decoding methods. To achieve continuous control, we implemented a novel spatial encoding stimulus paradigm and devised a corresponding projection method to enable continuous modulation of decoded velocity. Subsequently, we conducted experiments involving 17 participants and achieved Fitt's ITR of 0.55 bps for the fixed tracking task and 0.37 bps for the random tracking task. The proposed BCI with a high Fitt's ITR was then integrated into two applications, including painting and gaming. In conclusion, this study proposed a visual BCI-based control method to go beyond discrete commands, allowing natural continuous control based on neural activity.
High-performance cVEP-BCI under minimal calibration
Nov 20, 2023The ultimate goal of brain-computer interfaces (BCIs) based on visual modulation paradigms is to achieve high-speed performance without the burden of extensive calibration. Code-modulated visual evoked potential-based BCIs (cVEP-BCIs) modulated by broadband white noise (WN) offer various advantages, including increased communication speed, expanded encoding target capabilities, and enhanced coding flexibility. However, the complexity of the spatial-temporal patterns under broadband stimuli necessitates extensive calibration for effective target identification in cVEP-BCIs. Consequently, the information transfer rate (ITR) of cVEP-BCI under limited calibration usually stays around 100 bits per minute (bpm), significantly lagging behind state-of-the-art steady-state visual evoked potential-based BCIs (SSVEP-BCIs), which achieve rates above 200 bpm. To enhance the performance of cVEP-BCIs with minimal calibration, we devised an efficient calibration stage involving a brief single-target flickering, lasting less than a minute, to extract generalizable spatial-temporal patterns. Leveraging the calibration data, we developed two complementary methods to construct cVEP temporal patterns: the linear modeling method based on the stimulus sequence and the transfer learning techniques using cross-subject data. As a result, we achieved the highest ITR of 250 bpm under a minute of calibration, which has been shown to be comparable to the state-of-the-art SSVEP paradigms. In summary, our work significantly improved the cVEP performance under few-shot learning, which is expected to expand the practicality and usability of cVEP-BCIs.
Estimating and approaching maximum information rate of noninvasive visual brain-computer interface
Aug 25, 2023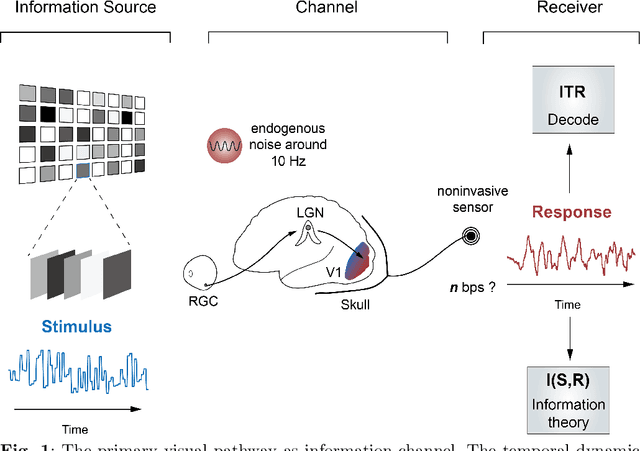
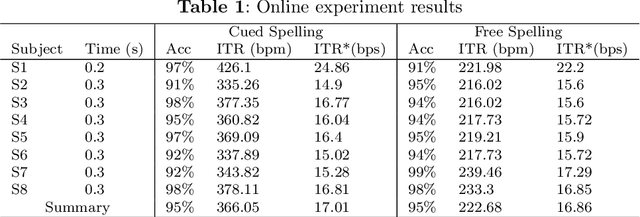
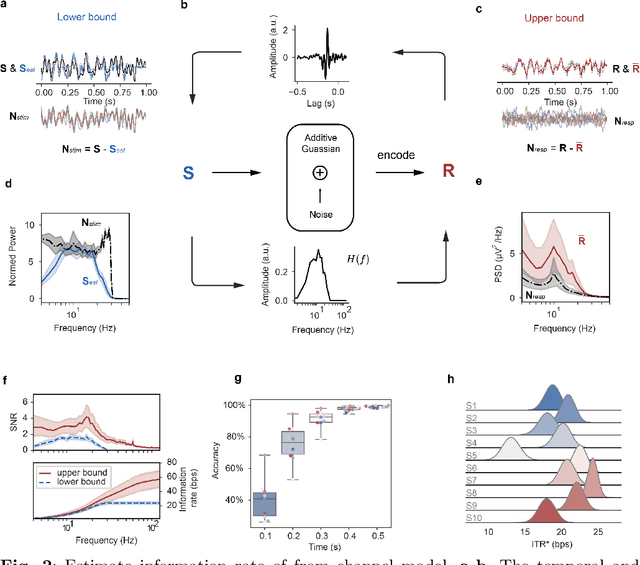

The mission of visual brain-computer interfaces (BCIs) is to enhance information transfer rate (ITR) to reach high speed towards real-life communication. Despite notable progress, noninvasive visual BCIs have encountered a plateau in ITRs, leaving it uncertain whether higher ITRs are achievable. In this study, we investigate the information rate limits of the primary visual channel to explore whether we can and how we should build visual BCI with higher information rate. Using information theory, we estimate a maximum achievable ITR of approximately 63 bits per second (bps) with a uniformly-distributed White Noise (WN) stimulus. Based on this discovery, we propose a broadband WN BCI approach that expands the utilization of stimulus bandwidth, in contrast to the current state-of-the-art visual BCI methods based on steady-state visual evoked potentials (SSVEPs). Through experimental validation, our broadband BCI outperforms the SSVEP BCI by an impressive margin of 7 bps, setting a new record of 50 bps. This achievement demonstrates the possibility of decoding 40 classes of noninvasive neural responses within a short duration of only 0.1 seconds. The information-theoretical framework introduced in this study provides valuable insights applicable to all sensory-evoked BCIs, making a significant step towards the development of next-generation human-machine interaction systems.