 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysicsMind: Sim and Real Mechanics Benchmarking for Physical Reasoning and Prediction in Foundational VLMs and World Models
Jan 22, 2026Modern foundational Multimodal Large Language Models (MLLMs) and video world models have advanced significantly in mathematical, common-sense, and visual reasoning, but their grasp of the underlying physics remains underexplored. Existing benchmarks attempting to measure this matter rely on synthetic, Visual Question Answer templates or focus on perceptual video quality that is tangential to measuring how well the video abides by physical laws. To address this fragmentation, we introduce PhysicsMind, a unified benchmark with both real and simulation environments that evaluates law-consistent reasoning and generation over three canonical principles: Center of Mass, Lever Equilibrium, and Newton's First Law. PhysicsMind comprises two main tasks: i) VQA tasks, testing whether models can reason and determine physical quantities and values from images or short videos, and ii) Video Generation(VG) tasks, evaluating if predicted motion trajectories obey the same center-of-mass, torque, and inertial constraints as the ground truth. A broad range of recent models and video generation models is evaluated on PhysicsMind and found to rely on appearance heuristics while often violating basic mechanics. These gaps indicate that current scaling and training are still insufficient for robust physical understanding, underscoring PhysicsMind as a focused testbed for physics-aware multimodal models. Our data will be released upon acceptance.
Teach Me How to Denoise: A Universal Framework for Denoising Multi-modal Recommender Systems via Guided Calibration
Apr 19, 2025The surge in multimedia content has led to the development of Multi-Modal Recommender Systems (MMRecs), which use diverse modalities such as text, images, videos, and audio for more personalized recommendations. However, MMRecs struggle with noisy data caused by misalignment among modal content and the gap between modal semantics and recommendation semantics. Traditional denoising methods are inadequate due to the complexity of multi-modal data. To address this, we propose a universal guided in-sync distillation denoising framework for multi-modal recommendation (GUIDER), designed to improve MMRecs by denoising user feedback. Specifically, GUIDER uses a re-calibration strategy to identify clean and noisy interactions from modal content. It incorporates a Denoising Bayesian Personalized Ranking (DBPR) loss function to handle implicit user feedback. Finally, it applies a denoising knowledge distillation objective based on Optimal Transport distance to guide the alignment from modality representations to recommendation semantics. GUIDER can be seamlessly integrated into existing MMRecs methods as a plug-and-play solution. Experimental results on four public datasets demonstrate its effectiveness and generalizability. Our source code is available at https://github.com/Neon-Jing/Guider
CROSSAN: Towards Efficient and Effective Adaptation of Multiple Multimodal Foundation Models for Sequential Recommendation
Apr 14, 2025Multimodal Foundation Models (MFMs) excel at representing diverse raw modalities (e.g., text, images, audio, videos, etc.). As recommender systems increasingly incorporate these modalities, leveraging MFMs to generate better representations has great potential. However, their application in sequential recommendation remains largely unexplored. This is primarily because mainstream adaptation methods, such as Fine-Tuning and even Parameter-Efficient Fine-Tuning (PEFT) techniques (e.g., Adapter and LoRA), incur high computational costs, especially when integrating multiple modality encoders, thus hindering research progress. As a result, it remains unclear whether we can efficiently and effectively adapt multiple (>2) MFMs for the sequential recommendation task. To address this, we propose a plug-and-play Cross-modal Side Adapter Network (CROSSAN). Leveraging the fully decoupled side adapter-based paradigm, CROSSAN achieves high efficiency while enabling cross-modal learning across diverse modalities. To optimize the final stage of multimodal fusion across diverse modalities, we adopt the Mixture of Modality Expert Fusion (MOMEF) mechanism. CROSSAN achieves superior performance on the public datasets for adapting four foundation models with raw modalities. Performance consistently improves as more MFMs are adapted. We will release our code and datasets to facilitate future research.
Video-Bench: Human-Aligned Video Generation Benchmark
Apr 07, 2025



Video generation assessment is essential for ensuring that generative models produce visually realistic, high-quality videos while aligning with human expectations. Current video generation benchmarks fall into two main categories: traditional benchmarks, which use metrics and embeddings to evaluate generated video quality across multiple dimensions but often lack alignment with human judgments; and large language model (LLM)-based benchmarks, though capable of human-like reasoning, are constrained by a limited understanding of video quality metrics and cross-modal consistency. To address these challenges and establish a benchmark that better aligns with human preferences, this paper introduces Video-Bench, a comprehensive benchmark featuring a rich prompt suite and extensive evaluation dimensions. This benchmark represents the first attempt to systematically leverage MLLMs across all dimensions relevant to video generation assessment in generative models. By incorporating few-shot scoring and chain-of-query techniques, Video-Bench provides a structured, scalable approach to generated video evaluation. Experiments on advanced models including Sora demonstrate that Video-Bench achieves superior alignment with human preferences across all dimensions. Moreover, in instances where our framework's assessments diverge from human evaluations, it consistently offers more objective and accurate insights, suggesting an even greater potential advantage over traditional human judgment.
An Empirical Study of Training ID-Agnostic Multi-modal Sequential Recommenders
Mar 30, 2024
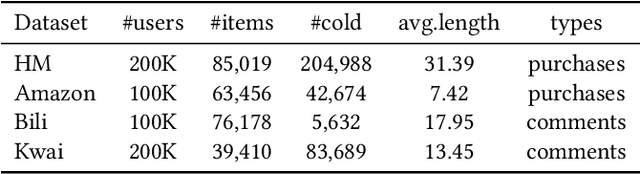

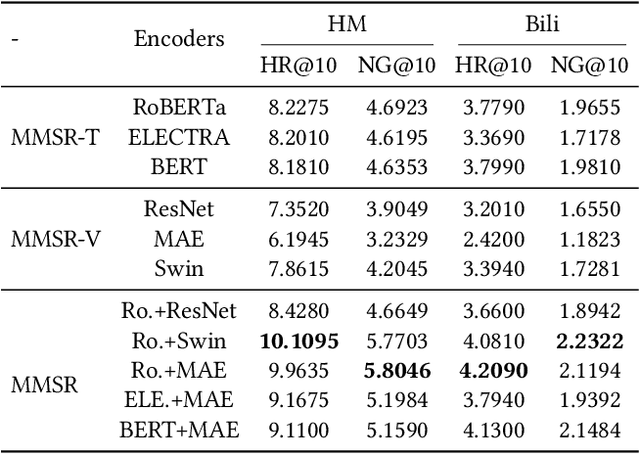
Sequential Recommendation (SR) aims to predict future user-item interactions based on historical interactions. While many SR approaches concentrate on user IDs and item IDs, the human perception of the world through multi-modal signals, like text and images, has inspired researchers to delve into constructing SR from multi-modal information without using IDs. However, the complexity of multi-modal learning manifests in diverse feature extractors, fusion methods, and pre-trained models. Consequently, designing a simple and universal \textbf{M}ulti-\textbf{M}odal \textbf{S}equential \textbf{R}ecommendation (\textbf{MMSR}) framework remains a formidable challenge. We systematically summarize the existing multi-modal related SR methods and distill the essence into four core components: visual encoder, text encoder, multimodal fusion module, and sequential architecture. Along these dimensions, we dissect the model designs, and answer the following sub-questions: First, we explore how to construct MMSR from scratch, ensuring its performance either on par with or exceeds existing SR methods without complex techniques. Second, we examine if MMSR can benefit from existing multi-modal pre-training paradigms. Third, we assess MMSR's capability in tackling common challenges like cold start and domain transferring. Our experiment results across four real-world recommendation scenarios demonstrate the great potential ID-agnostic multi-modal sequential recommendation. Our framework can be found at: https://github.com/MMSR23/MMSR.
Multi-Modality is All You Need for Transferable Recommender Systems
Dec 18, 2023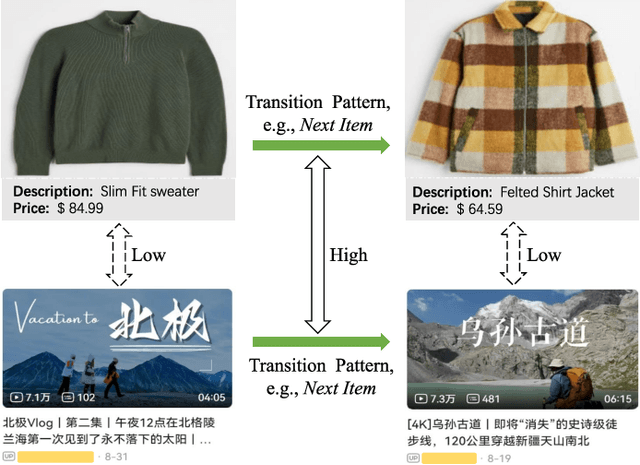
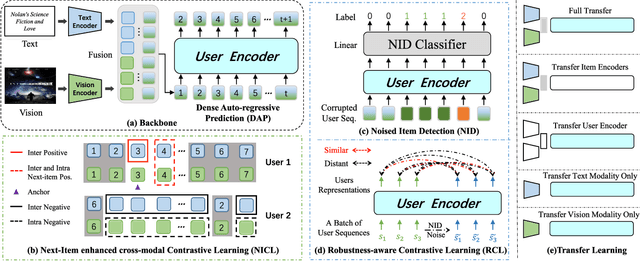
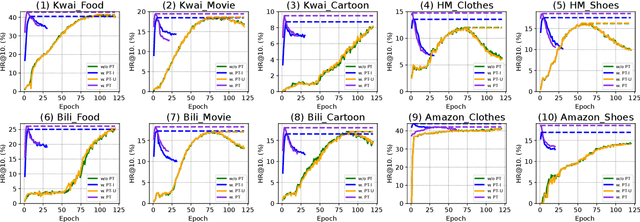
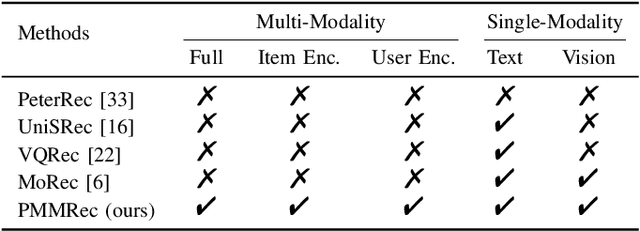
ID-based Recommender Systems (RecSys), where each item is assigned a unique identifier and subsequently converted into an embedding vector, have dominated the designing of RecSys. Though prevalent, such ID-based paradigm is not suitable for developing transferable RecSys and is also susceptible to the cold-start issue. In this paper, we unleash the boundaries of the ID-based paradigm and propose a Pure Multi-Modality based Recommender system (PMMRec), which relies solely on the multi-modal contents of the items (e.g., texts and images) and learns transition patterns general enough to transfer across domains and platforms. Specifically, we design a plug-and-play framework architecture consisting of multi-modal item encoders, a fusion module, and a user encoder. To align the cross-modal item representations, we propose a novel next-item enhanced cross-modal contrastive learning objective, which is equipped with both inter- and intra-modality negative samples and explicitly incorporates the transition patterns of user behaviors into the item encoders. To ensure the robustness of user representations, we propose a novel noised item detection objective and a robustness-aware contrastive learning objective, which work together to denoise user sequences in a self-supervised manner. PMMRec is designed to be loosely coupled, so after being pre-trained on the source data, each component can be transferred alone, or in conjunction with other components, allowing PMMRec to achieve versatility under both multi-modality and single-modality transfer learning settings. Extensive experiments on 4 sources and 10 target datasets demonstrate that PMMRec surpasses the state-of-the-art recommenders in both recommendation performance and transferability. Our code and dataset is available at: https://github.com/ICDE24/PMMRec.
A Content-Driven Micro-Video Recommendation Dataset at Scale
Sep 27, 2023



Micro-videos have recently gained immense popularity, sparking critical research in micro-video recommendation with significant implications for the entertainment, advertising, and e-commerce industries. However, the lack of large-scale public micro-video datasets poses a major challenge for developing effective recommender systems. To address this challenge, we introduce a very large micro-video recommendation dataset, named "MicroLens", consisting of one billion user-item interaction behaviors, 34 million users, and one million micro-videos. This dataset also contains various raw modality information about videos, including titles, cover images, audio, and full-length videos. MicroLens serves as a benchmark for content-driven micro-video recommendation, enabling researchers to utilize various modalities of video information for recommendation, rather than relying solely on item IDs or off-the-shelf video features extracted from a pre-trained network. Our benchmarking of multiple recommender models and video encoders on MicroLens has yielded valuable insights into the performance of micro-video recommendation. We believe that this dataset will not only benefit the recommender system community but also promote the development of the video understanding field. Our datasets and code are available at https://github.com/westlake-repl/MicroLens.
NineRec: A Benchmark Dataset Suite for Evaluating Transferable Recommendation
Sep 20, 2023



Learning a recommender system model from an item's raw modality features (such as image, text, audio, etc.), called MoRec, has attracted growing interest recently. One key advantage of MoRec is that it can easily benefit from advances in other fields, such as natural language processing (NLP) and computer vision (CV). Moreover, it naturally supports transfer learning across different systems through modality features, known as transferable recommender systems, or TransRec. However, so far, TransRec has made little progress, compared to groundbreaking foundation models in the fields of NLP and CV. The lack of large-scale, high-quality recommendation datasets poses a major obstacle. To this end, we introduce NineRec, a TransRec dataset suite that includes a large-scale source domain recommendation dataset and nine diverse target domain recommendation datasets. Each item in NineRec is represented by a text description and a high-resolution cover image. With NineRec, we can implement TransRec models in an end-to-end training manner instead of using pre-extracted invariant features. We conduct a benchmark study and empirical analysis of TransRec using NineRec, and our findings provide several valuable insights. To support further research, we make our code, datasets, benchmarks, and leaderboards publicly available at https://github.com/westlake-repl/NineRec.
Where to Go Next for Recommender Systems? ID- vs. Modality-based recommender models revisited
Mar 24, 2023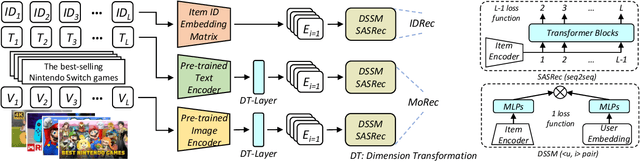


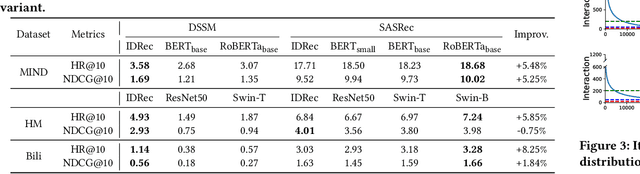
Recommendation models that utilize unique identities (IDs) to represent distinct users and items have been state-of-the-art (SOTA) and dominated the recommender systems (RS) literature for over a decade. Meanwhile, the pre-trained modality encoders, such as BERT and ViT, have become increasingly powerful in modeling the raw modality features of an item, such as text and images. Given this, a natural question arises: can a purely modality-based recommendation model (MoRec) outperforms or matches a pure ID-based model (IDRec) by replacing the itemID embedding with a SOTA modality encoder? In fact, this question was answered ten years ago when IDRec beats MoRec by a strong margin in both recommendation accuracy and efficiency. We aim to revisit this `old' question and systematically study MoRec from several aspects. Specifically, we study several sub-questions: (i) which recommendation paradigm, MoRec or IDRec, performs better in practical scenarios, especially in the general setting and warm item scenarios where IDRec has a strong advantage? does this hold for items with different modality features? (ii) can the latest technical advances from other communities (i.e., natural language processing and computer vision) translate into accuracy improvement for MoRec? (iii) how to effectively utilize item modality representation, can we use it directly or do we have to adjust it with new data? (iv) are there some key challenges for MoRec to be solved in practical applications? To answer them, we conduct rigorous experiments for item recommendations with two popular modalities, i.e., text and vision. We provide the first empirical evidence that MoRec is already comparable to its IDRec counterpart with an expensive end-to-end training method, even for warm item recommendation. Our results potentially imply that the dominance of IDRec in the RS field may be greatly challenged in the future.