 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Preprocessing-Driven Approach to Remaining Useful Life (RUL) Prediction Using Temporal Convolutional Networks (TCN)
May 04, 2026Accurate prediction of Remaining Useful Life (RUL) in aero-engines is vital for predictive maintenance, improved operational reliability, and reduced lifecycle costs. While deep learning approaches have demonstrated strong potential in this area, most existing methods focus primarily on model architecture design and treat input features uniformly, often neglecting the influence of data preprocessing. In this work, we propose a novel preprocessing pipeline that enhances RUL prediction by improving data quality and temporal representation before model training. Our approach leverages complete temporal sequences and generates RUL estimates at each timestep, enabling the model to capture fine-grained degradation dynamics and deliver continuous prognostic insights throughout the engine's operational life. To validate the effectiveness of the proposed pipeline, we conduct experiments on the NASA C-MAPSS dataset. Comparative evaluations against a suite of state-of-the-art neural models including CNN, RNN, LSTM, DCNN, TCN, BiGRU-TSAM, AGCNN, and ATCN, demonstrate that our approach consistently achieves superior accuracy and robustness in aero-engine RUL prediction. These results highlight the critical role of preprocessing in maximizing the effectiveness of neural prognostic models.
VRAG-DFD: Verifiable Retrieval-Augmentation for MLLM-based Deepfake Detection
Apr 16, 2026In Deepfake Detection (DFD) tasks, researchers proposed two types of MLLM-based methods: complementary combination with small DFD detectors, or static forgery knowledge injection.The lack of professional forgery knowledge hinders the performance of these DFD-MLLMs.To solve this, we deeply considered two insightful issues: How to provide high-quality associated forgery knowledge for MLLMs? AND How to endow MLLMs with critical reasoning abilities given noisy reference information? Notably, we attempted to address above two questions with preliminary answers by leveraging the combination of Retrieval-Augmented Generation (RAG) and Reinforcement Learning (RL).Through RAG and RL techniques, we propose the VRAG-DFD framework with accurate dynamic forgery knowledge retrieval and powerful critical reasoning capabilities.Specifically, in terms of data, we constructed two datasets with RAG: Forensic Knowledge Database (FKD) for DFD knowledge annotation, and Forensic Chain-of-Thought Dataset (F-CoT), for critical CoT construction.In terms of model training, we adopt a three-stage training method (Alignment->SFT->GRPO) to gradually cultivate the critical reasoning ability of the MLLM.In terms of performance, VRAG-DFD achieved SOTA and competitive performance on DFD generalization testing.
Can Understanding and Generation Truly Benefit Together -- or Just Coexist?
Sep 11, 2025



In this paper, we introduce an insightful paradigm through the Auto-Encoder lens-understanding as the encoder (I2T) that compresses images into text, and generation as the decoder (T2I) that reconstructs images from that text. Using reconstruction fidelity as the unified training objective, we enforce the coherent bidirectional information flow between the understanding and generation processes, bringing mutual gains. To implement this, we propose UAE, a novel framework for unified multimodal learning. We begin by pre-training the decoder with large-scale long-context image captions to capture fine-grained semantic and complex spatial relationships. We then propose Unified-GRPO via reinforcement learning (RL), which covers three stages: (1) A cold-start phase to gently initialize both encoder and decoder with a semantic reconstruction loss; (2) Generation for Understanding, where the encoder is trained to generate informative captions that maximize the decoder's reconstruction quality, enhancing its visual understanding; (3) Understanding for Generation, where the decoder is refined to reconstruct from these captions, forcing it to leverage every detail and improving its long-context instruction following and generation fidelity. For evaluation, we introduce Unified-Bench, the first benchmark tailored to assess the degree of unification of the UMMs. A surprising "aha moment" arises within the multimodal learning domain: as RL progresses, the encoder autonomously produces more descriptive captions, while the decoder simultaneously demonstrates a profound ability to understand these intricate descriptions, resulting in reconstructions of striking fidelity.
Video-Bench: Human-Aligned Video Generation Benchmark
Apr 07, 2025



Video generation assessment is essential for ensuring that generative models produce visually realistic, high-quality videos while aligning with human expectations. Current video generation benchmarks fall into two main categories: traditional benchmarks, which use metrics and embeddings to evaluate generated video quality across multiple dimensions but often lack alignment with human judgments; and large language model (LLM)-based benchmarks, though capable of human-like reasoning, are constrained by a limited understanding of video quality metrics and cross-modal consistency. To address these challenges and establish a benchmark that better aligns with human preferences, this paper introduces Video-Bench, a comprehensive benchmark featuring a rich prompt suite and extensive evaluation dimensions. This benchmark represents the first attempt to systematically leverage MLLMs across all dimensions relevant to video generation assessment in generative models. By incorporating few-shot scoring and chain-of-query techniques, Video-Bench provides a structured, scalable approach to generated video evaluation. Experiments on advanced models including Sora demonstrate that Video-Bench achieves superior alignment with human preferences across all dimensions. Moreover, in instances where our framework's assessments diverge from human evaluations, it consistently offers more objective and accurate insights, suggesting an even greater potential advantage over traditional human judgment.
Deep Learning-Based Detection for Marker Codes over Insertion and Deletion Channels
Jan 02, 2024Marker code is an effective coding scheme to protect data from insertions and deletions. It has potential applications in future storage systems, such as DNA storage and racetrack memory. When decoding marker codes, perfect channel state information (CSI), i.e., insertion and deletion probabilities, are required to detect insertion and deletion errors. Sometimes, the perfect CSI is not easy to obtain or the accurate channel model is unknown. Therefore, it is deserved to develop detecting algorithms for marker code without the knowledge of perfect CSI. In this paper, we propose two CSI-agnostic detecting algorithms for marker code based on deep learning. The first one is a model-driven deep learning method, which deep unfolds the original iterative detecting algorithm of marker code. In this method, CSI become weights in neural networks and these weights can be learned from training data. The second one is a data-driven method which is an end-to-end system based on the deep bidirectional gated recurrent unit network. Simulation results show that error performances of the proposed methods are significantly better than that of the original detection algorithm with CSI uncertainty. Furthermore, the proposed data-driven method exhibits better error performances than other methods for unknown channel models.
Hierarchical Contrastive Learning Enhanced Heterogeneous Graph Neural Network
Apr 24, 2023Heterogeneous graph neural networks (HGNNs) as an emerging technique have shown superior capacity of dealing with heterogeneous information network (HIN). However, most HGNNs follow a semi-supervised learning manner, which notably limits their wide use in reality since labels are usually scarce in real applications. Recently, contrastive learning, a self-supervised method, becomes one of the most exciting learning paradigms and shows great potential when there are no labels. In this paper, we study the problem of self-supervised HGNNs and propose a novel co-contrastive learning mechanism for HGNNs, named HeCo. Different from traditional contrastive learning which only focuses on contrasting positive and negative samples, HeCo employs cross-view contrastive mechanism. Specifically, two views of a HIN (network schema and meta-path views) are proposed to learn node embeddings, so as to capture both of local and high-order structures simultaneously. Then the cross-view contrastive learning, as well as a view mask mechanism, is proposed, which is able to extract the positive and negative embeddings from two views. This enables the two views to collaboratively supervise each other and finally learn high-level node embeddings. Moreover, to further boost the performance of HeCo, two additional methods are designed to generate harder negative samples with high quality. Besides the invariant factors, view-specific factors complementally provide the diverse structure information between different nodes, which also should be contained into the final embeddings. Therefore, we need to further explore each view independently and propose a modified model, called HeCo++. Specifically, HeCo++ conducts hierarchical contrastive learning, including cross-view and intra-view contrasts, which aims to enhance the mining of respective structures.
Self-supervised Heterogeneous Graph Neural Network with Co-contrastive Learning
May 19, 2021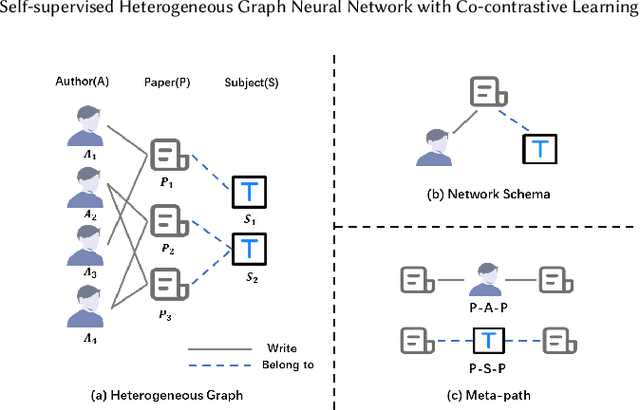
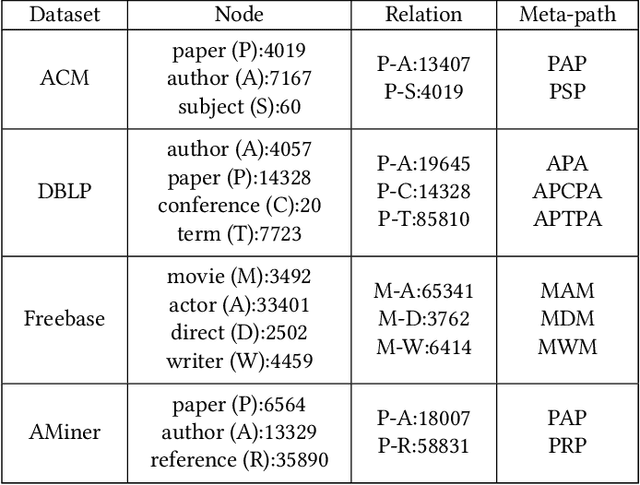
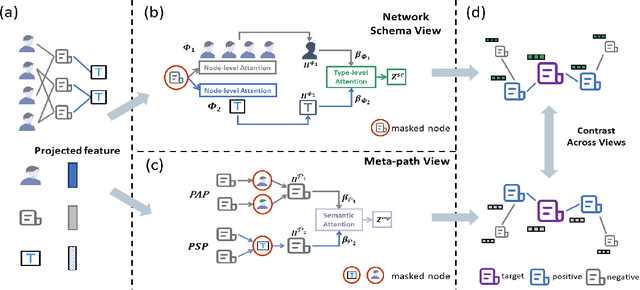
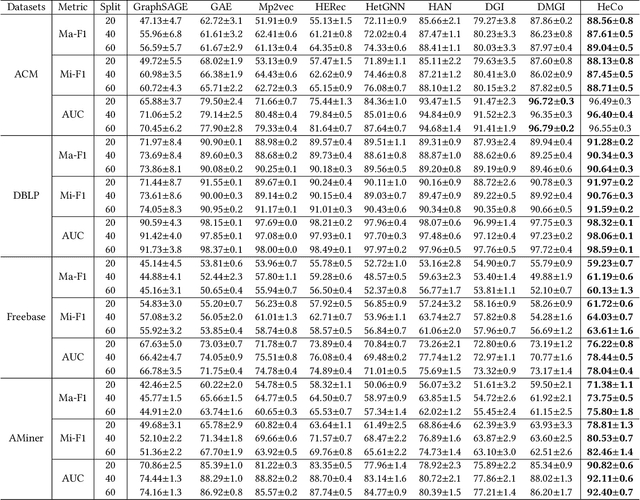
Heterogeneous graph neural networks (HGNNs) as an emerging technique have shown superior capacity of dealing with heterogeneous information network (HIN). However, most HGNNs follow a semi-supervised learning manner, which notably limits their wide use in reality since labels are usually scarce in real applications. Recently, contrastive learning, a self-supervised method, becomes one of the most exciting learning paradigms and shows great potential when there are no labels. In this paper, we study the problem of self-supervised HGNNs and propose a novel co-contrastive learning mechanism for HGNNs, named HeCo. Different from traditional contrastive learning which only focuses on contrasting positive and negative samples, HeCo employs cross-viewcontrastive mechanism. Specifically, two views of a HIN (network schema and meta-path views) are proposed to learn node embeddings, so as to capture both of local and high-order structures simultaneously. Then the cross-view contrastive learning, as well as a view mask mechanism, is proposed, which is able to extract the positive and negative embeddings from two views. This enables the two views to collaboratively supervise each other and finally learn high-level node embeddings. Moreover, two extensions of HeCo are designed to generate harder negative samples with high quality, which further boosts the performance of HeCo. Extensive experiments conducted on a variety of real-world networks show the superior performance of the proposed methods over the state-of-the-arts.