 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Training ID-Agnostic Multi-modal Sequential Recommenders
Mar 30, 2024
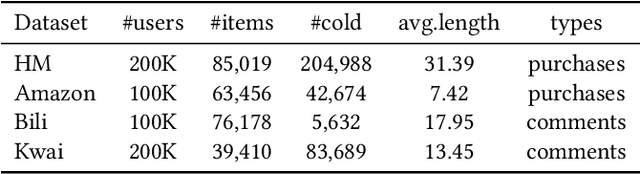

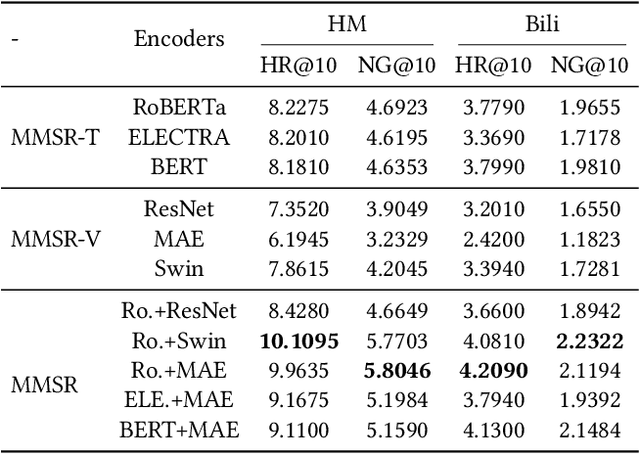
Sequential Recommendation (SR) aims to predict future user-item interactions based on historical interactions. While many SR approaches concentrate on user IDs and item IDs, the human perception of the world through multi-modal signals, like text and images, has inspired researchers to delve into constructing SR from multi-modal information without using IDs. However, the complexity of multi-modal learning manifests in diverse feature extractors, fusion methods, and pre-trained models. Consequently, designing a simple and universal \textbf{M}ulti-\textbf{M}odal \textbf{S}equential \textbf{R}ecommendation (\textbf{MMSR}) framework remains a formidable challenge. We systematically summarize the existing multi-modal related SR methods and distill the essence into four core components: visual encoder, text encoder, multimodal fusion module, and sequential architecture. Along these dimensions, we dissect the model designs, and answer the following sub-questions: First, we explore how to construct MMSR from scratch, ensuring its performance either on par with or exceeds existing SR methods without complex techniques. Second, we examine if MMSR can benefit from existing multi-modal pre-training paradigms. Third, we assess MMSR's capability in tackling common challenges like cold start and domain transferring. Our experiment results across four real-world recommendation scenarios demonstrate the great potential ID-agnostic multi-modal sequential recommendation. Our framework can be found at: https://github.com/MMSR23/MMSR.