 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Language Models Can Learn from Verbal Feedback Without Scalar Rewards
Sep 26, 2025
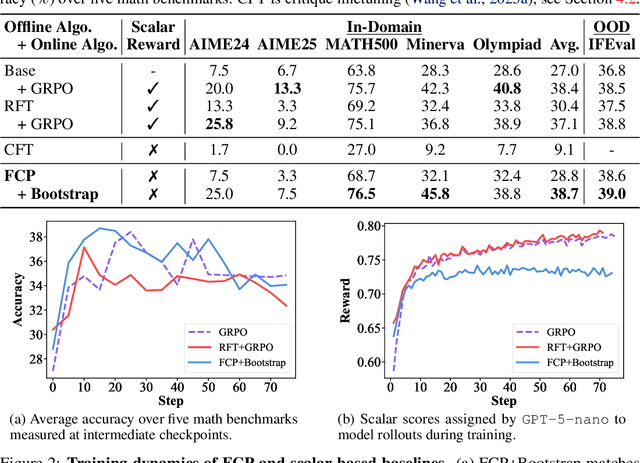
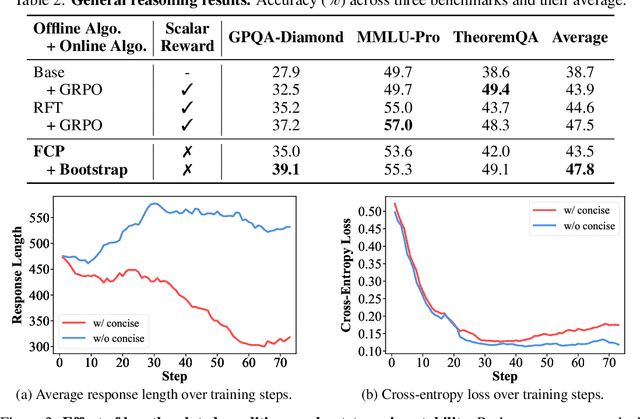
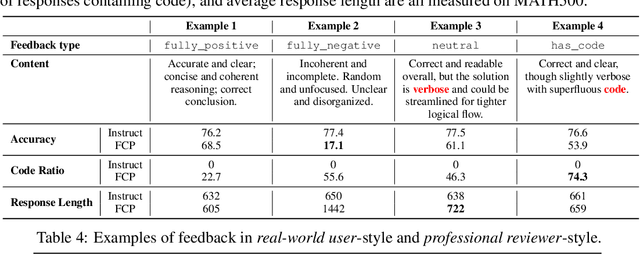
LLMs are often trained with RL from human or AI feedback, yet such methods typically compress nuanced feedback into scalar rewards, discarding much of their richness and inducing scale imbalance. We propose treating verbal feedback as a conditioning signal. Inspired by language priors in text-to-image generation, which enable novel outputs from unseen prompts, we introduce the feedback-conditional policy (FCP). FCP learns directly from response-feedback pairs, approximating the feedback-conditional posterior through maximum likelihood training on offline data. We further develop an online bootstrapping stage where the policy generates under positive conditions and receives fresh feedback to refine itself. This reframes feedback-driven learning as conditional generation rather than reward optimization, offering a more expressive way for LLMs to directly learn from verbal feedback. Our code is available at https://github.com/sail-sg/feedback-conditional-policy.
Fostering Video Reasoning via Next-Event Prediction
May 28, 2025
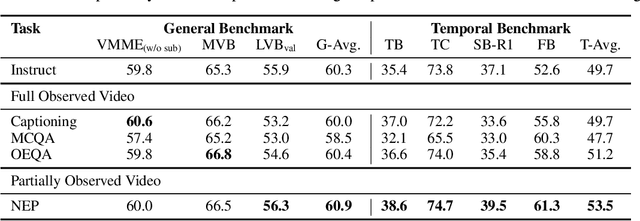
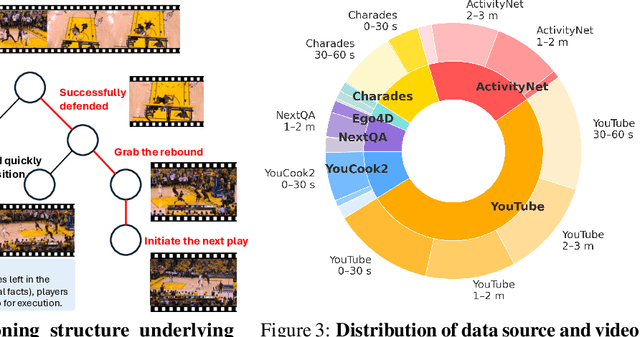
Next-token prediction serves as the foundational learning task enabling reasoning in LLMs. But what should the learning task be when aiming to equip MLLMs with temporal reasoning capabilities over video inputs? Existing tasks such as video question answering often rely on annotations from humans or much stronger MLLMs, while video captioning tends to entangle temporal reasoning with spatial information. To address this gap, we propose next-event prediction (NEP), a learning task that harnesses future video segments as a rich, self-supervised signal to foster temporal reasoning. We segment each video into past and future frames: the MLLM takes the past frames as input and predicts a summary of events derived from the future frames, thereby encouraging the model to reason temporally in order to complete the task. To support this task, we curate V1-33K, a dataset comprising 33,000 automatically extracted video segments spanning diverse real-world scenarios. We further explore a range of video instruction-tuning strategies to study their effects on temporal reasoning. To evaluate progress, we introduce FutureBench to assess coherence in predicting unseen future events. Experiments validate that NEP offers a scalable and effective training paradigm for fostering temporal reasoning in MLLMs.
NoisyRollout: Reinforcing Visual Reasoning with Data Augmentation
Apr 17, 2025Recent advances in reinforcement learning (RL) have strengthened the reasoning capabilities of vision-language models (VLMs). However, enhancing policy exploration to more effectively scale test-time compute remains underexplored in VLMs. In addition, VLMs continue to struggle with imperfect visual perception, which in turn affects the subsequent reasoning process. To this end, we propose NoisyRollout, a simple yet effective RL approach that mixes trajectories from both clean and moderately distorted images to introduce targeted diversity in visual perception and the resulting reasoning patterns. Without additional training cost, NoisyRollout enhances the exploration capabilities of VLMs by incorporating a vision-oriented inductive bias. Furthermore, NoisyRollout employs a noise annealing schedule that gradually reduces distortion strength over training, ensuring benefit from noisy signals early while maintaining training stability and scalability in later stages. With just 2.1K training samples, NoisyRollout achieves state-of-the-art performance among open-source RL-tuned models on 5 out-of-domain benchmarks spanning both reasoning and perception tasks, while preserving comparable or even better in-domain performance.
CodexGraph: Bridging Large Language Models and Code Repositories via Code Graph Databases
Aug 07, 2024



Large Language Models (LLMs) excel in stand-alone code tasks like HumanEval and MBPP, but struggle with handling entire code repositories. This challenge has prompted research on enhancing LLM-codebase interaction at a repository scale. Current solutions rely on similarity-based retrieval or manual tools and APIs, each with notable drawbacks. Similarity-based retrieval often has low recall in complex tasks, while manual tools and APIs are typically task-specific and require expert knowledge, reducing their generalizability across diverse code tasks and real-world applications. To mitigate these limitations, we introduce \framework, a system that integrates LLM agents with graph database interfaces extracted from code repositories. By leveraging the structural properties of graph databases and the flexibility of the graph query language, \framework enables the LLM agent to construct and execute queries, allowing for precise, code structure-aware context retrieval and code navigation. We assess \framework using three benchmarks: CrossCodeEval, SWE-bench, and EvoCodeBench. Additionally, we develop five real-world coding applications. With a unified graph database schema, \framework demonstrates competitive performance and potential in both academic and real-world environments, showcasing its versatility and efficacy in software engineering. Our application demo: https://github.com/modelscope/modelscope-agent/tree/master/apps/codexgraph_agent.
Described Spatial-Temporal Video Detection
Jul 08, 2024



Detecting visual content on language expression has become an emerging topic in the community. However, in the video domain, the existing setting, i.e., spatial-temporal video grounding (STVG), is formulated to only detect one pre-existing object in each frame, ignoring the fact that language descriptions can involve none or multiple entities within a video. In this work, we advance the STVG to a more practical setting called described spatial-temporal video detection (DSTVD) by overcoming the above limitation. To facilitate the exploration of DSTVD, we first introduce a new benchmark, namely DVD-ST. Notably, DVD-ST supports grounding from none to many objects onto the video in response to queries and encompasses a diverse range of over 150 entities, including appearance, actions, locations, and interactions. The extensive breadth and diversity of the DVD-ST dataset make it an exemplary testbed for the investigation of DSTVD. In addition to the new benchmark, we further present two baseline methods for our proposed DSTVD task by extending two representative STVG models, i.e., TubeDETR, and STCAT. These extended models capitalize on tubelet queries to localize and track referred objects across the video sequence. Besides, we adjust the training objectives of these models to optimize spatial and temporal localization accuracy and multi-class classification capabilities. Furthermore, we benchmark the baselines on the introduced DVD-ST dataset and conduct extensive experimental analysis to guide future investigation. Our code and benchmark will be publicly available.
An Empirical Study of Training ID-Agnostic Multi-modal Sequential Recommenders
Mar 30, 2024
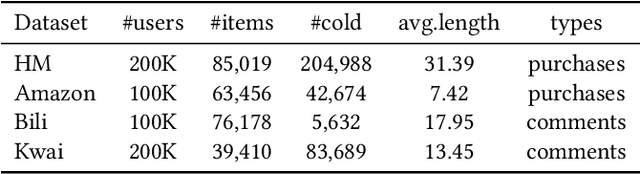

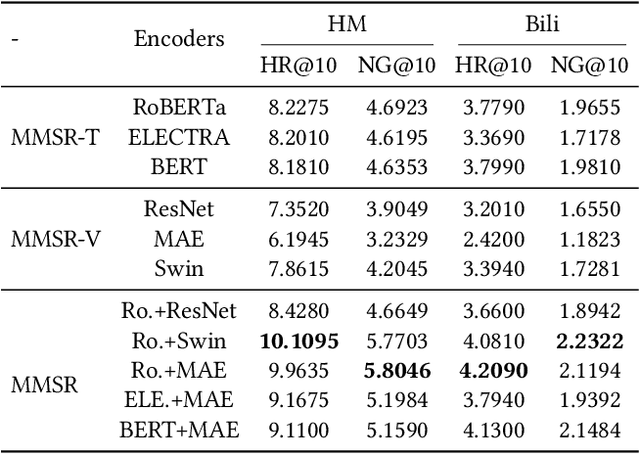
Sequential Recommendation (SR) aims to predict future user-item interactions based on historical interactions. While many SR approaches concentrate on user IDs and item IDs, the human perception of the world through multi-modal signals, like text and images, has inspired researchers to delve into constructing SR from multi-modal information without using IDs. However, the complexity of multi-modal learning manifests in diverse feature extractors, fusion methods, and pre-trained models. Consequently, designing a simple and universal \textbf{M}ulti-\textbf{M}odal \textbf{S}equential \textbf{R}ecommendation (\textbf{MMSR}) framework remains a formidable challenge. We systematically summarize the existing multi-modal related SR methods and distill the essence into four core components: visual encoder, text encoder, multimodal fusion module, and sequential architecture. Along these dimensions, we dissect the model designs, and answer the following sub-questions: First, we explore how to construct MMSR from scratch, ensuring its performance either on par with or exceeds existing SR methods without complex techniques. Second, we examine if MMSR can benefit from existing multi-modal pre-training paradigms. Third, we assess MMSR's capability in tackling common challenges like cold start and domain transferring. Our experiment results across four real-world recommendation scenarios demonstrate the great potential ID-agnostic multi-modal sequential recommendation. Our framework can be found at: https://github.com/MMSR23/MMSR.
Towards Robust Multi-Modal Reasoning via Model Selection
Oct 12, 2023The reasoning capabilities of LLM (Large Language Model) are widely acknowledged in recent research, inspiring studies on tool learning and autonomous agents. LLM serves as the "brain" of agent, orchestrating multiple tools for collaborative multi-step task solving. Unlike methods invoking tools like calculators or weather APIs for straightforward tasks, multi-modal agents excel by integrating diverse AI models for complex challenges. However, current multi-modal agents neglect the significance of model selection: they primarily focus on the planning and execution phases, and will only invoke predefined task-specific models for each subtask, making the execution fragile. Meanwhile, other traditional model selection methods are either incompatible with or suboptimal for the multi-modal agent scenarios, due to ignorance of dependencies among subtasks arising by multi-step reasoning. To this end, we identify the key challenges therein and propose the $\textit{M}^3$ framework as a plug-in with negligible runtime overhead at test-time. This framework improves model selection and bolsters the robustness of multi-modal agents in multi-step reasoning. In the absence of suitable benchmarks, we create MS-GQA, a new dataset specifically designed to investigate the model selection challenge in multi-modal agents. Our experiments reveal that our framework enables dynamic model selection, considering both user inputs and subtask dependencies, thereby robustifying the overall reasoning process. Our code and benchmark: https://github.com/LINs-lab/M3.
Towards Complex-query Referring Image Segmentation: A Novel Benchmark
Sep 29, 2023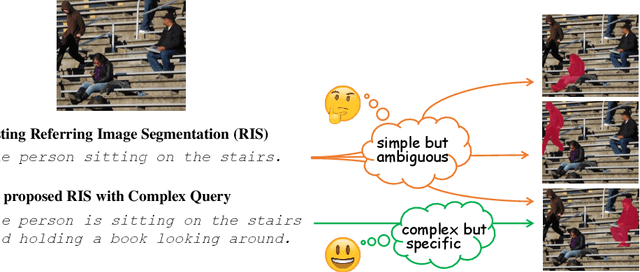
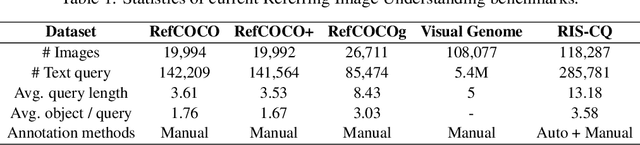

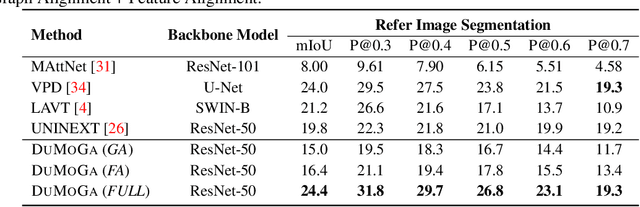
Referring Image Understanding (RIS) has been extensively studied over the past decade, leading to the development of advanced algorithms. However, there has been a lack of research investigating how existing algorithms should be benchmarked with complex language queries, which include more informative descriptions of surrounding objects and backgrounds (\eg \textit{"the black car."} vs. \textit{"the black car is parking on the road and beside the bus."}). Given the significant improvement in the semantic understanding capability of large pre-trained models, it is crucial to take a step further in RIS by incorporating complex language that resembles real-world applications. To close this gap, building upon the existing RefCOCO and Visual Genome datasets, we propose a new RIS benchmark with complex queries, namely \textbf{RIS-CQ}. The RIS-CQ dataset is of high quality and large scale, which challenges the existing RIS with enriched, specific and informative queries, and enables a more realistic scenario of RIS research. Besides, we present a nichetargeting method to better task the RIS-CQ, called dual-modality graph alignment model (\textbf{\textsc{DuMoGa}}), which outperforms a series of RIS methods.
A Content-Driven Micro-Video Recommendation Dataset at Scale
Sep 27, 2023



Micro-videos have recently gained immense popularity, sparking critical research in micro-video recommendation with significant implications for the entertainment, advertising, and e-commerce industries. However, the lack of large-scale public micro-video datasets poses a major challenge for developing effective recommender systems. To address this challenge, we introduce a very large micro-video recommendation dataset, named "MicroLens", consisting of one billion user-item interaction behaviors, 34 million users, and one million micro-videos. This dataset also contains various raw modality information about videos, including titles, cover images, audio, and full-length videos. MicroLens serves as a benchmark for content-driven micro-video recommendation, enabling researchers to utilize various modalities of video information for recommendation, rather than relying solely on item IDs or off-the-shelf video features extracted from a pre-trained network. Our benchmarking of multiple recommender models and video encoders on MicroLens has yielded valuable insights into the performance of micro-video recommendation. We believe that this dataset will not only benefit the recommender system community but also promote the development of the video understanding field. Our datasets and code are available at https://github.com/westlake-repl/MicroLens.