 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTissue-Contrastive Semi-Masked Autoencoders for Segmentation Pretraining on Chest CT
Jul 12, 2024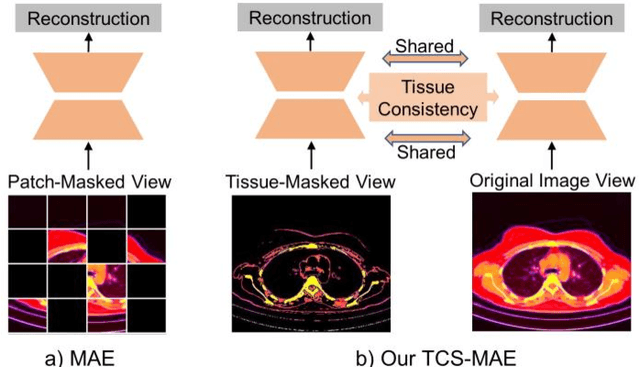
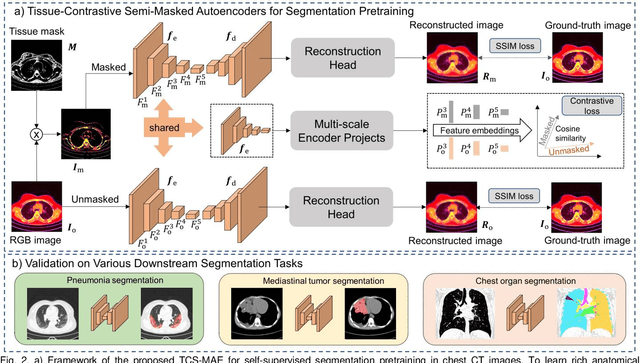
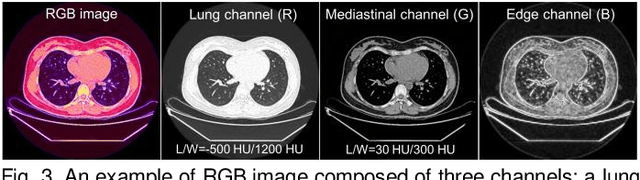
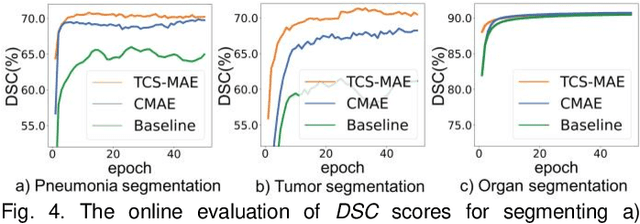
Existing Masked Image Modeling (MIM) depends on a spatial patch-based masking-reconstruction strategy to perceive objects'features from unlabeled images, which may face two limitations when applied to chest CT: 1) inefficient feature learning due to complex anatomical details presented in CT images, and 2) suboptimal knowledge transfer owing to input disparity between upstream and downstream models. To address these issues, we propose a new MIM method named Tissue-Contrastive Semi-Masked Autoencoder (TCS-MAE) for modeling chest CT images. Our method has two novel designs: 1) a tissue-based masking-reconstruction strategy to capture more fine-grained anatomical features, and 2) a dual-AE architecture with contrastive learning between the masked and original image views to bridge the gap of the upstream and downstream models. To validate our method, we systematically investigate representative contrastive, generative, and hybrid self-supervised learning methods on top of tasks involving segmenting pneumonia, mediastinal tumors, and various organs. The results demonstrate that, compared to existing methods, our TCS-MAE more effectively learns tissue-aware representations, thereby significantly enhancing segmentation performance across all tasks.
Described Spatial-Temporal Video Detection
Jul 08, 2024



Detecting visual content on language expression has become an emerging topic in the community. However, in the video domain, the existing setting, i.e., spatial-temporal video grounding (STVG), is formulated to only detect one pre-existing object in each frame, ignoring the fact that language descriptions can involve none or multiple entities within a video. In this work, we advance the STVG to a more practical setting called described spatial-temporal video detection (DSTVD) by overcoming the above limitation. To facilitate the exploration of DSTVD, we first introduce a new benchmark, namely DVD-ST. Notably, DVD-ST supports grounding from none to many objects onto the video in response to queries and encompasses a diverse range of over 150 entities, including appearance, actions, locations, and interactions. The extensive breadth and diversity of the DVD-ST dataset make it an exemplary testbed for the investigation of DSTVD. In addition to the new benchmark, we further present two baseline methods for our proposed DSTVD task by extending two representative STVG models, i.e., TubeDETR, and STCAT. These extended models capitalize on tubelet queries to localize and track referred objects across the video sequence. Besides, we adjust the training objectives of these models to optimize spatial and temporal localization accuracy and multi-class classification capabilities. Furthermore, we benchmark the baselines on the introduced DVD-ST dataset and conduct extensive experimental analysis to guide future investigation. Our code and benchmark will be publicly available.
Soften to Defend: Towards Adversarial Robustness via Self-Guided Label Refinement
Mar 14, 2024Adversarial training (AT) is currently one of the most effective ways to obtain the robustness of deep neural networks against adversarial attacks. However, most AT methods suffer from robust overfitting, i.e., a significant generalization gap in adversarial robustness between the training and testing curves. In this paper, we first identify a connection between robust overfitting and the excessive memorization of noisy labels in AT from a view of gradient norm. As such label noise is mainly caused by a distribution mismatch and improper label assignments, we are motivated to propose a label refinement approach for AT. Specifically, our Self-Guided Label Refinement first self-refines a more accurate and informative label distribution from over-confident hard labels, and then it calibrates the training by dynamically incorporating knowledge from self-distilled models into the current model and thus requiring no external teachers. Empirical results demonstrate that our method can simultaneously boost the standard accuracy and robust performance across multiple benchmark datasets, attack types, and architectures. In addition, we also provide a set of analyses from the perspectives of information theory to dive into our method and suggest the importance of soft labels for robust generalization.
Skeleton-Guided Instance Separation for Fine-Grained Segmentation in Microscopy
Jan 19, 2024



One of the fundamental challenges in microscopy (MS) image analysis is instance segmentation (IS), particularly when segmenting cluster regions where multiple objects of varying sizes and shapes may be connected or even overlapped in arbitrary orientations. Existing IS methods usually fail in handling such scenarios, as they rely on coarse instance representations such as keypoints and horizontal bounding boxes (h-bboxes). In this paper, we propose a novel one-stage framework named A2B-IS to address this challenge and enhance the accuracy of IS in MS images. Our approach represents each instance with a pixel-level mask map and a rotated bounding box (r-bbox). Unlike two-stage methods that use box proposals for segmentations, our method decouples mask and box predictions, enabling simultaneous processing to streamline the model pipeline. Additionally, we introduce a Gaussian skeleton map to aid the IS task in two key ways: (1) It guides anchor placement, reducing computational costs while improving the model's capacity to learn RoI-aware features by filtering out noise from background regions. (2) It ensures accurate isolation of densely packed instances by rectifying erroneous box predictions near instance boundaries. To further enhance the performance, we integrate two modules into the framework: (1) An Atrous Attention Block (A2B) designed to extract high-resolution feature maps with fine-grained multiscale information, and (2) A Semi-Supervised Learning (SSL) strategy that leverages both labeled and unlabeled images for model training. Our method has been thoroughly validated on two large-scale MS datasets, demonstrating its superiority over most state-of-the-art approaches.
Panoptic Scene Graph Generation with Semantics-prototype Learning
Jul 28, 2023Panoptic Scene Graph Generation (PSG) parses objects and predicts their relationships (predicate) to connect human language and visual scenes. However, different language preferences of annotators and semantic overlaps between predicates lead to biased predicate annotations in the dataset, i.e. different predicates for same object pairs. Biased predicate annotations make PSG models struggle in constructing a clear decision plane among predicates, which greatly hinders the real application of PSG models. To address the intrinsic bias above, we propose a novel framework named ADTrans to adaptively transfer biased predicate annotations to informative and unified ones. To promise consistency and accuracy during the transfer process, we propose to measure the invariance of representations in each predicate class, and learn unbiased prototypes of predicates with different intensities. Meanwhile, we continuously measure the distribution changes between each presentation and its prototype, and constantly screen potential biased data. Finally, with the unbiased predicate-prototype representation embedding space, biased annotations are easily identified. Experiments show that ADTrans significantly improves the performance of benchmark models, achieving a new state-of-the-art performance, and shows great generalization and effectiveness on multiple datasets.
Group-wise Deep Co-saliency Detection
Jul 25, 2017



In this paper, we propose an end-to-end group-wise deep co-saliency detection approach to address the co-salient object discovery problem based on the fully convolutional network (FCN) with group input and group output. The proposed approach captures the group-wise interaction information for group images by learning a semantics-aware image representation based on a convolutional neural network, which adaptively learns the group-wise features for co-saliency detection. Furthermore, the proposed approach discovers the collaborative and interactive relationships between group-wise feature representation and single-image individual feature representation, and model this in a collaborative learning framework. Finally, we set up a unified end-to-end deep learning scheme to jointly optimize the process of group-wise feature representation learning and the collaborative learning, leading to more reliable and robust co-saliency detection results. Experimental results demonstrate the effectiveness of our approach in comparison with the state-of-the-art approaches.
Graph-Theoretic Spatiotemporal Context Modeling for Video Saliency Detection
Jul 25, 2017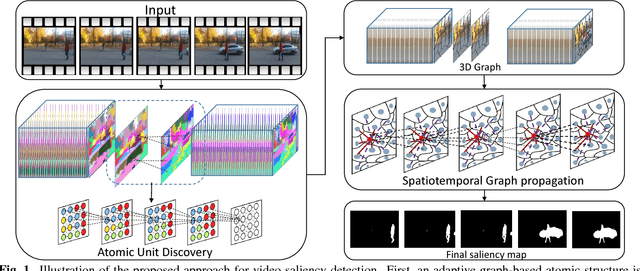
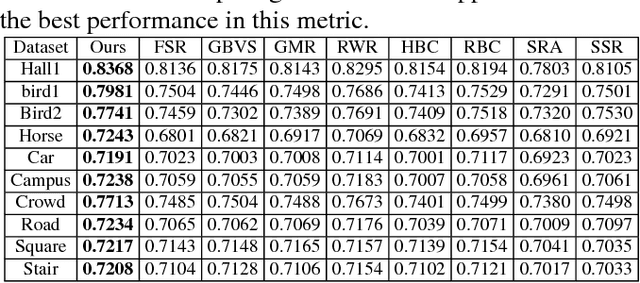
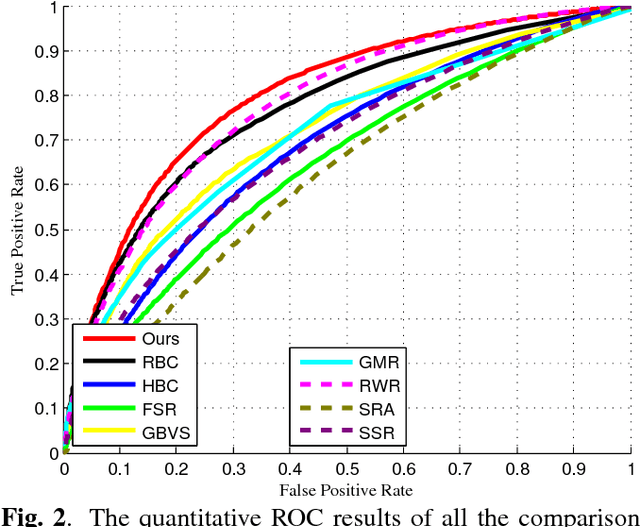
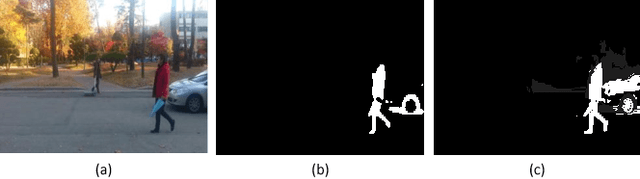
As an important and challenging problem in computer vision, video saliency detection is typically cast as a spatiotemporal context modeling problem over consecutive frames. As a result, a key issue in video saliency detection is how to effectively capture the intrinsical properties of atomic video structures as well as their associated contextual interactions along the spatial and temporal dimensions. Motivated by this observation, we propose a graph-theoretic video saliency detection approach based on adaptive video structure discovery, which is carried out within a spatiotemporal atomic graph. Through graph-based manifold propagation, the proposed approach is capable of effectively modeling the semantically contextual interactions among atomic video structures for saliency detection while preserving spatial smoothness and temporal consistency. Experiments demonstrate the effectiveness of the proposed approach over several benchmark datasets.
DeepSaliency: Multi-Task Deep Neural Network Model for Salient Object Detection
Jun 07, 2016



A key problem in salient object detection is how to effectively model the semantic properties of salient objects in a data-driven manner. In this paper, we propose a multi-task deep saliency model based on a fully convolutional neural network (FCNN) with global input (whole raw images) and global output (whole saliency maps). In principle, the proposed saliency model takes a data-driven strategy for encoding the underlying saliency prior information, and then sets up a multi-task learning scheme for exploring the intrinsic correlations between saliency detection and semantic image segmentation. Through collaborative feature learning from such two correlated tasks, the shared fully convolutional layers produce effective features for object perception. Moreover, it is capable of capturing the semantic information on salient objects across different levels using the fully convolutional layers, which investigate the feature-sharing properties of salient object detection with great feature redundancy reduction. Finally, we present a graph Laplacian regularized nonlinear regression model for saliency refinement. Experimental results demonstrate the effectiveness of our approach in comparison with the state-of-the-art approaches.