 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Theoretic Spatiotemporal Context Modeling for Video Saliency Detection
Paper and Code
Jul 25, 2017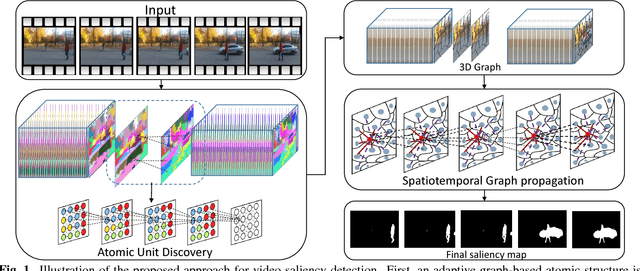
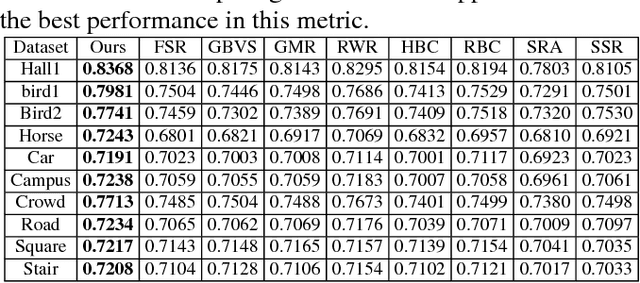
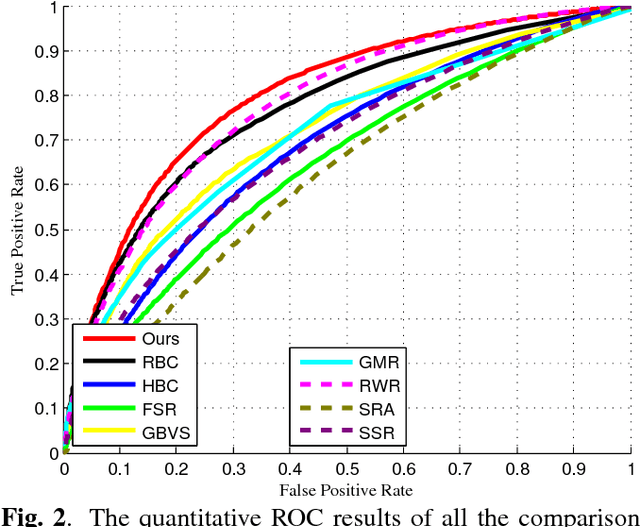
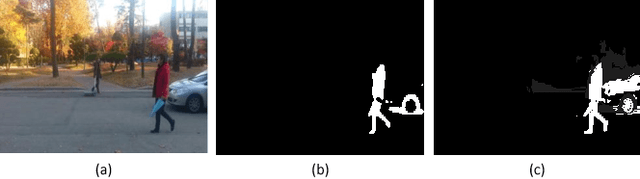
As an important and challenging problem in computer vision, video saliency detection is typically cast as a spatiotemporal context modeling problem over consecutive frames. As a result, a key issue in video saliency detection is how to effectively capture the intrinsical properties of atomic video structures as well as their associated contextual interactions along the spatial and temporal dimensions. Motivated by this observation, we propose a graph-theoretic video saliency detection approach based on adaptive video structure discovery, which is carried out within a spatiotemporal atomic graph. Through graph-based manifold propagation, the proposed approach is capable of effectively modeling the semantically contextual interactions among atomic video structures for saliency detection while preserving spatial smoothness and temporal consistency. Experiments demonstrate the effectiveness of the proposed approach over several benchmark datasets.