 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTissue-Contrastive Semi-Masked Autoencoders for Segmentation Pretraining on Chest CT
Jul 12, 2024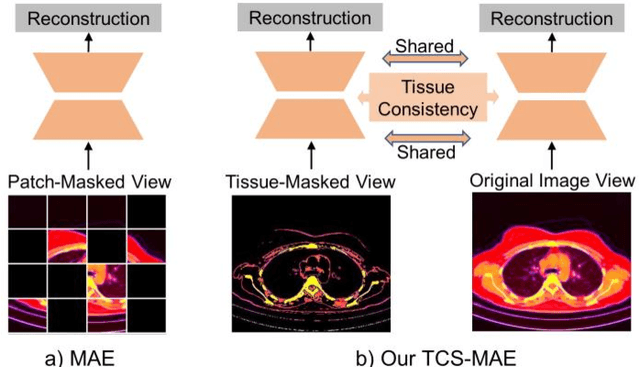
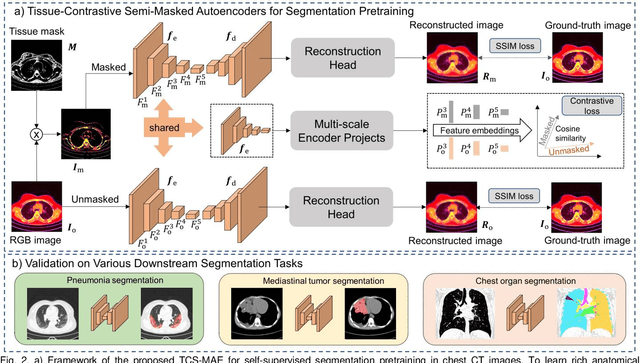
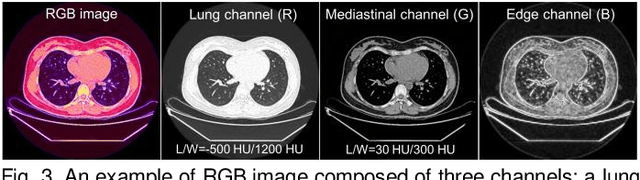
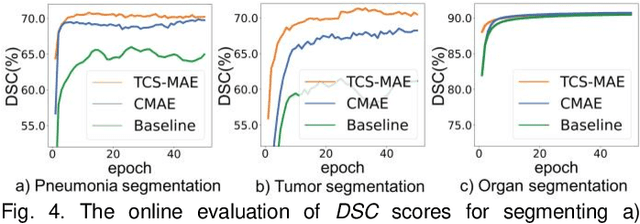
Existing Masked Image Modeling (MIM) depends on a spatial patch-based masking-reconstruction strategy to perceive objects'features from unlabeled images, which may face two limitations when applied to chest CT: 1) inefficient feature learning due to complex anatomical details presented in CT images, and 2) suboptimal knowledge transfer owing to input disparity between upstream and downstream models. To address these issues, we propose a new MIM method named Tissue-Contrastive Semi-Masked Autoencoder (TCS-MAE) for modeling chest CT images. Our method has two novel designs: 1) a tissue-based masking-reconstruction strategy to capture more fine-grained anatomical features, and 2) a dual-AE architecture with contrastive learning between the masked and original image views to bridge the gap of the upstream and downstream models. To validate our method, we systematically investigate representative contrastive, generative, and hybrid self-supervised learning methods on top of tasks involving segmenting pneumonia, mediastinal tumors, and various organs. The results demonstrate that, compared to existing methods, our TCS-MAE more effectively learns tissue-aware representations, thereby significantly enhancing segmentation performance across all tasks.
A Hierarchical Dataflow-Driven Heterogeneous Architecture for Wireless Baseband Processing
Feb 28, 2024Wireless baseband processing (WBP) is a key element of wireless communications, with a series of signal processing modules to improve data throughput and counter channel fading. Conventional hardware solutions, such as digital signal processors (DSPs) and more recently, graphic processing units (GPUs), provide various degrees of parallelism, yet they both fail to take into account the cyclical and consecutive character of WBP. Furthermore, the large amount of data in WBPs cannot be processed quickly in symmetric multiprocessors (SMPs) due to the unpredictability of memory latency. To address this issue, we propose a hierarchical dataflow-driven architecture to accelerate WBP. A pack-and-ship approach is presented under a non-uniform memory access (NUMA) architecture to allow the subordinate tiles to operate in a bundled access and execute manner. We also propose a multi-level dataflow model and the related scheduling scheme to manage and allocate the heterogeneous hardware resources. Experiment results demonstrate that our prototype achieves $2\times$ and $2.3\times$ speedup in terms of normalized throughput and single-tile clock cycles compared with GPU and DSP counterparts in several critical WBP benchmarks. Additionally, a link-level throughput of $288$ Mbps can be achieved with a $45$-core configuration.