 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoPass: Evidence-Guided LLM Agents for Compiler Performance Tuning
Jun 18, 2026Large Language Models (LLMs) show promise for code compilation tasks, but applying them to runtime performance tuning is difficult due to complex microarchitectural effects and noisy runtime measurements. We present AutoPass, a multi-agent framework for compiler performance tuning that uses compiler and runtime evidence to guide LLM-generated optimization decisions. Rather than treating the compiler as a black box like prior auto-tuning schemes, AutoPass opens up the compiler to the LLM, enabling it to query compiler-internal optimization states and analyze the intermediate representation to orchestrate compiler options. The search process iteratively refines optimization configurations using measured runtime feedback to diagnose regressions and guide latency-improving edits. AutoPass operates in an inference-only, training-free setting and requires no offline training or task-specific fine-tuning, making it readily applicable to new benchmarks and platforms. We implement AutoPass on the LLVM compiler and evaluate it on server-grade x86-64 and embedded ARM64 systems. AutoPass outperforms expert-tuned heuristics and classical autotuning methods, achieving geometric-mean speedups of 1.043x and 1.117x over LLVM -O3 on x86-64 and ARM64, respectively.
CosFly: Plan in the Matrix, Fly in the World
May 18, 2026We present CosFly, a box-structured planning and multimodal simulation pipeline for aerial tracking, together with CosFly-Track, a large-scale UAV dataset for dynamic target tracking across diverse environments including urban centers, highways, rural landscapes, forests, and coastal towns. In our current implementation on CARLA, CosFly provides a modular 7-step construction pipeline that converts complex 3D worlds into structured obstacle representations for planning, then projects the resulting trajectories back into multi-modal sensor data -- including RGB images, high-precision depth maps, and semantic segmentation masks -- paired with natural language navigation instructions. A key feature is the support for configurable fixed-FOV zoom levels (one FOV setting drawn per trajectory and held constant throughout), enabling simulation of various focal lengths through camera-intrinsic adjustments. The pipeline covers the complete workflow from 3D map export through grid simplification, pedestrian and drone trajectory planning, multi-modal rendering with 6-DOF pose annotations, quality inspection, and teacher-student caption generation. We analyze two trajectory-planning paradigms for aerial target tracking: a conventional two-stage pipeline with front-end candidate generation and backend refinement, and a direct gradient-based formulation that optimizes multiple tracking constraints in a single objective. The public CosFly-Track release contains 250 validated trajectories and approximately 100,000 rendered images with complete 6-DOF drone pose annotations (position x, y, z and orientation yaw, pitch, roll). Together, the pipeline and dataset establish a scalable foundation for aerial-ground collaborative research, supporting dynamic target tracking, UAV navigation, and multi-modal perception across diverse environments.
Vision-and-Language Navigation for UAVs: Progress, Challenges, and a Research Roadmap
Apr 15, 2026Vision-and-Language Navigation for Unmanned Aerial Vehicles (UAV-VLN) represents a pivotal challenge in embodied artificial intelligence, focused on enabling UAVs to interpret high-level human commands and execute long-horizon tasks in complex 3D environments. This paper provides a comprehensive and structured survey of the field, from its formal task definition to the current state of the art. We establish a methodological taxonomy that charts the technological evolution from early modular and deep learning approaches to contemporary agentic systems driven by large foundation models, including Vision-Language Models (VLMs), Vision-Language-Action (VLA) models, and the emerging integration of generative world models with VLA architectures for physically-grounded reasoning. The survey systematically reviews the ecosystem of essential resources simulators, datasets, and evaluation metrics that facilitates standardized research. Furthermore, we conduct a critical analysis of the primary challenges impeding real-world deployment: the simulation-to-reality gap, robust perception in dynamic outdoor settings, reasoning with linguistic ambiguity, and the efficient deployment of large models on resource-constrained hardware. By synthesizing current benchmarks and limitations, this survey concludes by proposing a forward-looking research roadmap to guide future inquiry into key frontiers such as multi-agent swarm coordination and air-ground collaborative robotics.
Density-aware Soft Context Compression with Semi-Dynamic Compression Ratio
Mar 26, 2026Soft context compression reduces the computational workload of processing long contexts in LLMs by encoding long context into a smaller number of latent tokens. However, existing frameworks apply uniform compression ratios, failing to account for the extreme variance in natural language information density. While adopting a density-aware dynamic compression ratio seems intuitive, empirical investigations reveal that models struggle intrinsically with operations parameterized by input dependent, continuous structural hyperparameters. To resolve this pitfall, we introduce Semi-Dynamic Context Compression framework. Our approach features a Discrete Ratio Selector, which predicts a compression target based on intrinsic information density and quantizes it to a predefined set of discrete compression ratios. It is efficiently jointly trained with the compressor on synthetic data, with the summary lengths as a proxy to create labels for compression ratio prediction. Extensive evaluations confirm that our density-aware framework, utilizing mean pooling as the backbone, consistently outperforms static baselines, establishing a robust Pareto frontier for context compression techniques. Our code, data and model weights are available at https://github.com/yuyijiong/semi-dynamic-context-compress
From Digital Twins to World Models:Opportunities, Challenges, and Applications for Mobile Edge General Intelligence
Mar 18, 2026The rapid evolution toward 6G and beyond communication systems is accelerating the convergence of digital twins and world models at the network edge. Traditional digital twins provide high-fidelity representations of physical systems and support monitoring, analysis, and offline optimization. However, in highly dynamic edge environments, they face limitations in autonomy, adaptability, and scalability. This paper presents a systematic survey of the transition from digital twins to world models and discusses its role in enabling edge general intelligence (EGI). First, the paper clarifies the conceptual differences between digital twins and world models and highlights the shift from physics-based, centralized, and system-centric replicas to data-driven, decentralized, and agent-centric internal models. This discussion helps readers gain a clear understanding of how this transition enables more adaptive, autonomous, and resource-efficient intelligence at the network edge. The paper reviews the design principles, architectures, and key components of world models, including perception, latent state representation, dynamics learning, imagination-based planning, and memory. In addition, it examines the integration of world models and digital twins in wireless EGI systems and surveys emerging applications in integrated sensing and communications, semantic communication, air-ground networks, and low-altitude wireless networks. Finally, this survey provides a systematic roadmap and practical insights for designing world-model-driven edge intelligence systems in wireless and edge computing environments. It also outlines key research challenges and future directions toward scalable, reliable, and interoperable world models for edge-native agentic AI.
Artificial Superintelligence May be Useless: Equilibria in the Economy of Multiple AI Agents
Mar 01, 2026With recent development of artificial intelligence, it is more common to adopt AI agents in economic activities. This paper explores the economic actions of agents, including human agents and AI agents, in an economic game of trading products/services, and the equilibria in this economy involving multiple agents. We derive a range of equilibrium results and their corresponding conditions using a Markov chain stationary distribution based model. One distinct feature of our model is that we consider the long-term utility generated by economic activities instead of their short-term benefits. For the model consisting of two agents, we fully characterize all the possible economic equilibria and conditions. Interestingly, we show that unless each agent can at least double (not merely increase) its marginal utility by purchasing the other agent's products/services, purchasing the other agent's products/services will not happen in any economic equilibrium. We further extend our results to three and more agents, where we characterize more economic equilibria. We find that in some equilibria, the ``more powerful'' AI agents contribute zero utility to ``less capable'' agents.
CellVTA: Enhancing Vision Foundation Models for Accurate Cell Segmentation and Classification
Apr 01, 2025
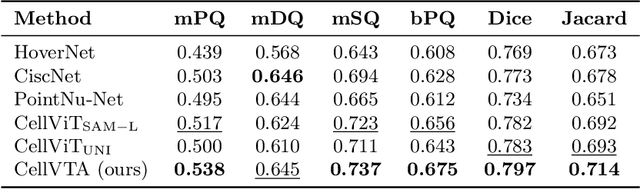


Cell instance segmentation is a fundamental task in digital pathology with broad clinical applications. Recently, vision foundation models, which are predominantly based on Vision Transformers (ViTs), have achieved remarkable success in pathology image analysis. However, their improvements in cell instance segmentation remain limited. A key challenge arises from the tokenization process in ViTs, which substantially reduces the spatial resolution of input images, leading to suboptimal segmentation quality, especially for small and densely packed cells. To address this problem, we propose CellVTA (Cell Vision Transformer with Adapter), a novel method that improves the performance of vision foundation models for cell instance segmentation by incorporating a CNN-based adapter module. This adapter extracts high-resolution spatial information from input images and injects it into the ViT through a cross-attention mechanism. Our method preserves the core architecture of ViT, ensuring seamless integration with pretrained foundation models. Extensive experiments show that CellVTA achieves 0.538 mPQ on the CoNIC dataset and 0.506 mPQ on the PanNuke dataset, which significantly outperforms the state-of-the-art cell segmentation methods. Ablation studies confirm the superiority of our approach over other fine-tuning strategies, including decoder-only fine-tuning and full fine-tuning. Our code and models are publicly available at https://github.com/JieZheng-ShanghaiTech/CellVTA.
Interpretable High-order Knowledge Graph Neural Network for Predicting Synthetic Lethality in Human Cancers
Mar 08, 2025Synthetic lethality (SL) is a promising gene interaction for cancer therapy. Recent SL prediction methods integrate knowledge graphs (KGs) into graph neural networks (GNNs) and employ attention mechanisms to extract local subgraphs as explanations for target gene pairs. However, attention mechanisms often lack fidelity, typically generate a single explanation per gene pair, and fail to ensure trustworthy high-order structures in their explanations. To overcome these limitations, we propose Diverse Graph Information Bottleneck for Synthetic Lethality (DGIB4SL), a KG-based GNN that generates multiple faithful explanations for the same gene pair and effectively encodes high-order structures. Specifically, we introduce a novel DGIB objective, integrating a Determinant Point Process (DPP) constraint into the standard IB objective, and employ 13 motif-based adjacency matrices to capture high-order structures in gene representations. Experimental results show that DGIB4SL outperforms state-of-the-art baselines and provides multiple explanations for SL prediction, revealing diverse biological mechanisms underlying SL inference.
StarWhisper Telescope: Agent-Based Observation Assistant System to Approach AI Astrophysicist
Dec 09, 2024



With the rapid advancements in Large Language Models (LLMs), LLM-based agents have introduced convenient and user-friendly methods for leveraging tools across various domains. In the field of astronomical observation, the construction of new telescopes has significantly increased astronomers' workload. Deploying LLM-powered agents can effectively alleviate this burden and reduce the costs associated with training personnel. Within the Nearby Galaxy Supernovae Survey (NGSS) project, which encompasses eight telescopes across three observation sites, aiming to find the transients from the galaxies in 50 mpc, we have developed the \textbf{StarWhisper Telescope System} to manage the entire observation process. This system automates tasks such as generating observation lists, conducting observations, analyzing data, and providing feedback to the observer. Observation lists are customized for different sites and strategies to ensure comprehensive coverage of celestial objects. After manual verification, these lists are uploaded to the telescopes via the agents in the system, which initiates observations upon neutral language. The observed images are analyzed in real-time, and the transients are promptly communicated to the observer. The agent modifies them into a real-time follow-up observation proposal and send to the Xinglong observatory group chat, then add them to the next-day observation lists. Additionally, the integration of AI agents within the system provides online accessibility, saving astronomers' time and encouraging greater participation from amateur astronomers in the NGSS project.
Tissue-Contrastive Semi-Masked Autoencoders for Segmentation Pretraining on Chest CT
Jul 12, 2024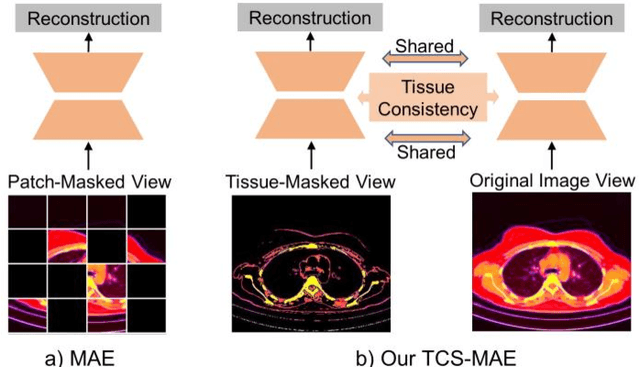
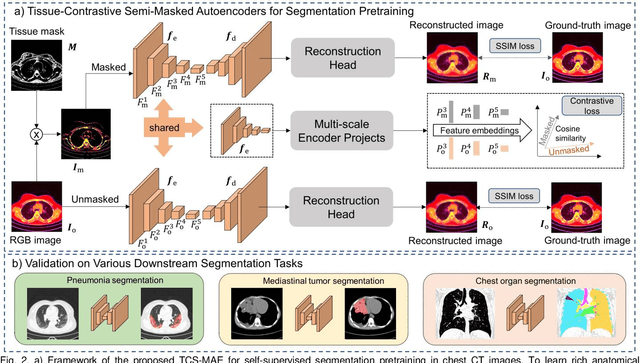
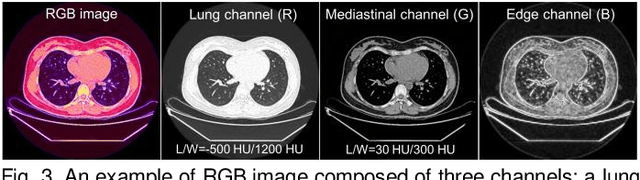
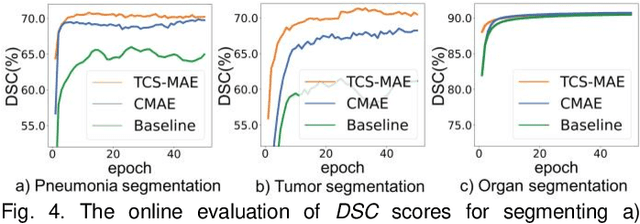
Existing Masked Image Modeling (MIM) depends on a spatial patch-based masking-reconstruction strategy to perceive objects'features from unlabeled images, which may face two limitations when applied to chest CT: 1) inefficient feature learning due to complex anatomical details presented in CT images, and 2) suboptimal knowledge transfer owing to input disparity between upstream and downstream models. To address these issues, we propose a new MIM method named Tissue-Contrastive Semi-Masked Autoencoder (TCS-MAE) for modeling chest CT images. Our method has two novel designs: 1) a tissue-based masking-reconstruction strategy to capture more fine-grained anatomical features, and 2) a dual-AE architecture with contrastive learning between the masked and original image views to bridge the gap of the upstream and downstream models. To validate our method, we systematically investigate representative contrastive, generative, and hybrid self-supervised learning methods on top of tasks involving segmenting pneumonia, mediastinal tumors, and various organs. The results demonstrate that, compared to existing methods, our TCS-MAE more effectively learns tissue-aware representations, thereby significantly enhancing segmentation performance across all tasks.