 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCredentials in the Occupation Ontology
Apr 30, 2024



The term credential encompasses educational certificates, degrees, certifications, and government-issued licenses. An occupational credential is a verification of an individuals qualification or competence issued by a third party with relevant authority. Job seekers often leverage such credentials as evidence that desired qualifications are satisfied by their holders. Many U.S. education and workforce development organizations have recognized the importance of credentials for employment and the challenges of understanding the value of credentials. In this study, we identified and ontologically defined credential and credential-related terms at the textual and semantic levels based on the Occupation Ontology (OccO), a BFO-based ontology. Different credential types and their authorization logic are modeled. We additionally defined a high-level hierarchy of credential related terms and relations among many terms, which were initiated in concert with the Alabama Talent Triad (ATT) program, which aims to connect learners, earners, employers and education/training providers through credentials and skills. To our knowledge, our research provides for the first time systematic ontological modeling of the important domain of credentials and related contents, supporting enhanced credential data and knowledge integration in the future.
Clinical Concept and Relation Extraction Using Prompt-based Machine Reading Comprehension
Mar 14, 2023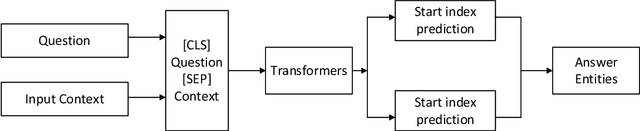



Objective: To develop a natural language processing system that solves both clinical concept extraction and relation extraction in a unified prompt-based machine reading comprehension (MRC) architecture with good generalizability for cross-institution applications. Methods: We formulate both clinical concept extraction and relation extraction using a unified prompt-based MRC architecture and explore state-of-the-art transformer models. We compare our MRC models with existing deep learning models for concept extraction and end-to-end relation extraction using two benchmark datasets developed by the 2018 National NLP Clinical Challenges (n2c2) challenge (medications and adverse drug events) and the 2022 n2c2 challenge (relations of social determinants of health [SDoH]). We also evaluate the transfer learning ability of the proposed MRC models in a cross-institution setting. We perform error analyses and examine how different prompting strategies affect the performance of MRC models. Results and Conclusion: The proposed MRC models achieve state-of-the-art performance for clinical concept and relation extraction on the two benchmark datasets, outperforming previous non-MRC transformer models. GatorTron-MRC achieves the best strict and lenient F1-scores for concept extraction, outperforming previous deep learning models on the two datasets by 1%~3% and 0.7%~1.3%, respectively. For end-to-end relation extraction, GatorTron-MRC and BERT-MIMIC-MRC achieve the best F1-scores, outperforming previous deep learning models by 0.9%~2.4% and 10%-11%, respectively. For cross-institution evaluation, GatorTron-MRC outperforms traditional GatorTron by 6.4% and 16% for the two datasets, respectively. The proposed method is better at handling nested/overlapped concepts, extracting relations, and has good portability for cross-institute applications.
SODA: A Natural Language Processing Package to Extract Social Determinants of Health for Cancer Studies
Dec 06, 2022



Objective: We aim to develop an open-source natural language processing (NLP) package, SODA (i.e., SOcial DeterminAnts), with pre-trained transformer models to extract social determinants of health (SDoH) for cancer patients, examine the generalizability of SODA to a new disease domain (i.e., opioid use), and evaluate the extraction rate of SDoH using cancer populations. Methods: We identified SDoH categories and attributes and developed an SDoH corpus using clinical notes from a general cancer cohort. We compared four transformer-based NLP models to extract SDoH, examined the generalizability of NLP models to a cohort of patients prescribed with opioids, and explored customization strategies to improve performance. We applied the best NLP model to extract 19 categories of SDoH from the breast (n=7,971), lung (n=11,804), and colorectal cancer (n=6,240) cohorts. Results and Conclusion: We developed a corpus of 629 cancer patients notes with annotations of 13,193 SDoH concepts/attributes from 19 categories of SDoH. The Bidirectional Encoder Representations from Transformers (BERT) model achieved the best strict/lenient F1 scores of 0.9216 and 0.9441 for SDoH concept extraction, 0.9617 and 0.9626 for linking attributes to SDoH concepts. Fine-tuning the NLP models using new annotations from opioid use patients improved the strict/lenient F1 scores from 0.8172/0.8502 to 0.8312/0.8679. The extraction rates among 19 categories of SDoH varied greatly, where 10 SDoH could be extracted from >70% of cancer patients, but 9 SDoH had a low extraction rate (<70% of cancer patients). The SODA package with pre-trained transformer models is publicly available at https://github.com/uf-hobiinformatics-lab/SDoH_SODA.
A Study of Social and Behavioral Determinants of Health in Lung Cancer Patients Using Transformers-based Natural Language Processing Models
Aug 10, 2021



Social and behavioral determinants of health (SBDoH) have important roles in shaping people's health. In clinical research studies, especially comparative effectiveness studies, failure to adjust for SBDoH factors will potentially cause confounding issues and misclassification errors in either statistical analyses and machine learning-based models. However, there are limited studies to examine SBDoH factors in clinical outcomes due to the lack of structured SBDoH information in current electronic health record (EHR) systems, while much of the SBDoH information is documented in clinical narratives. Natural language processing (NLP) is thus the key technology to extract such information from unstructured clinical text. However, there is not a mature clinical NLP system focusing on SBDoH. In this study, we examined two state-of-the-art transformer-based NLP models, including BERT and RoBERTa, to extract SBDoH concepts from clinical narratives, applied the best performing model to extract SBDoH concepts on a lung cancer screening patient cohort, and examined the difference of SBDoH information between NLP extracted results and structured EHRs (SBDoH information captured in standard vocabularies such as the International Classification of Diseases codes). The experimental results show that the BERT-based NLP model achieved the best strict/lenient F1-score of 0.8791 and 0.8999, respectively. The comparison between NLP extracted SBDoH information and structured EHRs in the lung cancer patient cohort of 864 patients with 161,933 various types of clinical notes showed that much more detailed information about smoking, education, and employment were only captured in clinical narratives and that it is necessary to use both clinical narratives and structured EHRs to construct a more complete picture of patients' SBDoH factors.
Identifying Cancer Patients at Risk for Heart Failure Using Machine Learning Methods
Oct 01, 2019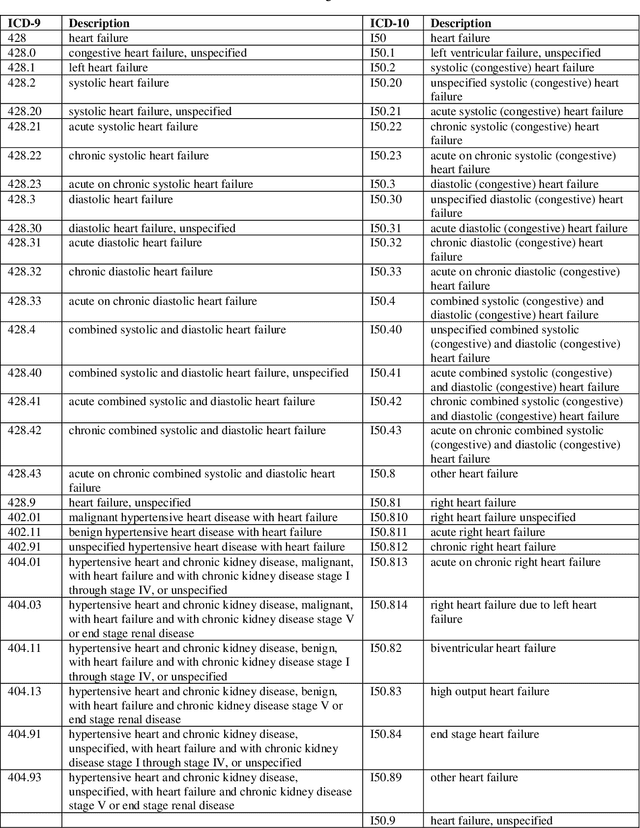

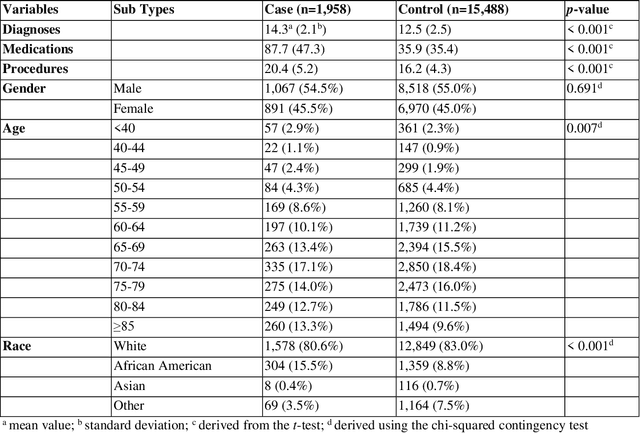

Cardiotoxicity related to cancer therapies has become a serious issue, diminishing cancer treatment outcomes and quality of life. Early detection of cancer patients at risk for cardiotoxicity before cardiotoxic treatments and providing preventive measures are potential solutions to improve cancer patients's quality of life. This study focuses on predicting the development of heart failure in cancer patients after cancer diagnoses using historical electronic health record (EHR) data. We examined four machine learning algorithms using 143,199 cancer patients from the University of Florida Health (UF Health) Integrated Data Repository (IDR). We identified a total number of 1,958 qualified cases and matched them to 15,488 controls by gender, age, race, and major cancer type. Two feature encoding strategies were compared to encode variables as machine learning features. The gradient boosting (GB) based model achieved the best AUC score of 0.9077 (with a sensitivity of 0.8520 and a specificity of 0.8138), outperforming other machine learning methods. We also looked into the subgroup of cancer patients with exposure to chemotherapy drugs and observed a lower specificity score (0.7089). The experimental results show that machine learning methods are able to capture clinical factors that are known to be associated with heart failure and that it is feasible to use machine learning methods to identify cancer patients at risk for cancer therapy-related heart failure.