 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Impact of Negative Samples of Contrastive Learning: A Case Study of Sentence Embedding
Paper and Code


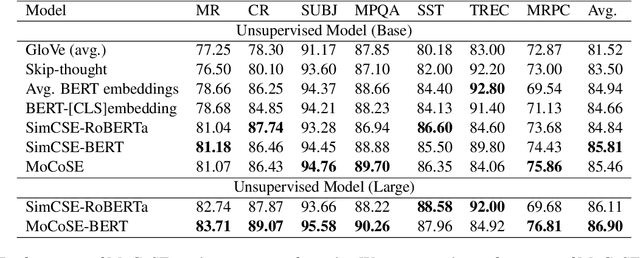
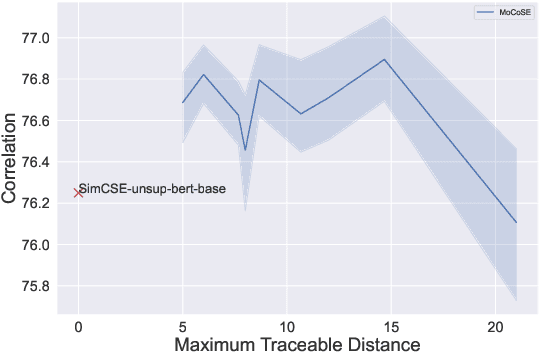
Contrastive learning is emerging as a powerful technique for extracting knowledge from unlabeled data. This technique requires a balanced mixture of two ingredients: positive (similar) and negative (dissimilar) samples. This is typically achieved by maintaining a queue of negative samples during training. Prior works in the area typically uses a fixed-length negative sample queue, but how the negative sample size affects the model performance remains unclear. The opaque impact of the number of negative samples on performance when employing contrastive learning aroused our in-depth exploration. This paper presents a momentum contrastive learning model with negative sample queue for sentence embedding, namely MoCoSE. We add the prediction layer to the online branch to make the model asymmetric and together with EMA update mechanism of the target branch to prevent the model from collapsing. We define a maximum traceable distance metric, through which we learn to what extent the text contrastive learning benefits from the historical information of negative samples. Our experiments find that the best results are obtained when the maximum traceable distance is at a certain range, demonstrating that there is an optimal range of historical information for a negative sample queue. We evaluate the proposed unsupervised MoCoSE on the semantic text similarity (STS) task and obtain an average Spearman's correlation of $77.27\%$. Source code is available at https://github.com/xbdxwyh/mocose.