 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePetroBench: A Benchmark for Large Language Models in Petroleum Engineering
May 27, 2026Large Language Models are increasingly applied in the petroleum industry, highlighting the need for a domain-specific evaluation framework. This study develops a benchmark for LLMs in petroleum engineering, including a three-stage process of data preprocessing, quality filtering, and multi-model validation. Using expert review, a standardized question bank with strong domain relevance and discriminative capability was constructed. The benchmark covers production, reservoir, and drilling engineering, with 1,200 questions across multiple-choice, true or false, term definition, and short-answer formats. Eight mainstream LLMs were evaluated under a unified API environment. Results show that models performed better on subjective than objective questions, indicating weaknesses in factual knowledge discrimination. The highest accuracies for multiple-choice and true or false questions were 65.3% and 74.3%, respectively. Gemini-3-Pro, Kimi-K2.5, and Claude-Opus-4.6-Thinking achieved the best overall scores of 72%-74%. Models performed best in production engineering and weakest in reservoir engineering. Chinese models showed advantages in multiple-choice questions, while international models performed slightly better in short-answer questions. The benchmark provides a reproducible and practical reference for evaluating and deploying LLMs in petroleum engineering.
Feature Perturbation Pool-based Fusion Network for Unified Multi-Class Industrial Defect Detection
Apr 21, 2026Multi-class defect detection constitutes a critical yet challenging task in industrial quality inspection, where existing approaches typically suffer from two fundamental limitations: (i) the necessity of training separate models for each defect category, resulting in substantial computational and memory overhead, and (ii) degraded robustness caused by inter-class feature perturbation when heterogeneous defect categories are jointly modeled. In this paper, we present FPFNet, a Feature Perturbation Pool-based Fusion Network that synergistically integrates a stochastic feature perturbation pool with a multi-layer feature fusion strategy to address these challenges within a unified detection framework. The feature perturbation pool enriches the training distribution by randomly injecting diverse noise patterns -- including Gaussian noise, F-Noise, and F-Drop -- into the extracted feature representations, thereby strengthening the model's robustness against domain shifts and unseen defect morphologies. Concurrently, the multi-layer feature fusion module aggregates hierarchical feature representations from both the encoder and decoder through residual connections and normalization, enabling the network to capture complex cross-scale relationships while preserving fine-grained spatial details essential for precise defect localization. Built upon the UniAD architecture~\cite{you2022unified}, our method achieves state-of-the-art performance on two widely adopted benchmarks: 97.17\% image-level AUROC and 96.93\% pixel-level AUROC on MVTec-AD, and 91.08\% image-level AUROC and 99.08\% pixel-level AUROC on VisA, surpassing existing methods by notable margins while introducing no additional learnable parameters or computational complexity.
AutoScape: Geometry-Consistent Long-Horizon Scene Generation
Oct 23, 2025This paper proposes AutoScape, a long-horizon driving scene generation framework. At its core is a novel RGB-D diffusion model that iteratively generates sparse, geometrically consistent keyframes, serving as reliable anchors for the scene's appearance and geometry. To maintain long-range geometric consistency, the model 1) jointly handles image and depth in a shared latent space, 2) explicitly conditions on the existing scene geometry (i.e., rendered point clouds) from previously generated keyframes, and 3) steers the sampling process with a warp-consistent guidance. Given high-quality RGB-D keyframes, a video diffusion model then interpolates between them to produce dense and coherent video frames. AutoScape generates realistic and geometrically consistent driving videos of over 20 seconds, improving the long-horizon FID and FVD scores over the prior state-of-the-art by 48.6\% and 43.0\%, respectively.
From Intuition to Understanding: Using AI Peers to Overcome Physics Misconceptions
Apr 01, 2025Generative AI has the potential to transform personalization and accessibility of education. However, it raises serious concerns about accuracy and helping students become independent critical thinkers. In this study, we designed a helpful AI "Peer" to help students correct fundamental physics misconceptions related to Newtonian mechanic concepts. In contrast to approaches that seek near-perfect accuracy to create an authoritative AI tutor or teacher, we directly inform students that this AI can answer up to 40% of questions incorrectly. In a randomized controlled trial with 165 students, those who engaged in targeted dialogue with the AI Peer achieved post-test scores that were, on average, 10.5 percentage points higher - with over 20 percentage points higher normalized gain - than a control group that discussed physics history. Qualitative feedback indicated that 91% of the treatment group's AI interactions were rated as helpful. Furthermore, by comparing student performance on pre- and post-test questions about the same concept, along with experts' annotations of the AI interactions, we find initial evidence suggesting the improvement in performance does not depend on the correctness of the AI. With further research, the AI Peer paradigm described here could open new possibilities for how we learn, adapt to, and grow with AI.
Incremental Object Keypoint Learning
Mar 26, 2025Existing progress in object keypoint estimation primarily benefits from the conventional supervised learning paradigm based on numerous data labeled with pre-defined keypoints. However, these well-trained models can hardly detect the undefined new keypoints in test time, which largely hinders their feasibility for diverse downstream tasks. To handle this, various solutions are explored but still suffer from either limited generalizability or transferability. Therefore, in this paper, we explore a novel keypoint learning paradigm in that we only annotate new keypoints in the new data and incrementally train the model, without retaining any old data, called Incremental object Keypoint Learning (IKL). A two-stage learning scheme as a novel baseline tailored to IKL is developed. In the first Knowledge Association stage, given the data labeled with only new keypoints, an auxiliary KA-Net is trained to automatically associate the old keypoints to these new ones based on their spatial and intrinsic anatomical relations. In the second Mutual Promotion stage, based on a keypoint-oriented spatial distillation loss, we jointly leverage the auxiliary KA-Net and the old model for knowledge consolidation to mutually promote the estimation of all old and new keypoints. Owing to the investigation of the correlations between new and old keypoints, our proposed method can not just effectively mitigate the catastrophic forgetting of old keypoints, but may even further improve the estimation of the old ones and achieve a positive transfer beyond anti-forgetting. Such an observation has been solidly verified by extensive experiments on different keypoint datasets, where our method exhibits superiority in alleviating the forgetting issue and boosting performance while enjoying labeling efficiency even under the low-shot data regime.
Where do Large Vision-Language Models Look at when Answering Questions?
Mar 18, 2025Large Vision-Language Models (LVLMs) have shown promising performance in vision-language understanding and reasoning tasks. However, their visual understanding behaviors remain underexplored. A fundamental question arises: to what extent do LVLMs rely on visual input, and which image regions contribute to their responses? It is non-trivial to interpret the free-form generation of LVLMs due to their complicated visual architecture (e.g., multiple encoders and multi-resolution) and variable-length outputs. In this paper, we extend existing heatmap visualization methods (e.g., iGOS++) to support LVLMs for open-ended visual question answering. We propose a method to select visually relevant tokens that reflect the relevance between generated answers and input image. Furthermore, we conduct a comprehensive analysis of state-of-the-art LVLMs on benchmarks designed to require visual information to answer. Our findings offer several insights into LVLM behavior, including the relationship between focus region and answer correctness, differences in visual attention across architectures, and the impact of LLM scale on visual understanding. The code and data are available at https://github.com/bytedance/LVLM_Interpretation.
StarWhisper Telescope: Agent-Based Observation Assistant System to Approach AI Astrophysicist
Dec 09, 2024



With the rapid advancements in Large Language Models (LLMs), LLM-based agents have introduced convenient and user-friendly methods for leveraging tools across various domains. In the field of astronomical observation, the construction of new telescopes has significantly increased astronomers' workload. Deploying LLM-powered agents can effectively alleviate this burden and reduce the costs associated with training personnel. Within the Nearby Galaxy Supernovae Survey (NGSS) project, which encompasses eight telescopes across three observation sites, aiming to find the transients from the galaxies in 50 mpc, we have developed the \textbf{StarWhisper Telescope System} to manage the entire observation process. This system automates tasks such as generating observation lists, conducting observations, analyzing data, and providing feedback to the observer. Observation lists are customized for different sites and strategies to ensure comprehensive coverage of celestial objects. After manual verification, these lists are uploaded to the telescopes via the agents in the system, which initiates observations upon neutral language. The observed images are analyzed in real-time, and the transients are promptly communicated to the observer. The agent modifies them into a real-time follow-up observation proposal and send to the Xinglong observatory group chat, then add them to the next-day observation lists. Additionally, the integration of AI agents within the system provides online accessibility, saving astronomers' time and encouraging greater participation from amateur astronomers in the NGSS project.
FedVAE: Trajectory privacy preserving based on Federated Variational AutoEncoder
Jul 12, 2024

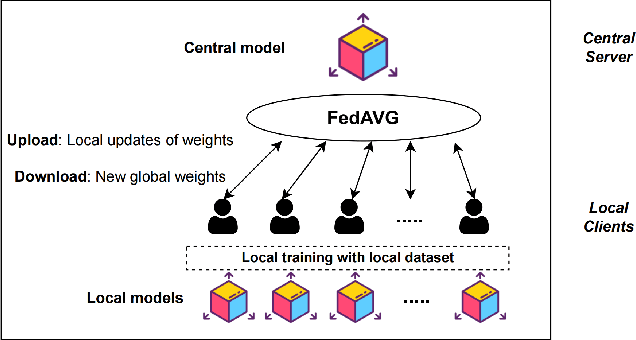
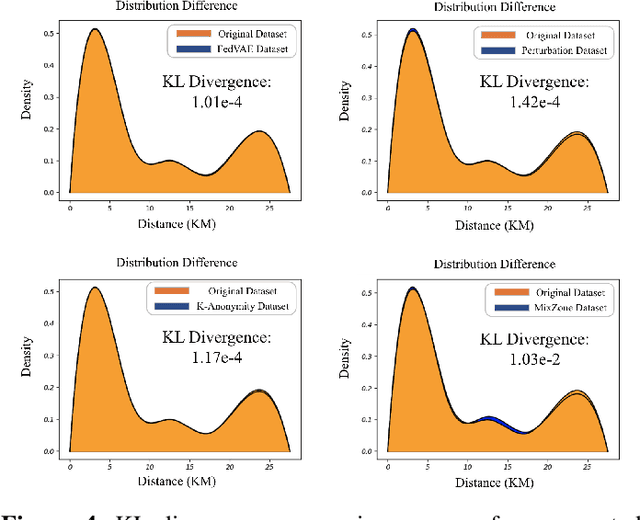
The use of trajectory data with abundant spatial-temporal information is pivotal in Intelligent Transport Systems (ITS) and various traffic system tasks. Location-Based Services (LBS) capitalize on this trajectory data to offer users personalized services tailored to their location information. However, this trajectory data contains sensitive information about users' movement patterns and habits, necessitating confidentiality and protection from unknown collectors. To address this challenge, privacy-preserving methods like K-anonymity and Differential Privacy have been proposed to safeguard private information in the dataset. Despite their effectiveness, these methods can impact the original features by introducing perturbations or generating unrealistic trajectory data, leading to suboptimal performance in downstream tasks. To overcome these limitations, we propose a Federated Variational AutoEncoder (FedVAE) approach, which effectively generates a new trajectory dataset while preserving the confidentiality of private information and retaining the structure of the original features. In addition, FedVAE leverages Variational AutoEncoder (VAE) to maintain the original feature space and generate new trajectory data, and incorporates Federated Learning (FL) during the training stage, ensuring that users' data remains locally stored to protect their personal information. The results demonstrate its superior performance compared to other existing methods, affirming FedVAE as a promising solution for enhancing data privacy and utility in location-based applications.
AIDE: An Automatic Data Engine for Object Detection in Autonomous Driving
Mar 26, 2024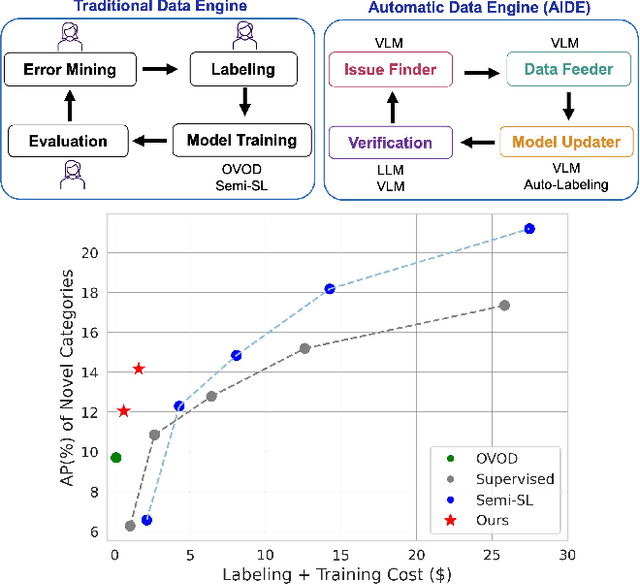
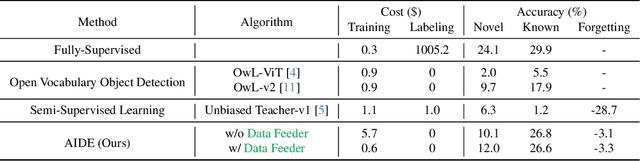
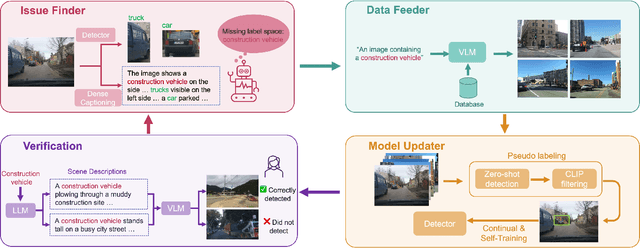
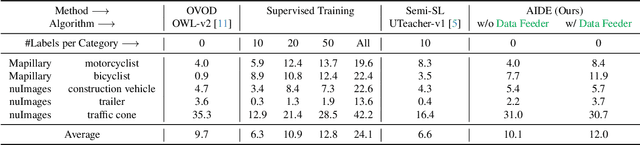
Autonomous vehicle (AV) systems rely on robust perception models as a cornerstone of safety assurance. However, objects encountered on the road exhibit a long-tailed distribution, with rare or unseen categories posing challenges to a deployed perception model. This necessitates an expensive process of continuously curating and annotating data with significant human effort. We propose to leverage recent advances in vision-language and large language models to design an Automatic Data Engine (AIDE) that automatically identifies issues, efficiently curates data, improves the model through auto-labeling, and verifies the model through generation of diverse scenarios. This process operates iteratively, allowing for continuous self-improvement of the model. We further establish a benchmark for open-world detection on AV datasets to comprehensively evaluate various learning paradigms, demonstrating our method's superior performance at a reduced cost.
GAN-driven Electromagnetic Imaging of 2-D Dielectric Scatterers
Feb 16, 2024



Inverse scattering problems are inherently challenging, given the fact they are ill-posed and nonlinear. This paper presents a powerful deep learning-based approach that relies on generative adversarial networks to accurately and efficiently reconstruct randomly-shaped two-dimensional dielectric objects from amplitudes of multi-frequency scattered electric fields. An adversarial autoencoder (AAE) is trained to learn to generate the scatterer's geometry from a lower-dimensional latent representation constrained to adhere to the Gaussian distribution. A cohesive inverse neural network (INN) framework is set up comprising a sequence of appropriately designed dense layers, the already-trained generator as well as a separately trained forward neural network. The images reconstructed at the output of the inverse network are validated through comparison with outputs from the forward neural network, addressing the non-uniqueness challenge inherent to electromagnetic (EM) imaging problems. The trained INN demonstrates an enhanced robustness, evidenced by a mean binary cross-entropy (BCE) loss of $0.13$ and a structure similarity index (SSI) of $0.90$. The study not only demonstrates a significant reduction in computational load, but also marks a substantial improvement over traditional objective-function-based methods. It contributes both to the fields of machine learning and EM imaging by offering a real-time quantitative imaging approach. The results obtained with the simulated data, for both training and testing, yield promising results and may open new avenues for radio-frequency inverse imaging.