 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoScape: Geometry-Consistent Long-Horizon Scene Generation
Oct 23, 2025This paper proposes AutoScape, a long-horizon driving scene generation framework. At its core is a novel RGB-D diffusion model that iteratively generates sparse, geometrically consistent keyframes, serving as reliable anchors for the scene's appearance and geometry. To maintain long-range geometric consistency, the model 1) jointly handles image and depth in a shared latent space, 2) explicitly conditions on the existing scene geometry (i.e., rendered point clouds) from previously generated keyframes, and 3) steers the sampling process with a warp-consistent guidance. Given high-quality RGB-D keyframes, a video diffusion model then interpolates between them to produce dense and coherent video frames. AutoScape generates realistic and geometrically consistent driving videos of over 20 seconds, improving the long-horizon FID and FVD scores over the prior state-of-the-art by 48.6\% and 43.0\%, respectively.
AIDE: An Automatic Data Engine for Object Detection in Autonomous Driving
Mar 26, 2024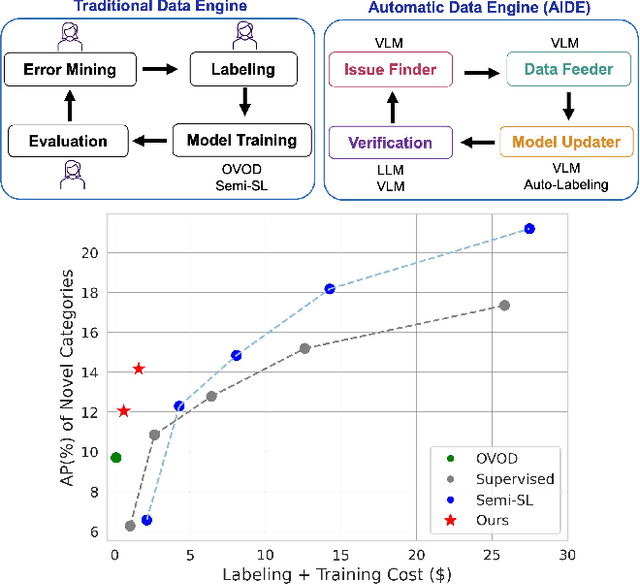
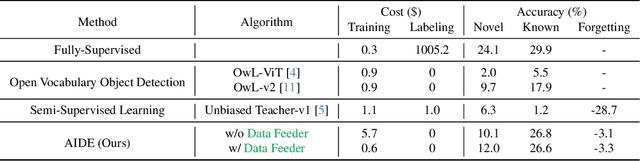
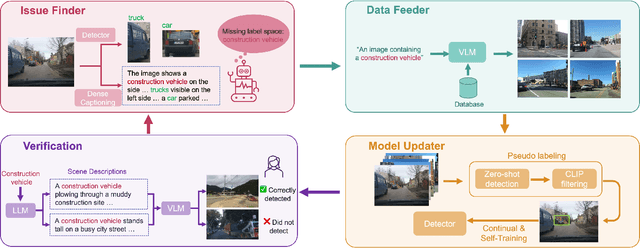
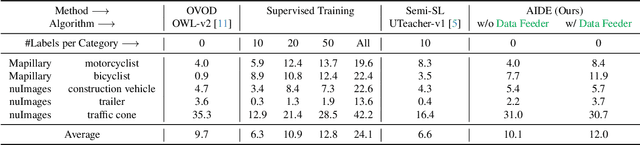
Autonomous vehicle (AV) systems rely on robust perception models as a cornerstone of safety assurance. However, objects encountered on the road exhibit a long-tailed distribution, with rare or unseen categories posing challenges to a deployed perception model. This necessitates an expensive process of continuously curating and annotating data with significant human effort. We propose to leverage recent advances in vision-language and large language models to design an Automatic Data Engine (AIDE) that automatically identifies issues, efficiently curates data, improves the model through auto-labeling, and verifies the model through generation of diverse scenarios. This process operates iteratively, allowing for continuous self-improvement of the model. We further establish a benchmark for open-world detection on AV datasets to comprehensively evaluate various learning paradigms, demonstrating our method's superior performance at a reduced cost.
RoPAWS: Robust Semi-supervised Representation Learning from Uncurated Data
Feb 28, 2023
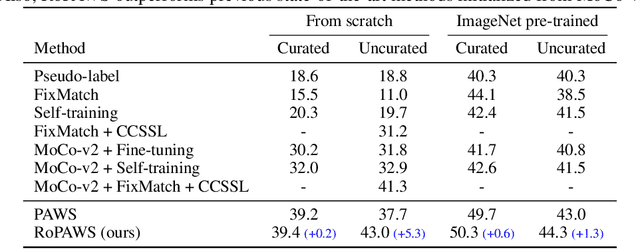
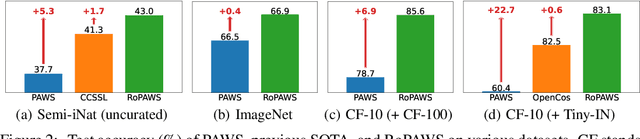

Semi-supervised learning aims to train a model using limited labels. State-of-the-art semi-supervised methods for image classification such as PAWS rely on self-supervised representations learned with large-scale unlabeled but curated data. However, PAWS is often less effective when using real-world unlabeled data that is uncurated, e.g., contains out-of-class data. We propose RoPAWS, a robust extension of PAWS that can work with real-world unlabeled data. We first reinterpret PAWS as a generative classifier that models densities using kernel density estimation. From this probabilistic perspective, we calibrate its prediction based on the densities of labeled and unlabeled data, which leads to a simple closed-form solution from the Bayes' rule. We demonstrate that RoPAWS significantly improves PAWS for uncurated Semi-iNat by +5.3% and curated ImageNet by +0.4%.
Tell Me What Happened: Unifying Text-guided Video Completion via Multimodal Masked Video Generation
Nov 23, 2022



Generating a video given the first several static frames is challenging as it anticipates reasonable future frames with temporal coherence. Besides video prediction, the ability to rewind from the last frame or infilling between the head and tail is also crucial, but they have rarely been explored for video completion. Since there could be different outcomes from the hints of just a few frames, a system that can follow natural language to perform video completion may significantly improve controllability. Inspired by this, we introduce a novel task, text-guided video completion (TVC), which requests the model to generate a video from partial frames guided by an instruction. We then propose Multimodal Masked Video Generation (MMVG) to address this TVC task. During training, MMVG discretizes the video frames into visual tokens and masks most of them to perform video completion from any time point. At inference time, a single MMVG model can address all 3 cases of TVC, including video prediction, rewind, and infilling, by applying corresponding masking conditions. We evaluate MMVG in various video scenarios, including egocentric, animation, and gaming. Extensive experimental results indicate that MMVG is effective in generating high-quality visual appearances with text guidance for TVC.
Semi-Supervised Learning with Taxonomic Labels
Nov 23, 2021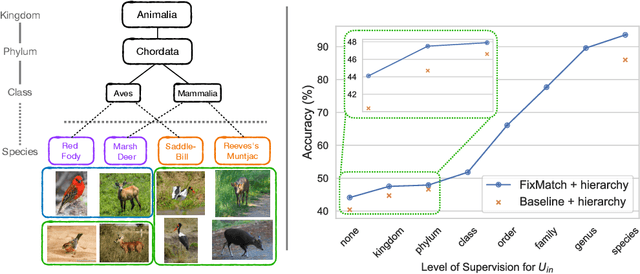
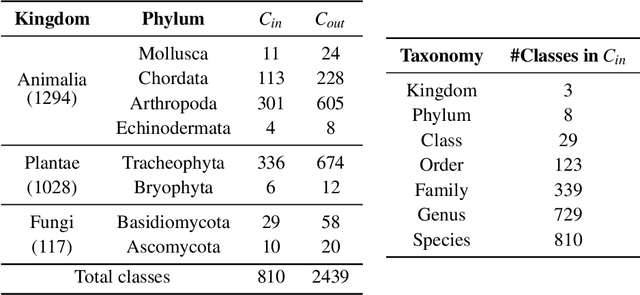
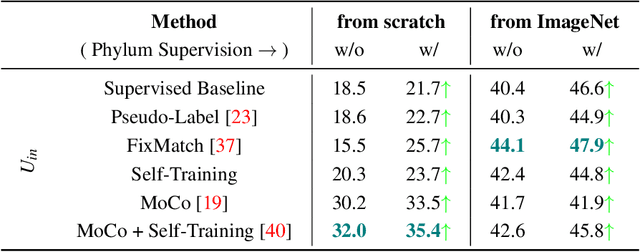
We propose techniques to incorporate coarse taxonomic labels to train image classifiers in fine-grained domains. Such labels can often be obtained with a smaller effort for fine-grained domains such as the natural world where categories are organized according to a biological taxonomy. On the Semi-iNat dataset consisting of 810 species across three Kingdoms, incorporating Phylum labels improves the Species level classification accuracy by 6% in a transfer learning setting using ImageNet pre-trained models. Incorporating the hierarchical label structure with a state-of-the-art semi-supervised learning algorithm called FixMatch improves the performance further by 1.3%. The relative gains are larger when detailed labels such as Class or Order are provided, or when models are trained from scratch. However, we find that most methods are not robust to the presence of out-of-domain data from novel classes. We propose a technique to select relevant data from a large collection of unlabeled images guided by the hierarchy which improves the robustness. Overall, our experiments show that semi-supervised learning with coarse taxonomic labels are practical for training classifiers in fine-grained domains.
The Semi-Supervised iNaturalist Challenge at the FGVC8 Workshop
Jun 02, 2021
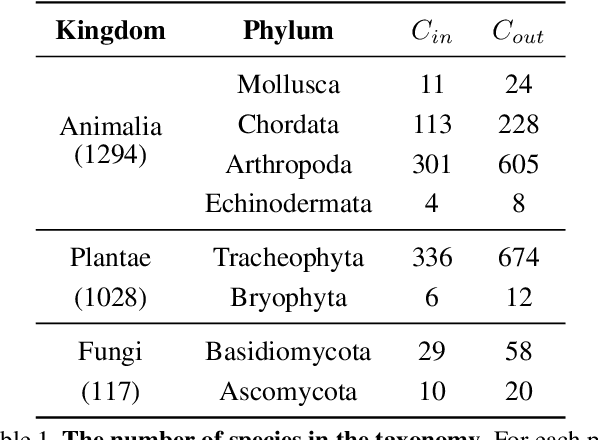

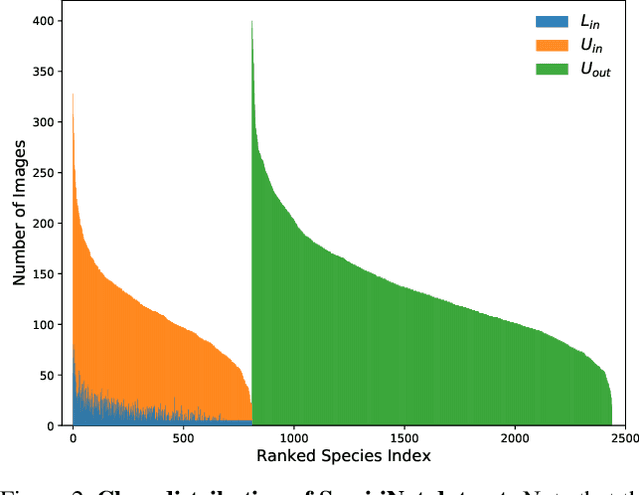
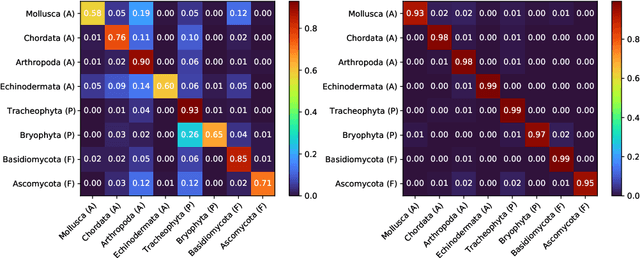
Semi-iNat is a challenging dataset for semi-supervised classification with a long-tailed distribution of classes, fine-grained categories, and domain shifts between labeled and unlabeled data. This dataset is behind the second iteration of the semi-supervised recognition challenge to be held at the FGVC8 workshop at CVPR 2021. Different from the previous one, this dataset (i) includes images of species from different kingdoms in the natural taxonomy, (ii) is at a larger scale --- with 810 in-class and 1629 out-of-class species for a total of 330k images, and (iii) does not provide in/out-of-class labels, but provides coarse taxonomic labels (kingdom and phylum) for the unlabeled images. This document describes baseline results and the details of the dataset which is available here: \url{https://github.com/cvl-umass/semi-inat-2021}.
A Realistic Evaluation of Semi-Supervised Learning for Fine-Grained Classification
Apr 01, 2021
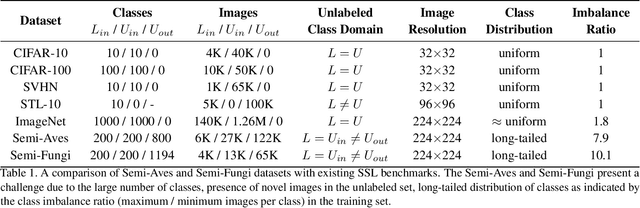
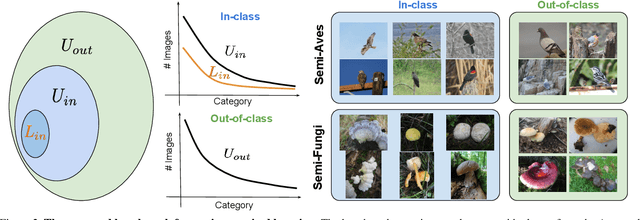
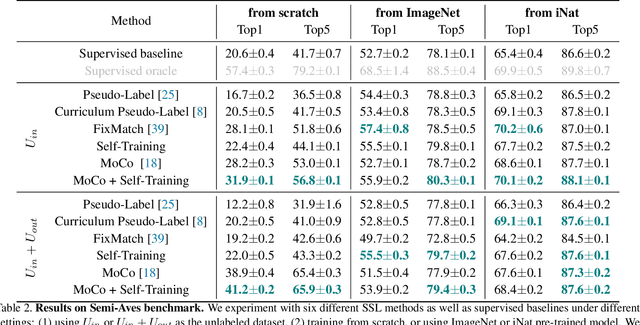
We evaluate the effectiveness of semi-supervised learning (SSL) on a realistic benchmark where data exhibits considerable class imbalance and contains images from novel classes. Our benchmark consists of two fine-grained classification datasets obtained by sampling classes from the Aves and Fungi taxonomy. We find that recently proposed SSL methods provide significant benefits, and can effectively use out-of-class data to improve performance when deep networks are trained from scratch. Yet their performance pales in comparison to a transfer learning baseline, an alternative approach for learning from a few examples. Furthermore, in the transfer setting, while existing SSL methods provide improvements, the presence of out-of-class is often detrimental. In this setting, standard fine-tuning followed by distillation-based self-training is the most robust. Our work suggests that semi-supervised learning with experts on realistic datasets may require different strategies than those currently prevalent in the literature.
The Semi-Supervised iNaturalist-Aves Challenge at FGVC7 Workshop
Mar 11, 2021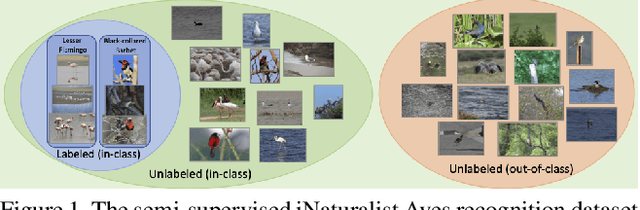
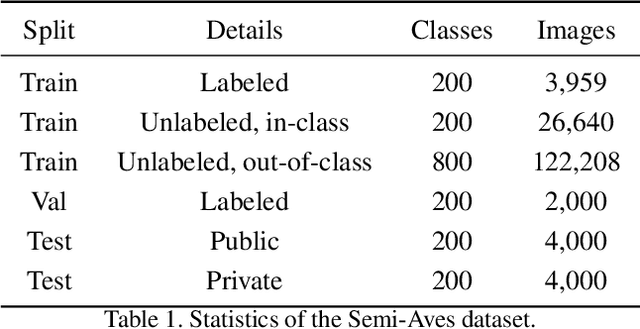
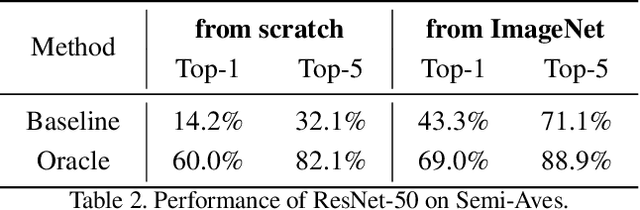
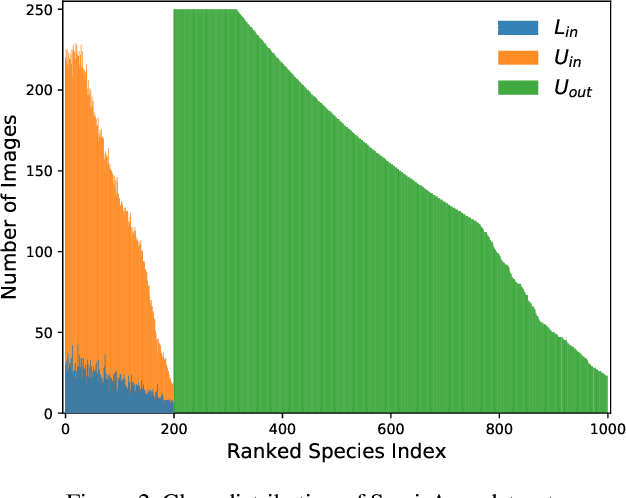
This document describes the details and the motivation behind a new dataset we collected for the semi-supervised recognition challenge~\cite{semi-aves} at the FGVC7 workshop at CVPR 2020. The dataset contains 1000 species of birds sampled from the iNat-2018 dataset for a total of nearly 150k images. From this collection, we sample a subset of classes and their labels, while adding the images from the remaining classes to the unlabeled set of images. The presence of out-of-domain data (novel classes), high class-imbalance, and fine-grained similarity between classes poses significant challenges for existing semi-supervised recognition techniques in the literature. The dataset is available here: \url{https://github.com/cvl-umass/semi-inat-2020}
Unsupervised Discovery of Object Landmarks via Contrastive Learning
Jun 26, 2020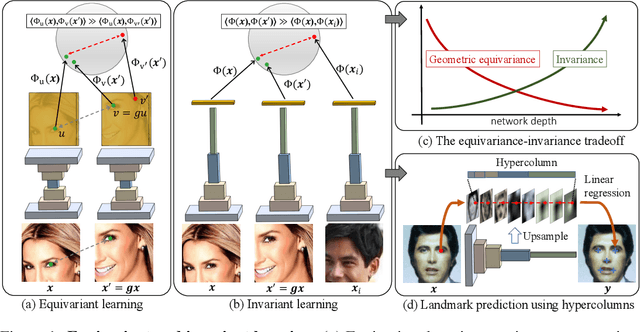
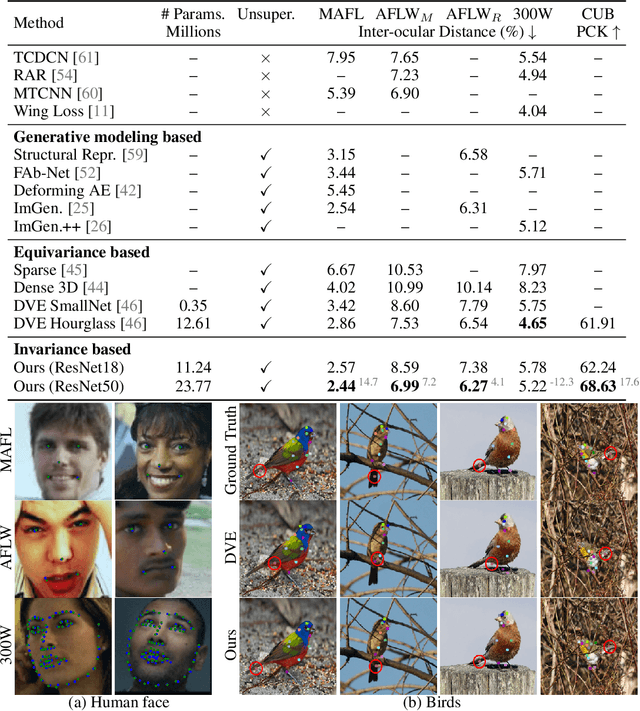
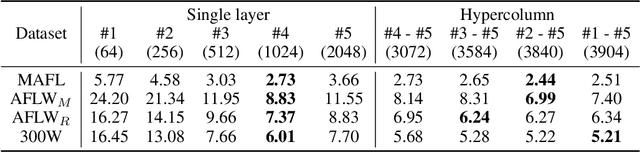
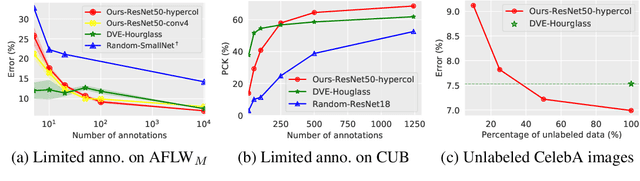
Given a collection of images, humans are able to discover landmarks of the depicted objects by modeling the shared geometric structure across instances. This idea of geometric equivariance has been widely used for unsupervised discovery of object landmark representations. In this paper, we develop a simple and effective approach based on contrastive learning of invariant representations. We show that when a deep network is trained to be invariant to geometric and photometric transformations, representations from its intermediate layers are highly predictive of object landmarks. Furthermore, by stacking representations across layers in a hypercolumn their effectiveness can be improved. Our approach is motivated by the phenomenon of the gradual emergence of invariance in the representation hierarchy of a deep network. We also present a unified view of existing equivariant and invariant representation learning approaches through the lens of contrastive learning, shedding light on the nature of invariances learned. Experiments on standard benchmarks for landmark discovery, as well as a challenging one we propose, show that the proposed approach surpasses prior state-of-the-art.
When Does Self-supervision Improve Few-shot Learning?
Oct 08, 2019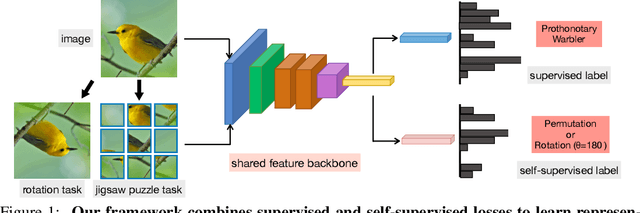
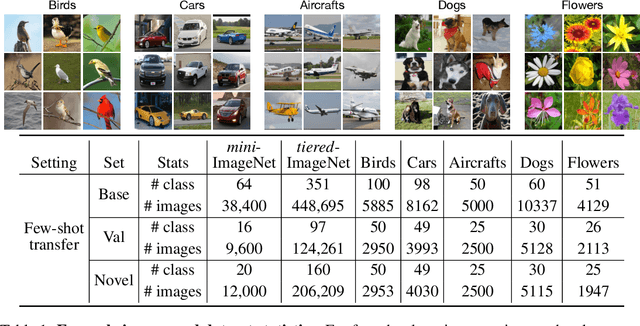
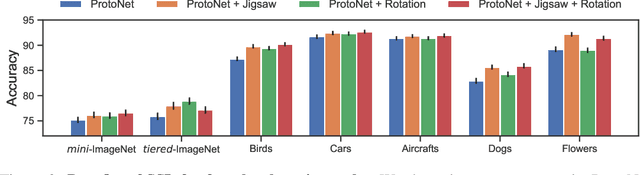
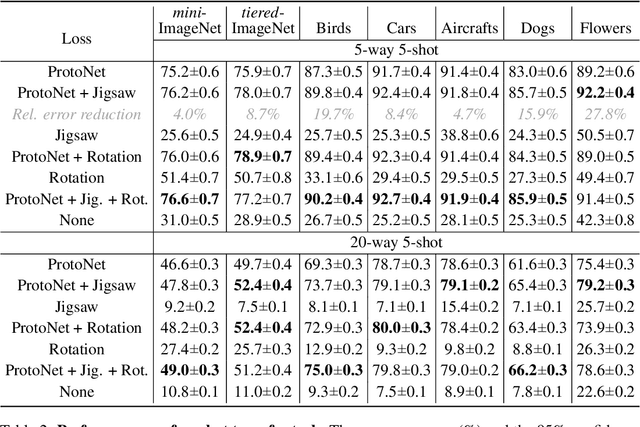
We present a technique to improve the generalization of deep representations learned on small labeled datasets by introducing self-supervised tasks as auxiliary loss functions. Although recent research has shown benefits of self-supervised learning (SSL) on large unlabeled datasets, its utility on small datasets is unknown. We find that SSL reduces the relative error rate of few-shot meta-learners by 4%-27%, even when the datasets are small and only utilizing images within the datasets. The improvements are greater when the training set is smaller or the task is more challenging. Though the benefits of SSL may increase with larger training sets, we observe that SSL can have a negative impact on performance when there is a domain shift between distribution of images used for meta-learning and SSL. Based on this analysis we present a technique that automatically select images for SSL from a large, generic pool of unlabeled images for a given dataset using a domain classifier that provides further improvements. We present results using several meta-learners and self-supervised tasks across datasets with varying degrees of domain shifts and label sizes to characterize the effectiveness of SSL for few-shot learning.