 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Autoencoders with Limited Data: Does It Work? A Fine-Grained Bioacoustics Case Study
May 13, 2026Bioacoustic recognition requires fine-grained acoustic understanding to distinguish similar-sounding species. However, many large-scale data repositories such as iNaturalist are weakly annotated, often with only a single positive species label per recording, making supervised learning particularly challenging. Inspired by advances in computer vision, recent approaches have shifted toward self-supervised learning to capture the underlying structure of audio without relying on exhaustive annotations. In particular, masked autoencoders (MAE) have shown strong transferability on massive audio corpora, yet their effectiveness in more modest bioacoustic settings remains underexplored. In this work, we conduct a systematic study of MAE pretraining for species classification on iNatSounds, analyzing the impacts of pretraining data scale, domain specificity, data curation, and transfer strategies. Consistent with prior work, we find that models pretrained on diverse general audio data achieve the best transfer performance on iNatSounds. Contrary to observations from large-scale audio benchmarks, we find that (1) additional masked reconstruction pretraining on domain-specific data provides limited benefits and may even degrade performance relative to off-the-shelf models, and (2) selective data filtering offers a negligible advantage when the overall data scale is limited. Our results indicate that, in moderate-sized fine-grained bioacoustic settings, pretraining scale dominates objective design. These findings further clarify when MAE-based pretraining is effective and provide practical guidance for model selection under limited supervision.
Centering Ecological Goals in Automated Identification of Individual Animals
Apr 22, 2026Recognizing individual animals over time is central to many ecological and conservation questions, including estimating abundance, survival, movement, and social structure. Recent advances in automated identification from images and even acoustic data suggest that this process could be greatly accelerated, yet their promise has not translated well into ecological practice. We argue that the main barrier is not the performance of the automated methods themselves, but a mismatch between how those methods are typically developed and evaluated, and how ecological data is actually collected, processed, reviewed, and used. Future progress, therefore, will depend less on algorithmic gains alone than on recognizing that the usefulness of automated identification is grounded in ecological context: it depends on what question is being asked, what data are available, and what kinds of mistakes matter. Only by centering these questions can we move toward automated identification of individuals that is not only accurate but also ecologically useful, transparent, and trustworthy.
Active Measurement of Two-Point Correlations
Apr 06, 2026Two-point correlation functions (2PCF) are widely used to characterize how points cluster in space. In this work, we study the problem of measuring the 2PCF over a large set of points, restricted to a subset satisfying a property of interest. An example comes from astronomy, where scientists measure the 2PCF of star clusters, which make up only a tiny subset of possible sources within a galaxy. This task typically requires careful labeling of sources to construct catalogs, which is time-consuming. We present a human-in-the-loop framework for efficient estimation of 2PCF of target sources. By leveraging a pre-trained classifier to guide sampling, our approach adaptively selects the most informative points for human annotation. After each annotation, it produces unbiased estimates of pair counts across multiple distance bins simultaneously. Compared to simple Monte Carlo approaches, our method achieves substantially lower variance while significantly reducing annotation effort. We introduce a novel unbiased estimator, sampling strategy, and confidence interval construction that together enable scalable and statistically grounded measurement of two-point correlations in astronomy datasets.
RealBirdID: Benchmarking Bird Species Identification in the Era of MLLMs
Mar 27, 2026Fine-grained bird species identification in the wild is frequently unanswerable from a single image: key cues may be non-visual (e.g. vocalization), or obscured due to occlusion, camera angle, or low resolution. Yet today's multimodal systems are typically judged on answerable, in-schema cases, encouraging confident guesses rather than principled abstention. We propose the RealBirdID benchmark: given an image of a bird, a system should either answer with a species or abstain with a concrete, evidence-based rationale: "requires vocalization," "low quality image," or "view obstructed". For each genus, the dataset includes a validation split composed of curated unanswerable examples with labeled rationales, paired with a companion set of clearly answerable instances. We find that (1) the species identification on the answerable set is challenging for a variety of open-source and proprietary models (less than 13% accuracy for MLLMs including GPT-5 and Gemini-2.5 Pro), (2) models with greater classification ability are not necessarily more calibrated to abstain from unanswerable examples, and (3) that MLLMs generally fail at providing correct reasons even when they do abstain. RealBirdID establishes a focused target for abstention-aware fine-grained recognition and a recipe for measuring progress.
3D Space as a Scratchpad for Editable Text-to-Image Generation
Jan 21, 2026Recent progress in large language models (LLMs) has shown that reasoning improves when intermediate thoughts are externalized into explicit workspaces, such as chain-of-thought traces or tool-augmented reasoning. Yet, visual language models (VLMs) lack an analogous mechanism for spatial reasoning, limiting their ability to generate images that accurately reflect geometric relations, object identities, and compositional intent. We introduce the concept of a spatial scratchpad -- a 3D reasoning substrate that bridges linguistic intent and image synthesis. Given a text prompt, our framework parses subjects and background elements, instantiates them as editable 3D meshes, and employs agentic scene planning for placement, orientation, and viewpoint selection. The resulting 3D arrangement is rendered back into the image domain with identity-preserving cues, enabling the VLM to generate spatially consistent and visually coherent outputs. Unlike prior 2D layout-based methods, our approach supports intuitive 3D edits that propagate reliably into final images. Empirically, it achieves a 32% improvement in text alignment on GenAI-Bench, demonstrating the benefit of explicit 3D reasoning for precise, controllable image generation. Our results highlight a new paradigm for vision-language models that deliberate not only in language, but also in space. Code and visualizations at https://oindrilasaha.github.io/3DScratchpad/
SuperRivolution: Fine-Scale Rivers from Coarse Temporal Satellite Imagery
Nov 12, 2025
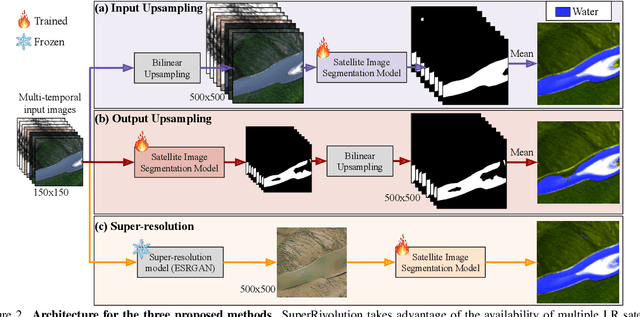
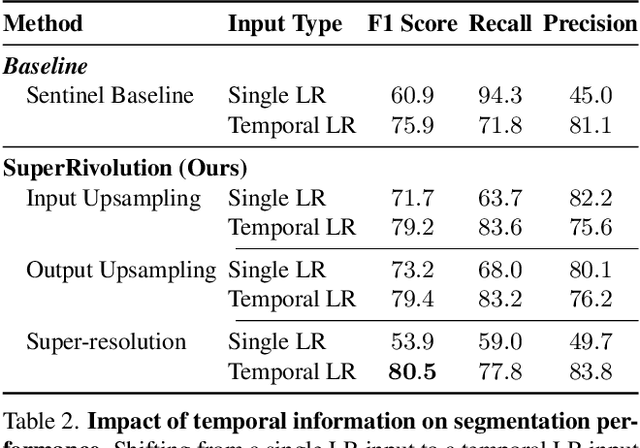
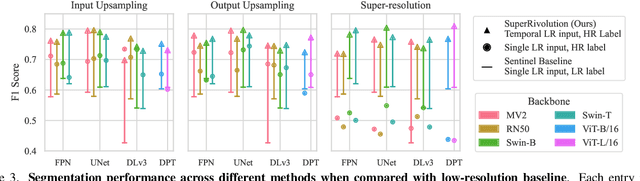
Satellite missions provide valuable optical data for monitoring rivers at diverse spatial and temporal scales. However, accessibility remains a challenge: high-resolution imagery is ideal for fine-grained monitoring but is typically scarce and expensive compared to low-resolution imagery. To address this gap, we introduce SuperRivolution, a framework that improves river segmentation resolution by leveraging information from time series of low-resolution satellite images. We contribute a new benchmark dataset of 9,810 low-resolution temporal images paired with high-resolution labels from an existing river monitoring dataset. Using this benchmark, we investigate multiple strategies for river segmentation, including ensembling single-image models, applying image super-resolution, and developing end-to-end models trained on temporal sequences. SuperRivolution significantly outperforms single-image methods and baseline temporal approaches, narrowing the gap with supervised high-resolution models. For example, the F1 score for river segmentation improves from 60.9% to 80.5%, while the state-of-the-art model operating on high-resolution images achieves 94.1%. Similar improvements are also observed in river width estimation tasks. Our results highlight the potential of publicly available low-resolution satellite archives for fine-scale river monitoring.
Consensus-Driven Active Model Selection
Jul 31, 2025The widespread availability of off-the-shelf machine learning models poses a challenge: which model, of the many available candidates, should be chosen for a given data analysis task? This question of model selection is traditionally answered by collecting and annotating a validation dataset -- a costly and time-intensive process. We propose a method for active model selection, using predictions from candidate models to prioritize the labeling of test data points that efficiently differentiate the best candidate. Our method, CODA, performs consensus-driven active model selection by modeling relationships between classifiers, categories, and data points within a probabilistic framework. The framework uses the consensus and disagreement between models in the candidate pool to guide the label acquisition process, and Bayesian inference to update beliefs about which model is best as more information is collected. We validate our approach by curating a collection of 26 benchmark tasks capturing a range of model selection scenarios. CODA outperforms existing methods for active model selection significantly, reducing the annotation effort required to discover the best model by upwards of 70% compared to the previous state-of-the-art. Code and data are available at https://github.com/justinkay/coda.
Active Measurement: Efficient Estimation at Scale
Jul 02, 2025AI has the potential to transform scientific discovery by analyzing vast datasets with little human effort. However, current workflows often do not provide the accuracy or statistical guarantees that are needed. We introduce active measurement, a human-in-the-loop AI framework for scientific measurement. An AI model is used to predict measurements for individual units, which are then sampled for human labeling using importance sampling. With each new set of human labels, the AI model is improved and an unbiased Monte Carlo estimate of the total measurement is refined. Active measurement can provide precise estimates even with an imperfect AI model, and requires little human effort when the AI model is very accurate. We derive novel estimators, weighting schemes, and confidence intervals, and show that active measurement reduces estimation error compared to alternatives in several measurement tasks.
Audio Geolocation: A Natural Sounds Benchmark
May 24, 2025Can we determine someone's geographic location purely from the sounds they hear? Are acoustic signals enough to localize within a country, state, or even city? We tackle the challenge of global-scale audio geolocation, formalize the problem, and conduct an in-depth analysis with wildlife audio from the iNatSounds dataset. Adopting a vision-inspired approach, we convert audio recordings to spectrograms and benchmark existing image geolocation techniques. We hypothesize that species vocalizations offer strong geolocation cues due to their defined geographic ranges and propose an approach that integrates species range prediction with retrieval-based geolocation. We further evaluate whether geolocation improves when analyzing species-rich recordings or when aggregating across spatiotemporal neighborhoods. Finally, we introduce case studies from movies to explore multimodal geolocation using both audio and visual content. Our work highlights the advantages of integrating audio and visual cues, and sets the stage for future research in audio geolocation.
Few-shot Species Range Estimation
Feb 20, 2025Knowing where a particular species can or cannot be found on Earth is crucial for ecological research and conservation efforts. By mapping the spatial ranges of all species, we would obtain deeper insights into how global biodiversity is affected by climate change and habitat loss. However, accurate range estimates are only available for a relatively small proportion of all known species. For the majority of the remaining species, we often only have a small number of records denoting the spatial locations where they have previously been observed. We outline a new approach for few-shot species range estimation to address the challenge of accurately estimating the range of a species from limited data. During inference, our model takes a set of spatial locations as input, along with optional metadata such as text or an image, and outputs a species encoding that can be used to predict the range of a previously unseen species in feed-forward manner. We validate our method on two challenging benchmarks, where we obtain state-of-the-art range estimation performance, in a fraction of the compute time, compared to recent alternative approaches.