 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerate, Transduct, Adapt: Iterative Transduction with VLMs
Jan 10, 2025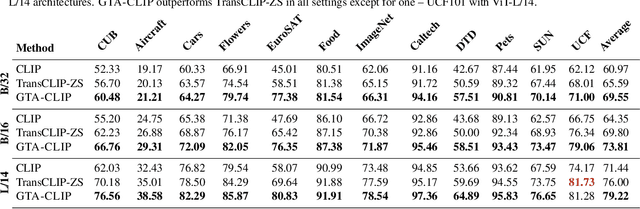
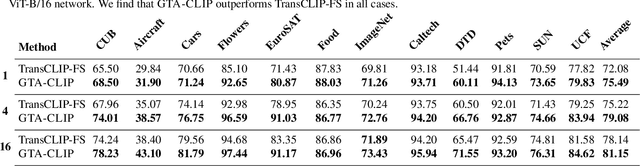
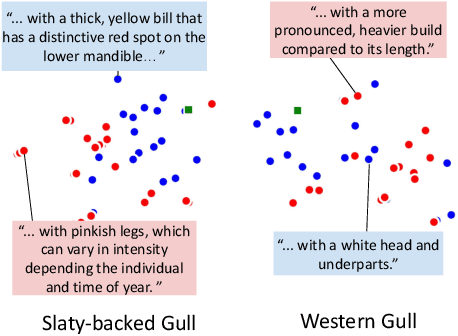
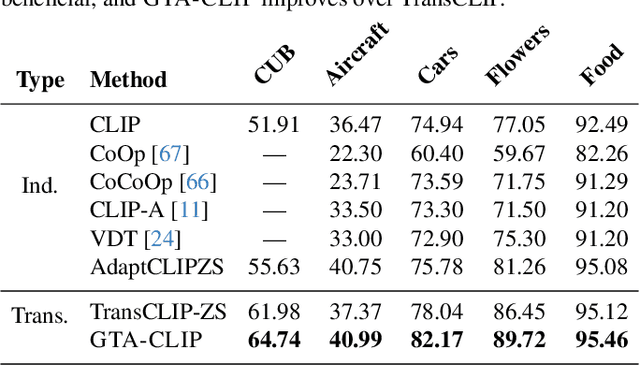
Transductive zero-shot learning with vision-language models leverages image-image similarities within the dataset to achieve better classification accuracy compared to the inductive setting. However, there is little work that explores the structure of the language space in this context. We propose GTA-CLIP, a novel technique that incorporates supervision from language models for joint transduction in language and vision spaces. Our approach is iterative and consists of three steps: (i) incrementally exploring the attribute space by querying language models, (ii) an attribute-augmented transductive inference procedure, and (iii) fine-tuning the language and vision encoders based on inferred labels within the dataset. Through experiments with CLIP encoders, we demonstrate that GTA-CLIP, yields an average performance improvement of 8.6% and 3.7% across 12 datasets and 3 encoders, over CLIP and transductive CLIP respectively in the zero-shot setting. We also observe similar improvements in a few-shot setting. We present ablation studies that demonstrate the value of each step and visualize how the vision and language spaces evolve over iterations driven by the transductive learning.
Efficient Transformer Knowledge Distillation: A Performance Review
Nov 22, 2023As pretrained transformer language models continue to achieve state-of-the-art performance, the Natural Language Processing community has pushed for advances in model compression and efficient attention mechanisms to address high computational requirements and limited input sequence length. Despite these separate efforts, no investigation has been done into the intersection of these two fields. In this work, we provide an evaluation of model compression via knowledge distillation on efficient attention transformers. We provide cost-performance trade-offs for the compression of state-of-the-art efficient attention architectures and the gains made in performance in comparison to their full attention counterparts. Furthermore, we introduce a new long-context Named Entity Recognition dataset, GONERD, to train and test the performance of NER models on long sequences. We find that distilled efficient attention transformers can preserve a significant amount of original model performance, preserving up to 98.6% across short-context tasks (GLUE, SQUAD, CoNLL-2003), up to 94.6% across long-context Question-and-Answering tasks (HotpotQA, TriviaQA), and up to 98.8% on long-context Named Entity Recognition (GONERD), while decreasing inference times by up to 57.8%. We find that, for most models on most tasks, performing knowledge distillation is an effective method to yield high-performing efficient attention models with low costs.