 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealBirdID: Benchmarking Bird Species Identification in the Era of MLLMs
Mar 27, 2026Fine-grained bird species identification in the wild is frequently unanswerable from a single image: key cues may be non-visual (e.g. vocalization), or obscured due to occlusion, camera angle, or low resolution. Yet today's multimodal systems are typically judged on answerable, in-schema cases, encouraging confident guesses rather than principled abstention. We propose the RealBirdID benchmark: given an image of a bird, a system should either answer with a species or abstain with a concrete, evidence-based rationale: "requires vocalization," "low quality image," or "view obstructed". For each genus, the dataset includes a validation split composed of curated unanswerable examples with labeled rationales, paired with a companion set of clearly answerable instances. We find that (1) the species identification on the answerable set is challenging for a variety of open-source and proprietary models (less than 13% accuracy for MLLMs including GPT-5 and Gemini-2.5 Pro), (2) models with greater classification ability are not necessarily more calibrated to abstain from unanswerable examples, and (3) that MLLMs generally fail at providing correct reasons even when they do abstain. RealBirdID establishes a focused target for abstention-aware fine-grained recognition and a recipe for measuring progress.
CleverBirds: A Multiple-Choice Benchmark for Fine-grained Human Knowledge Tracing
Nov 11, 2025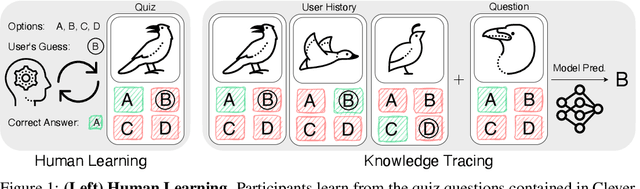

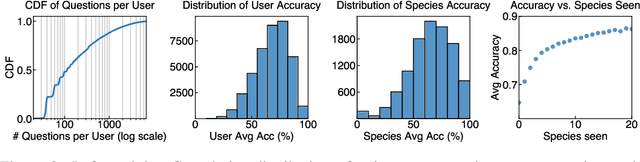
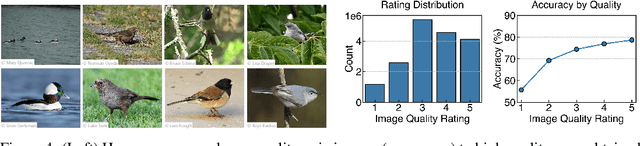
Mastering fine-grained visual recognition, essential in many expert domains, can require that specialists undergo years of dedicated training. Modeling the progression of such expertize in humans remains challenging, and accurately inferring a human learner's knowledge state is a key step toward understanding visual learning. We introduce CleverBirds, a large-scale knowledge tracing benchmark for fine-grained bird species recognition. Collected by the citizen-science platform eBird, it offers insight into how individuals acquire expertize in complex fine-grained classification. More than 40,000 participants have engaged in the quiz, answering over 17 million multiple-choice questions spanning over 10,000 bird species, with long-range learning patterns across an average of 400 questions per participant. We release this dataset to support the development and evaluation of new methods for visual knowledge tracing. We show that tracking learners' knowledge is challenging, especially across participant subgroups and question types, with different forms of contextual information offering varying degrees of predictive benefit. CleverBirds is among the largest benchmark of its kind, offering a substantially higher number of learnable concepts. With it, we hope to enable new avenues for studying the development of visual expertize over time and across individuals.
Consensus-Driven Active Model Selection
Jul 31, 2025The widespread availability of off-the-shelf machine learning models poses a challenge: which model, of the many available candidates, should be chosen for a given data analysis task? This question of model selection is traditionally answered by collecting and annotating a validation dataset -- a costly and time-intensive process. We propose a method for active model selection, using predictions from candidate models to prioritize the labeling of test data points that efficiently differentiate the best candidate. Our method, CODA, performs consensus-driven active model selection by modeling relationships between classifiers, categories, and data points within a probabilistic framework. The framework uses the consensus and disagreement between models in the candidate pool to guide the label acquisition process, and Bayesian inference to update beliefs about which model is best as more information is collected. We validate our approach by curating a collection of 26 benchmark tasks capturing a range of model selection scenarios. CODA outperforms existing methods for active model selection significantly, reducing the annotation effort required to discover the best model by upwards of 70% compared to the previous state-of-the-art. Code and data are available at https://github.com/justinkay/coda.
Audio Geolocation: A Natural Sounds Benchmark
May 24, 2025Can we determine someone's geographic location purely from the sounds they hear? Are acoustic signals enough to localize within a country, state, or even city? We tackle the challenge of global-scale audio geolocation, formalize the problem, and conduct an in-depth analysis with wildlife audio from the iNatSounds dataset. Adopting a vision-inspired approach, we convert audio recordings to spectrograms and benchmark existing image geolocation techniques. We hypothesize that species vocalizations offer strong geolocation cues due to their defined geographic ranges and propose an approach that integrates species range prediction with retrieval-based geolocation. We further evaluate whether geolocation improves when analyzing species-rich recordings or when aggregating across spatiotemporal neighborhoods. Finally, we introduce case studies from movies to explore multimodal geolocation using both audio and visual content. Our work highlights the advantages of integrating audio and visual cues, and sets the stage for future research in audio geolocation.
Few-shot Species Range Estimation
Feb 20, 2025Knowing where a particular species can or cannot be found on Earth is crucial for ecological research and conservation efforts. By mapping the spatial ranges of all species, we would obtain deeper insights into how global biodiversity is affected by climate change and habitat loss. However, accurate range estimates are only available for a relatively small proportion of all known species. For the majority of the remaining species, we often only have a small number of records denoting the spatial locations where they have previously been observed. We outline a new approach for few-shot species range estimation to address the challenge of accurately estimating the range of a species from limited data. During inference, our model takes a set of spatial locations as input, along with optional metadata such as text or an image, and outputs a species encoding that can be used to predict the range of a previously unseen species in feed-forward manner. We validate our method on two challenging benchmarks, where we obtain state-of-the-art range estimation performance, in a fraction of the compute time, compared to recent alternative approaches.
Counting Fish with Temporal Representations of Sonar Video
Feb 07, 2025



Accurate estimates of salmon escapement - the number of fish migrating upstream to spawn - are key data for conservation and fishery management. Existing methods for salmon counting using high-resolution imaging sonar hardware are non-invasive and compatible with computer vision processing. Prior work in this area has utilized object detection and tracking based methods for automated salmon counting. However, these techniques remain inaccessible to many sonar deployment sites due to limited compute and connectivity in the field. We propose an alternative lightweight computer vision method for fish counting based on analyzing echograms - temporal representations that compress several hundred frames of imaging sonar video into a single image. We predict upstream and downstream counts within 200-frame time windows directly from echograms using a ResNet-18 model, and propose a set of domain-specific image augmentations and a weakly-supervised training protocol to further improve results. We achieve a count error of 23% on representative data from the Kenai River in Alaska, demonstrating the feasibility of our approach.
Generate, Transduct, Adapt: Iterative Transduction with VLMs
Jan 10, 2025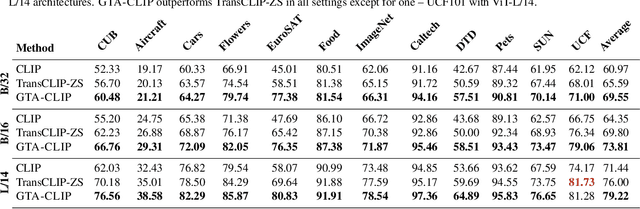
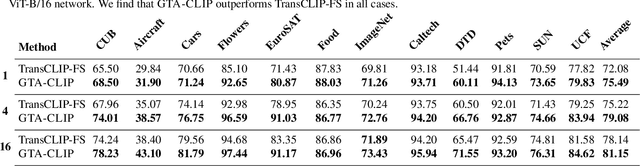
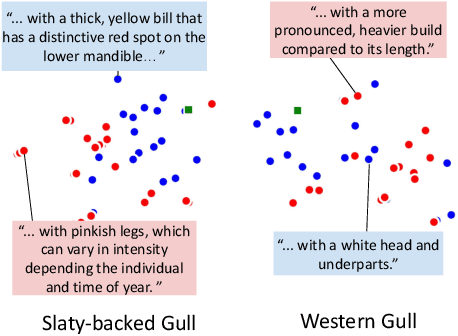
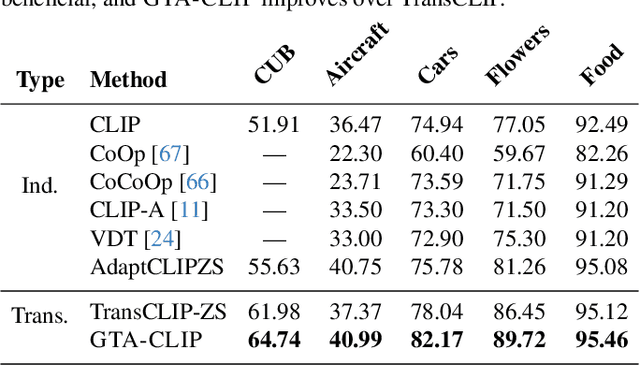
Transductive zero-shot learning with vision-language models leverages image-image similarities within the dataset to achieve better classification accuracy compared to the inductive setting. However, there is little work that explores the structure of the language space in this context. We propose GTA-CLIP, a novel technique that incorporates supervision from language models for joint transduction in language and vision spaces. Our approach is iterative and consists of three steps: (i) incrementally exploring the attribute space by querying language models, (ii) an attribute-augmented transductive inference procedure, and (iii) fine-tuning the language and vision encoders based on inferred labels within the dataset. Through experiments with CLIP encoders, we demonstrate that GTA-CLIP, yields an average performance improvement of 8.6% and 3.7% across 12 datasets and 3 encoders, over CLIP and transductive CLIP respectively in the zero-shot setting. We also observe similar improvements in a few-shot setting. We present ablation studies that demonstrate the value of each step and visualize how the vision and language spaces evolve over iterations driven by the transductive learning.
WildSAT: Learning Satellite Image Representations from Wildlife Observations
Dec 19, 2024What does the presence of a species reveal about a geographic location? We posit that habitat, climate, and environmental preferences reflected in species distributions provide a rich source of supervision for learning satellite image representations. We introduce WildSAT, which pairs satellite images with millions of geo-tagged wildlife observations readily-available on citizen science platforms. WildSAT uses a contrastive learning framework to combine information from species distribution maps with text descriptions that capture habitat and range details, alongside satellite images, to train or fine-tune models. On a range of downstream satellite image recognition tasks, this significantly improves the performance of both randomly initialized models and pre-trained models from sources like ImageNet or specialized satellite image datasets. Additionally, the alignment with text enables zero-shot retrieval, allowing for search based on general descriptions of locations. We demonstrate that WildSAT achieves better representations than recent methods that utilize other forms of cross-modal supervision, such as aligning satellite images with ground images or wildlife photos. Finally, we analyze the impact of various design choices on downstream performance, highlighting the general applicability of our approach.
INQUIRE: A Natural World Text-to-Image Retrieval Benchmark
Nov 04, 2024We introduce INQUIRE, a text-to-image retrieval benchmark designed to challenge multimodal vision-language models on expert-level queries. INQUIRE includes iNaturalist 2024 (iNat24), a new dataset of five million natural world images, along with 250 expert-level retrieval queries. These queries are paired with all relevant images comprehensively labeled within iNat24, comprising 33,000 total matches. Queries span categories such as species identification, context, behavior, and appearance, emphasizing tasks that require nuanced image understanding and domain expertise. Our benchmark evaluates two core retrieval tasks: (1) INQUIRE-Fullrank, a full dataset ranking task, and (2) INQUIRE-Rerank, a reranking task for refining top-100 retrievals. Detailed evaluation of a range of recent multimodal models demonstrates that INQUIRE poses a significant challenge, with the best models failing to achieve an mAP@50 above 50%. In addition, we show that reranking with more powerful multimodal models can enhance retrieval performance, yet there remains a significant margin for improvement. By focusing on scientifically-motivated ecological challenges, INQUIRE aims to bridge the gap between AI capabilities and the needs of real-world scientific inquiry, encouraging the development of retrieval systems that can assist with accelerating ecological and biodiversity research. Our dataset and code are available at https://inquire-benchmark.github.io
Combining Observational Data and Language for Species Range Estimation
Oct 14, 2024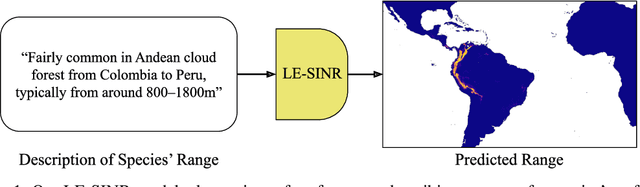
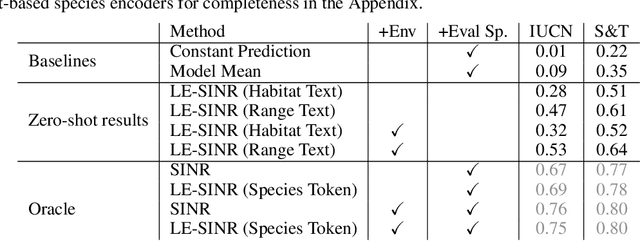
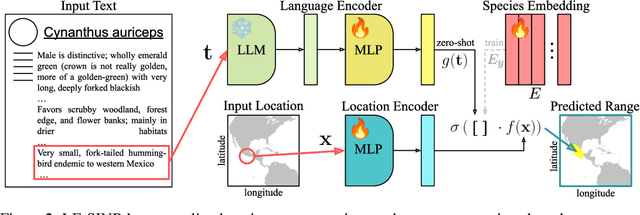
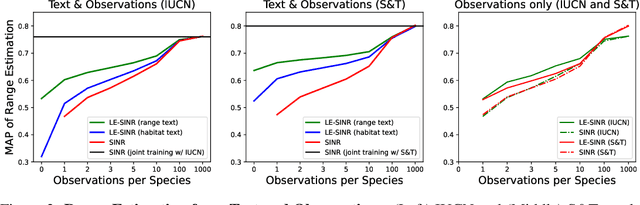
Species range maps (SRMs) are essential tools for research and policy-making in ecology, conservation, and environmental management. However, traditional SRMs rely on the availability of environmental covariates and high-quality species location observation data, both of which can be challenging to obtain due to geographic inaccessibility and resource constraints. We propose a novel approach combining millions of citizen science species observations with textual descriptions from Wikipedia, covering habitat preferences and range descriptions for tens of thousands of species. Our framework maps locations, species, and text descriptions into a common space, facilitating the learning of rich spatial covariates at a global scale and enabling zero-shot range estimation from textual descriptions. Evaluated on held-out species, our zero-shot SRMs significantly outperform baselines and match the performance of SRMs obtained using tens of observations. Our approach also acts as a strong prior when combined with observational data, resulting in more accurate range estimation with less data. We present extensive quantitative and qualitative analyses of the learned representations in the context of range estimation and other spatial tasks, demonstrating the effectiveness of our approach.