 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign and Distill: Unifying and Improving Domain Adaptive Object Detection
Mar 18, 2024



Object detectors often perform poorly on data that differs from their training set. Domain adaptive object detection (DAOD) methods have recently demonstrated strong results on addressing this challenge. Unfortunately, we identify systemic benchmarking pitfalls that call past results into question and hamper further progress: (a) Overestimation of performance due to underpowered baselines, (b) Inconsistent implementation practices preventing transparent comparisons of methods, and (c) Lack of generality due to outdated backbones and lack of diversity in benchmarks. We address these problems by introducing: (1) A unified benchmarking and implementation framework, Align and Distill (ALDI), enabling comparison of DAOD methods and supporting future development, (2) A fair and modern training and evaluation protocol for DAOD that addresses benchmarking pitfalls, (3) A new DAOD benchmark dataset, CFC-DAOD, enabling evaluation on diverse real-world data, and (4) A new method, ALDI++, that achieves state-of-the-art results by a large margin. ALDI++ outperforms the previous state-of-the-art by +3.5 AP50 on Cityscapes to Foggy Cityscapes, +5.7 AP50 on Sim10k to Cityscapes (where ours is the only method to outperform a fair baseline), and +2.0 AP50 on CFC Kenai to Channel. Our framework, dataset, and state-of-the-art method offer a critical reset for DAOD and provide a strong foundation for future research. Code and data are available: https://github.com/justinkay/aldi and https://github.com/visipedia/caltech-fish-counting.
The Caltech Fish Counting Dataset: A Benchmark for Multiple-Object Tracking and Counting
Jul 19, 2022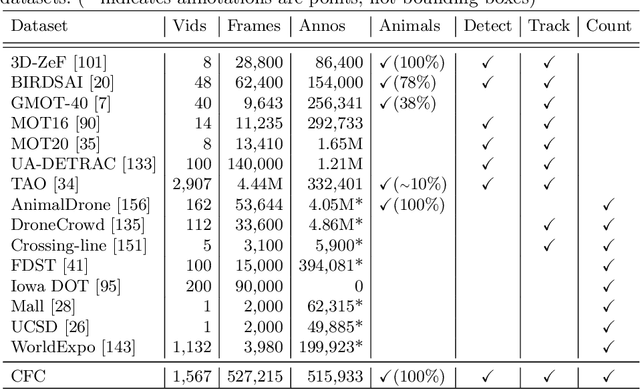
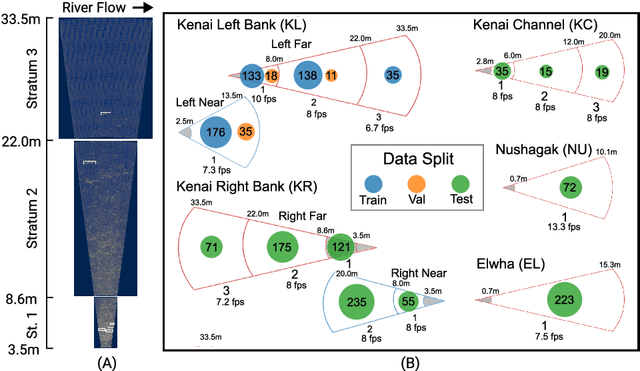
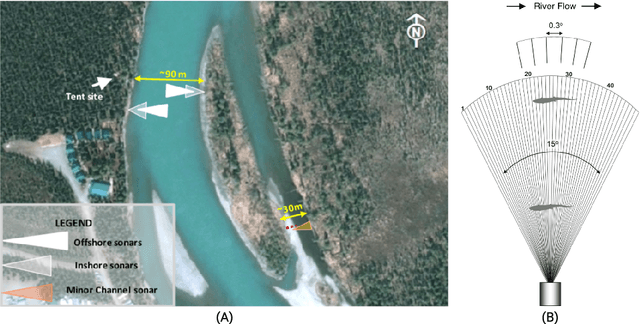

We present the Caltech Fish Counting Dataset (CFC), a large-scale dataset for detecting, tracking, and counting fish in sonar videos. We identify sonar videos as a rich source of data for advancing low signal-to-noise computer vision applications and tackling domain generalization in multiple-object tracking (MOT) and counting. In comparison to existing MOT and counting datasets, which are largely restricted to videos of people and vehicles in cities, CFC is sourced from a natural-world domain where targets are not easily resolvable and appearance features cannot be easily leveraged for target re-identification. With over half a million annotations in over 1,500 videos sourced from seven different sonar cameras, CFC allows researchers to train MOT and counting algorithms and evaluate generalization performance at unseen test locations. We perform extensive baseline experiments and identify key challenges and opportunities for advancing the state of the art in generalization in MOT and counting.