 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairRAG: Fair Human Generation via Fair Retrieval Augmentation
Apr 05, 2024



Existing text-to-image generative models reflect or even amplify societal biases ingrained in their training data. This is especially concerning for human image generation where models are biased against certain demographic groups. Existing attempts to rectify this issue are hindered by the inherent limitations of the pre-trained models and fail to substantially improve demographic diversity. In this work, we introduce Fair Retrieval Augmented Generation (FairRAG), a novel framework that conditions pre-trained generative models on reference images retrieved from an external image database to improve fairness in human generation. FairRAG enables conditioning through a lightweight linear module that projects reference images into the textual space. To enhance fairness, FairRAG applies simple-yet-effective debiasing strategies, providing images from diverse demographic groups during the generative process. Extensive experiments demonstrate that FairRAG outperforms existing methods in terms of demographic diversity, image-text alignment, and image fidelity while incurring minimal computational overhead during inference.
Align and Distill: Unifying and Improving Domain Adaptive Object Detection
Mar 18, 2024



Object detectors often perform poorly on data that differs from their training set. Domain adaptive object detection (DAOD) methods have recently demonstrated strong results on addressing this challenge. Unfortunately, we identify systemic benchmarking pitfalls that call past results into question and hamper further progress: (a) Overestimation of performance due to underpowered baselines, (b) Inconsistent implementation practices preventing transparent comparisons of methods, and (c) Lack of generality due to outdated backbones and lack of diversity in benchmarks. We address these problems by introducing: (1) A unified benchmarking and implementation framework, Align and Distill (ALDI), enabling comparison of DAOD methods and supporting future development, (2) A fair and modern training and evaluation protocol for DAOD that addresses benchmarking pitfalls, (3) A new DAOD benchmark dataset, CFC-DAOD, enabling evaluation on diverse real-world data, and (4) A new method, ALDI++, that achieves state-of-the-art results by a large margin. ALDI++ outperforms the previous state-of-the-art by +3.5 AP50 on Cityscapes to Foggy Cityscapes, +5.7 AP50 on Sim10k to Cityscapes (where ours is the only method to outperform a fair baseline), and +2.0 AP50 on CFC Kenai to Channel. Our framework, dataset, and state-of-the-art method offer a critical reset for DAOD and provide a strong foundation for future research. Code and data are available: https://github.com/justinkay/aldi and https://github.com/visipedia/caltech-fish-counting.
Balanced Filtering via Non-Disclosive Proxies
Jul 05, 2023


We study the problem of non-disclosively collecting a sample of data that is balanced with respect to sensitive groups when group membership is unavailable or prohibited from use at collection time. Specifically, our collection mechanism does not reveal significantly more about group membership of any individual sample than can be ascertained from base rates alone. To do this, we adopt a fairness pipeline perspective, in which a learner can use a small set of labeled data to train a proxy function that can later be used for this filtering task. We then associate the range of the proxy function with sampling probabilities; given a new candidate, we classify it using our proxy function, and then select it for our sample with probability proportional to the sampling probability corresponding to its proxy classification. Importantly, we require that the proxy classification itself not reveal significant information about the sensitive group membership of any individual sample (i.e., it should be sufficiently non-disclosive). We show that under modest algorithmic assumptions, we find such a proxy in a sample- and oracle-efficient manner. Finally, we experimentally evaluate our algorithm and analyze generalization properties.
Musketeer (All for One, and One for All): A Generalist Vision-Language Model with Task Explanation Prompts
May 11, 2023We present a sequence-to-sequence vision-language model whose parameters are jointly trained on all tasks (all for one) and fully shared among multiple tasks (one for all), resulting in a single model which we named Musketeer. The integration of knowledge across heterogeneous tasks is enabled by a novel feature called Task Explanation Prompt (TEP). TEP reduces interference among tasks, allowing the model to focus on their shared structure. With a single model, Musketeer achieves results comparable to or better than strong baselines trained on single tasks, almost uniformly across multiple tasks.
The Caltech Fish Counting Dataset: A Benchmark for Multiple-Object Tracking and Counting
Jul 19, 2022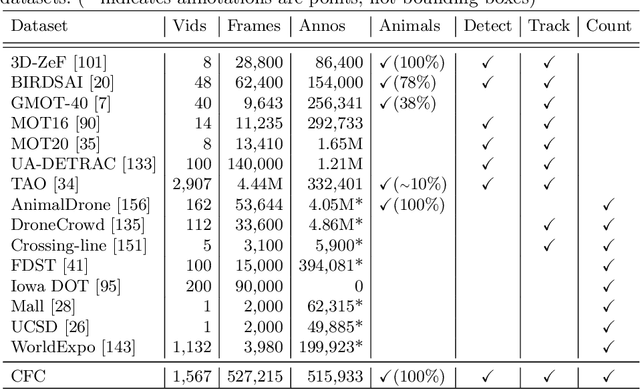
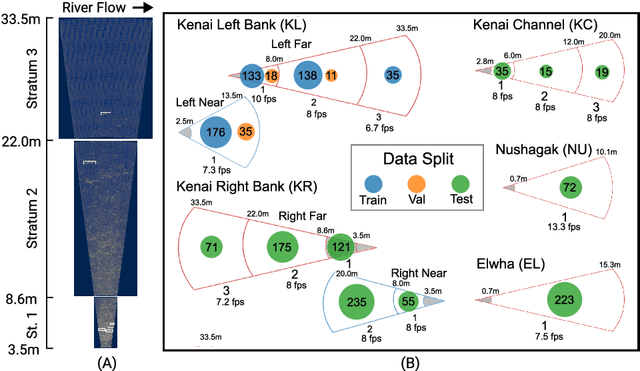
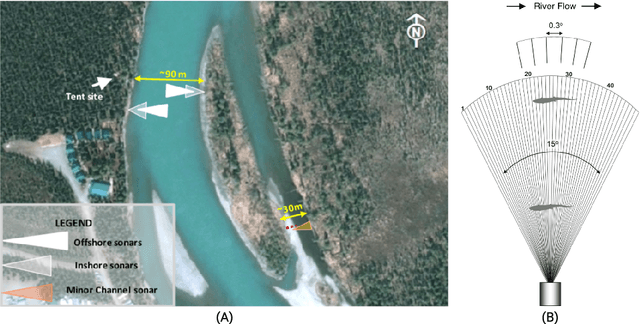

We present the Caltech Fish Counting Dataset (CFC), a large-scale dataset for detecting, tracking, and counting fish in sonar videos. We identify sonar videos as a rich source of data for advancing low signal-to-noise computer vision applications and tackling domain generalization in multiple-object tracking (MOT) and counting. In comparison to existing MOT and counting datasets, which are largely restricted to videos of people and vehicles in cities, CFC is sourced from a natural-world domain where targets are not easily resolvable and appearance features cannot be easily leveraged for target re-identification. With over half a million annotations in over 1,500 videos sourced from seven different sonar cameras, CFC allows researchers to train MOT and counting algorithms and evaluate generalization performance at unseen test locations. We perform extensive baseline experiments and identify key challenges and opportunities for advancing the state of the art in generalization in MOT and counting.
Harnessing Unrecognizable Faces for Face Recognition
Jun 08, 2021



The common implementation of face recognition systems as a cascade of a detection stage and a recognition or verification stage can cause problems beyond failures of the detector. When the detector succeeds, it can detect faces that cannot be recognized, no matter how capable the recognition system. Recognizability, a latent variable, should therefore be factored into the design and implementation of face recognition systems. We propose a measure of recognizability of a face image that leverages a key empirical observation: an embedding of face images, implemented by a deep neural network trained using mostly recognizable identities, induces a partition of the hypersphere whereby unrecognizable identities cluster together. This occurs regardless of the phenomenon that causes a face to be unrecognizable, it be optical or motion blur, partial occlusion, spatial quantization, poor illumination. Therefore, we use the distance from such an "unrecognizable identity" as a measure of recognizability, and incorporate it in the design of the over-all system. We show that accounting for recognizability reduces error rate of single-image face recognition by 58% at FAR=1e-5 on the IJB-C Covariate Verification benchmark, and reduces verification error rate by 24% at FAR=1e-5 in set-based recognition on the IJB-C benchmark.
Positive-Congruent Training: Towards Regression-Free Model Updates
Nov 20, 2020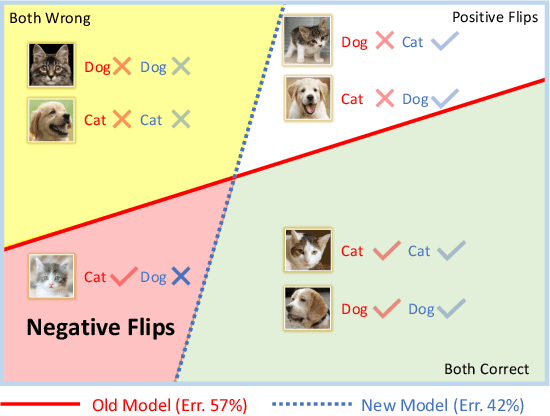
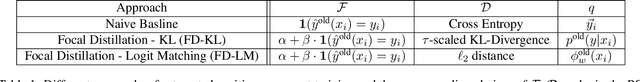
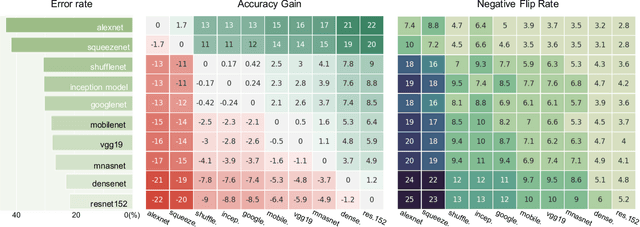
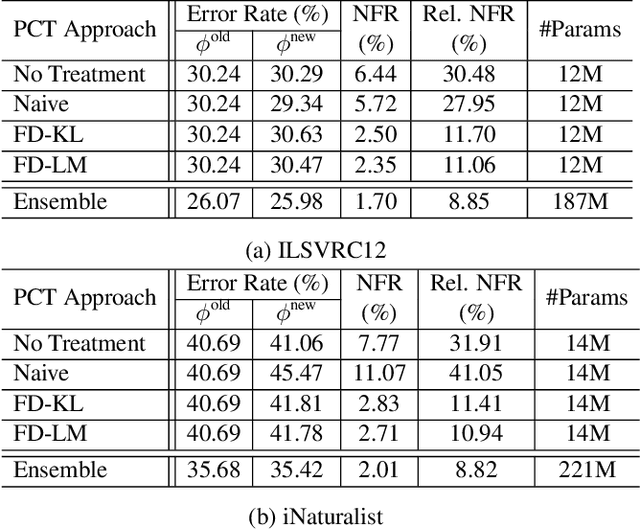
Reducing inconsistencies in the behavior of different versions of an AI system can be as important in practice as reducing its overall error. In image classification, sample-wise inconsistencies appear as "negative flips:" A new model incorrectly predicts the output for a test sample that was correctly classified by the old (reference) model. Positive-congruent (PC) training aims at reducing error rate while at the same time reducing negative flips, thus maximizing congruency with the reference model only on positive predictions, unlike model distillation. We propose a simple approach for PC training, Focal Distillation, which enforces congruence with the reference model by giving more weights to samples that were correctly classified. We also found that, if the reference model itself can be chosen as an ensemble of multiple deep neural networks, negative flips can be further reduced without affecting the new model's accuracy.
SMOT: Single-Shot Multi Object Tracking
Oct 30, 2020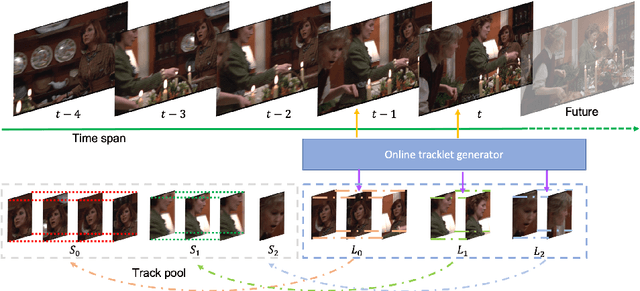
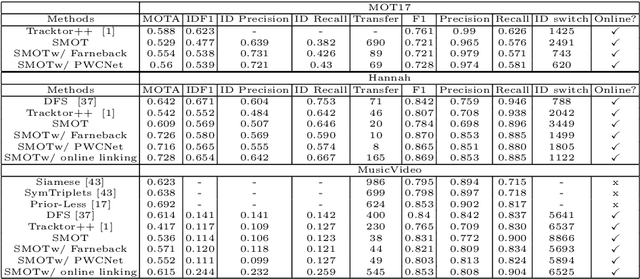
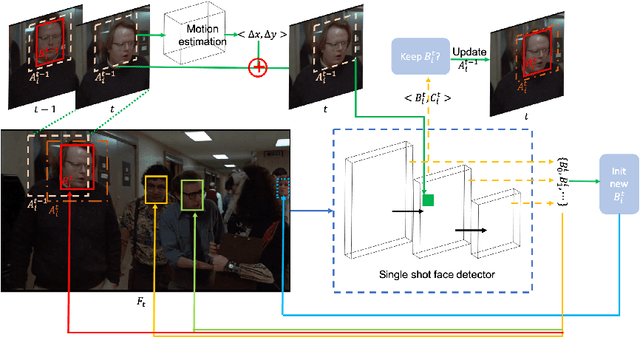
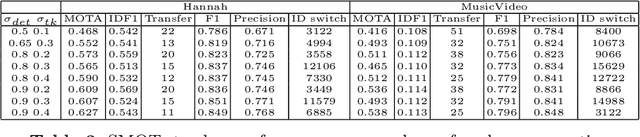
We present single-shot multi-object tracker (SMOT), a new tracking framework that converts any single-shot detector (SSD) model into an online multiple object tracker, which emphasizes simultaneously detecting and tracking of the object paths. Contrary to the existing tracking by detection approaches which suffer from errors made by the object detectors, SMOT adopts the recently proposed scheme of tracking by re-detection. We combine this scheme with SSD detectors by proposing a novel tracking anchor assignment module. With this design SMOT is able to generate tracklets with a constant per-frame runtime. A light-weighted linkage algorithm is then used for online tracklet linking. On three benchmarks of object tracking: Hannah, Music Videos, and MOT17, the proposed SMOT achieves state-of-the-art performance.