 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsensus-Driven Active Model Selection
Jul 31, 2025The widespread availability of off-the-shelf machine learning models poses a challenge: which model, of the many available candidates, should be chosen for a given data analysis task? This question of model selection is traditionally answered by collecting and annotating a validation dataset -- a costly and time-intensive process. We propose a method for active model selection, using predictions from candidate models to prioritize the labeling of test data points that efficiently differentiate the best candidate. Our method, CODA, performs consensus-driven active model selection by modeling relationships between classifiers, categories, and data points within a probabilistic framework. The framework uses the consensus and disagreement between models in the candidate pool to guide the label acquisition process, and Bayesian inference to update beliefs about which model is best as more information is collected. We validate our approach by curating a collection of 26 benchmark tasks capturing a range of model selection scenarios. CODA outperforms existing methods for active model selection significantly, reducing the annotation effort required to discover the best model by upwards of 70% compared to the previous state-of-the-art. Code and data are available at https://github.com/justinkay/coda.
Counting Fish with Temporal Representations of Sonar Video
Feb 07, 2025



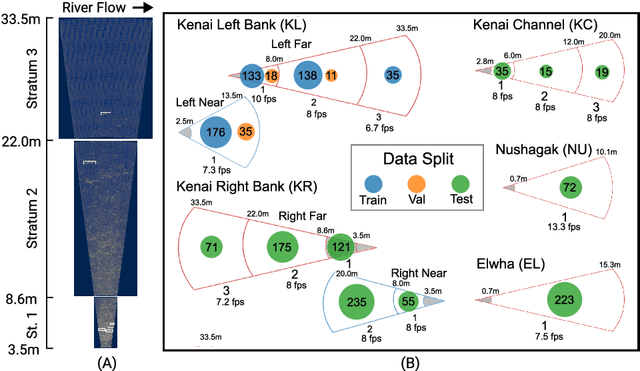
Accurate estimates of salmon escapement - the number of fish migrating upstream to spawn - are key data for conservation and fishery management. Existing methods for salmon counting using high-resolution imaging sonar hardware are non-invasive and compatible with computer vision processing. Prior work in this area has utilized object detection and tracking based methods for automated salmon counting. However, these techniques remain inaccessible to many sonar deployment sites due to limited compute and connectivity in the field. We propose an alternative lightweight computer vision method for fish counting based on analyzing echograms - temporal representations that compress several hundred frames of imaging sonar video into a single image. We predict upstream and downstream counts within 200-frame time windows directly from echograms using a ResNet-18 model, and propose a set of domain-specific image augmentations and a weakly-supervised training protocol to further improve results. We achieve a count error of 23% on representative data from the Kenai River in Alaska, demonstrating the feasibility of our approach.
Align and Distill: Unifying and Improving Domain Adaptive Object Detection
Mar 18, 2024



Object detectors often perform poorly on data that differs from their training set. Domain adaptive object detection (DAOD) methods have recently demonstrated strong results on addressing this challenge. Unfortunately, we identify systemic benchmarking pitfalls that call past results into question and hamper further progress: (a) Overestimation of performance due to underpowered baselines, (b) Inconsistent implementation practices preventing transparent comparisons of methods, and (c) Lack of generality due to outdated backbones and lack of diversity in benchmarks. We address these problems by introducing: (1) A unified benchmarking and implementation framework, Align and Distill (ALDI), enabling comparison of DAOD methods and supporting future development, (2) A fair and modern training and evaluation protocol for DAOD that addresses benchmarking pitfalls, (3) A new DAOD benchmark dataset, CFC-DAOD, enabling evaluation on diverse real-world data, and (4) A new method, ALDI++, that achieves state-of-the-art results by a large margin. ALDI++ outperforms the previous state-of-the-art by +3.5 AP50 on Cityscapes to Foggy Cityscapes, +5.7 AP50 on Sim10k to Cityscapes (where ours is the only method to outperform a fair baseline), and +2.0 AP50 on CFC Kenai to Channel. Our framework, dataset, and state-of-the-art method offer a critical reset for DAOD and provide a strong foundation for future research. Code and data are available: https://github.com/justinkay/aldi and https://github.com/visipedia/caltech-fish-counting.
Teaching Computer Vision for Ecology
Jan 05, 2023


Computer vision can accelerate ecology research by automating the analysis of raw imagery from sensors like camera traps, drones, and satellites. However, computer vision is an emerging discipline that is rarely taught to ecologists. This work discusses our experience teaching a diverse group of ecologists to prototype and evaluate computer vision systems in the context of an intensive hands-on summer workshop. We explain the workshop structure, discuss common challenges, and propose best practices. This document is intended for computer scientists who teach computer vision across disciplines, but it may also be useful to ecologists or other domain experts who are learning to use computer vision themselves.
The Caltech Fish Counting Dataset: A Benchmark for Multiple-Object Tracking and Counting
Jul 19, 2022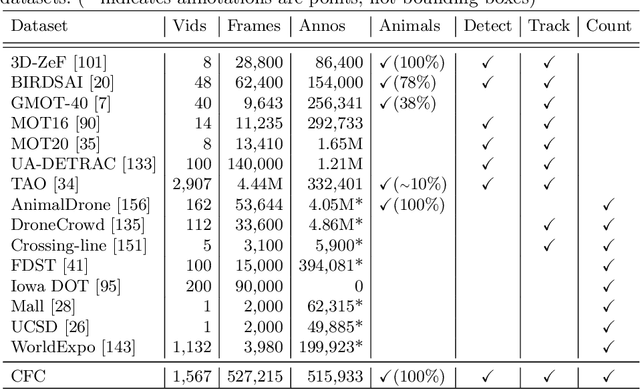
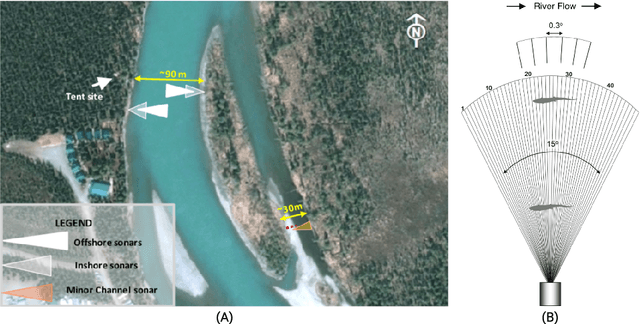

We present the Caltech Fish Counting Dataset (CFC), a large-scale dataset for detecting, tracking, and counting fish in sonar videos. We identify sonar videos as a rich source of data for advancing low signal-to-noise computer vision applications and tackling domain generalization in multiple-object tracking (MOT) and counting. In comparison to existing MOT and counting datasets, which are largely restricted to videos of people and vehicles in cities, CFC is sourced from a natural-world domain where targets are not easily resolvable and appearance features cannot be easily leveraged for target re-identification. With over half a million annotations in over 1,500 videos sourced from seven different sonar cameras, CFC allows researchers to train MOT and counting algorithms and evaluate generalization performance at unseen test locations. We perform extensive baseline experiments and identify key challenges and opportunities for advancing the state of the art in generalization in MOT and counting.
Fine-Grained Counting with Crowd-Sourced Supervision
May 30, 2022
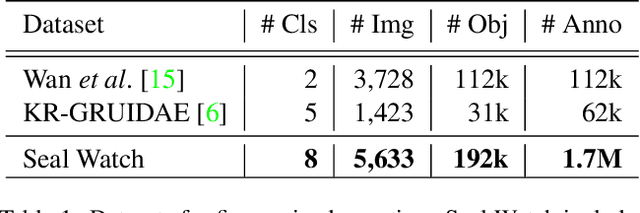

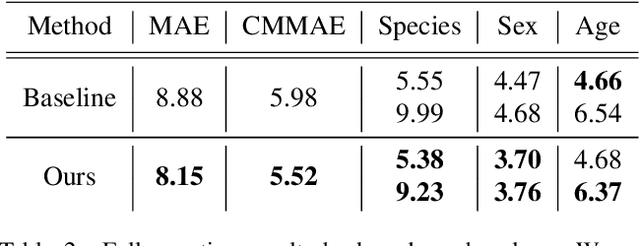
Crowd-sourcing is an increasingly popular tool for image analysis in animal ecology. Computer vision methods that can utilize crowd-sourced annotations can help scale up analysis further. In this work we study the potential to do so on the challenging task of fine-grained counting. As opposed to the standard crowd counting task, fine-grained counting also involves classifying attributes of individuals in dense crowds. We introduce a new dataset from animal ecology to enable this study that contains 1.7M crowd-sourced annotations of 8 fine-grained classes. It is the largest available dataset for fine-grained counting and the first to enable the study of the task with crowd-sourced annotations. We introduce methods for generating aggregate "ground truths" from the collected annotations, as well as a counting method that can utilize the aggregate information. Our method improves results by 8% over a comparable baseline, indicating the potential for algorithms to learn fine-grained counting using crowd-sourced supervision.
The Fishnet Open Images Database: A Dataset for Fish Detection and Fine-Grained Categorization in Fisheries
Jun 16, 2021


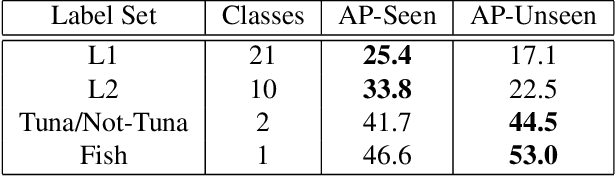
Camera-based electronic monitoring (EM) systems are increasingly being deployed onboard commercial fishing vessels to collect essential data for fisheries management and regulation. These systems generate large quantities of video data which must be reviewed on land by human experts. Computer vision can assist this process by automatically detecting and classifying fish species, however the lack of existing public data in this domain has hindered progress. To address this, we present the Fishnet Open Images Database, a large dataset of EM imagery for fish detection and fine-grained categorization onboard commercial fishing vessels. The dataset consists of 86,029 images containing 34 object classes, making it the largest and most diverse public dataset of fisheries EM imagery to-date. It includes many of the characteristic challenges of EM data: visual similarity between species, skewed class distributions, harsh weather conditions, and chaotic crew activity. We evaluate the performance of existing detection and classification algorithms and demonstrate that the dataset can serve as a challenging benchmark for development of computer vision algorithms in fisheries. The dataset is available at https://www.fishnet.ai/.