 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Mechanisms for Spatiotemporal Reasoning in Vision Language Models
Jan 18, 2026Spatio-temporal reasoning is a remarkable capability of Vision Language Models (VLMs), but the underlying mechanisms of such abilities remain largely opaque. We postulate that visual/geometrical and textual representations of spatial structure must be combined at some point in VLM computations. We search for such confluence, and ask whether the identified representation can causally explain aspects of input-output model behavior through a linear model. We show empirically that VLMs encode object locations by linearly binding \textit{spatial IDs} to textual activations, then perform reasoning via language tokens. Through rigorous causal interventions we demonstrate that these IDs, which are ubiquitous across the model, can systematically mediate model beliefs at intermediate VLM layers. Additionally, we find that spatial IDs serve as a diagnostic tool for identifying limitations in existing VLMs, and as a valuable learning signal. We extend our analysis to video VLMs and identify an analogous linear temporal ID mechanism. By characterizing our proposed spatiotemporal ID mechanism, we elucidate a previously underexplored internal reasoning process in VLMs, toward improved interpretability and the principled design of more aligned and capable models. We release our code for reproducibility: https://github.com/Raphoo/linear-mech-vlms.
Kuramoto Orientation Diffusion Models
Sep 18, 2025Orientation-rich images, such as fingerprints and textures, often exhibit coherent angular directional patterns that are challenging to model using standard generative approaches based on isotropic Euclidean diffusion. Motivated by the role of phase synchronization in biological systems, we propose a score-based generative model built on periodic domains by leveraging stochastic Kuramoto dynamics in the diffusion process. In neural and physical systems, Kuramoto models capture synchronization phenomena across coupled oscillators -- a behavior that we re-purpose here as an inductive bias for structured image generation. In our framework, the forward process performs \textit{synchronization} among phase variables through globally or locally coupled oscillator interactions and attraction to a global reference phase, gradually collapsing the data into a low-entropy von Mises distribution. The reverse process then performs \textit{desynchronization}, generating diverse patterns by reversing the dynamics with a learned score function. This approach enables structured destruction during forward diffusion and a hierarchical generation process that progressively refines global coherence into fine-scale details. We implement wrapped Gaussian transition kernels and periodicity-aware networks to account for the circular geometry. Our method achieves competitive results on general image benchmarks and significantly improves generation quality on orientation-dense datasets like fingerprints and textures. Ultimately, this work demonstrates the promise of biologically inspired synchronization dynamics as structured priors in generative modeling.
Diffusion-Based Action Recognition Generalizes to Untrained Domains
Sep 10, 2025Humans can recognize the same actions despite large context and viewpoint variations, such as differences between species (walking in spiders vs. horses), viewpoints (egocentric vs. third-person), and contexts (real life vs movies). Current deep learning models struggle with such generalization. We propose using features generated by a Vision Diffusion Model (VDM), aggregated via a transformer, to achieve human-like action recognition across these challenging conditions. We find that generalization is enhanced by the use of a model conditioned on earlier timesteps of the diffusion process to highlight semantic information over pixel level details in the extracted features. We experimentally explore the generalization properties of our approach in classifying actions across animal species, across different viewing angles, and different recording contexts. Our model sets a new state-of-the-art across all three generalization benchmarks, bringing machine action recognition closer to human-like robustness. Project page: $\href{https://www.vision.caltech.edu/actiondiff/}{\texttt{vision.caltech.edu/actiondiff}}$ Code: $\href{https://github.com/frankyaoxiao/ActionDiff}{\texttt{github.com/frankyaoxiao/ActionDiff}}$
Langevin Flows for Modeling Neural Latent Dynamics
Jul 15, 2025



Neural populations exhibit latent dynamical structures that drive time-evolving spiking activities, motivating the search for models that capture both intrinsic network dynamics and external unobserved influences. In this work, we introduce LangevinFlow, a sequential Variational Auto-Encoder where the time evolution of latent variables is governed by the underdamped Langevin equation. Our approach incorporates physical priors -- such as inertia, damping, a learned potential function, and stochastic forces -- to represent both autonomous and non-autonomous processes in neural systems. Crucially, the potential function is parameterized as a network of locally coupled oscillators, biasing the model toward oscillatory and flow-like behaviors observed in biological neural populations. Our model features a recurrent encoder, a one-layer Transformer decoder, and Langevin dynamics in the latent space. Empirically, our method outperforms state-of-the-art baselines on synthetic neural populations generated by a Lorenz attractor, closely matching ground-truth firing rates. On the Neural Latents Benchmark (NLB), the model achieves superior held-out neuron likelihoods (bits per spike) and forward prediction accuracy across four challenging datasets. It also matches or surpasses alternative methods in decoding behavioral metrics such as hand velocity. Overall, this work introduces a flexible, physics-inspired, high-performing framework for modeling complex neural population dynamics and their unobserved influences.
TARDIS STRIDE: A Spatio-Temporal Road Image Dataset for Exploration and Autonomy
Jun 12, 2025World models aim to simulate environments and enable effective agent behavior. However, modeling real-world environments presents unique challenges as they dynamically change across both space and, crucially, time. To capture these composed dynamics, we introduce a Spatio-Temporal Road Image Dataset for Exploration (STRIDE) permuting 360-degree panoramic imagery into rich interconnected observation, state and action nodes. Leveraging this structure, we can simultaneously model the relationship between egocentric views, positional coordinates, and movement commands across both space and time. We benchmark this dataset via TARDIS, a transformer-based generative world model that integrates spatial and temporal dynamics through a unified autoregressive framework trained on STRIDE. We demonstrate robust performance across a range of agentic tasks such as controllable photorealistic image synthesis, instruction following, autonomous self-control, and state-of-the-art georeferencing. These results suggest a promising direction towards sophisticated generalist agents--capable of understanding and manipulating the spatial and temporal aspects of their material environments--with enhanced embodied reasoning capabilities. Training code, datasets, and model checkpoints are made available at https://huggingface.co/datasets/Tera-AI/STRIDE.
Representational Difference Explanations
May 29, 2025We propose a method for discovering and visualizing the differences between two learned representations, enabling more direct and interpretable model comparisons. We validate our method, which we call Representational Differences Explanations (RDX), by using it to compare models with known conceptual differences and demonstrate that it recovers meaningful distinctions where existing explainable AI (XAI) techniques fail. Applied to state-of-the-art models on challenging subsets of the ImageNet and iNaturalist datasets, RDX reveals both insightful representational differences and subtle patterns in the data. Although comparison is a cornerstone of scientific analysis, current tools in machine learning, namely post hoc XAI methods, struggle to support model comparison effectively. Our work addresses this gap by introducing an effective and explainable tool for contrasting model representations.
SAVeD: Learning to Denoise Low-SNR Video for Improved Downstream Performance
Mar 31, 2025Foundation models excel at vision tasks in natural images but fail in low signal-to-noise ratio (SNR) videos, such as underwater sonar, ultrasound, and microscopy. We introduce Spatiotemporal Augmentations and denoising in Video for Downstream Tasks (SAVeD), a self-supervised method that denoises low-SNR sensor videos and is trained using only the raw noisy data. By leveraging differences in foreground and background motion, SAVeD enhances object visibility using an encoder-decoder with a temporal bottleneck. Our approach improves classification, detection, tracking, and counting, outperforming state-of-the-art video denoising methods with lower resource requirements. Project page: https://suzanne-stathatos.github.io/SAVeD Code page: https://github.com/suzanne-stathatos/SAVeD
Representational Similarity via Interpretable Visual Concepts
Mar 19, 2025How do two deep neural networks differ in how they arrive at a decision? Measuring the similarity of deep networks has been a long-standing open question. Most existing methods provide a single number to measure the similarity of two networks at a given layer, but give no insight into what makes them similar or dissimilar. We introduce an interpretable representational similarity method (RSVC) to compare two networks. We use RSVC to discover shared and unique visual concepts between two models. We show that some aspects of model differences can be attributed to unique concepts discovered by one model that are not well represented in the other. Finally, we conduct extensive evaluation across different vision model architectures and training protocols to demonstrate its effectiveness.
Is CLIP ideal? No. Can we fix it? Yes!
Mar 10, 2025

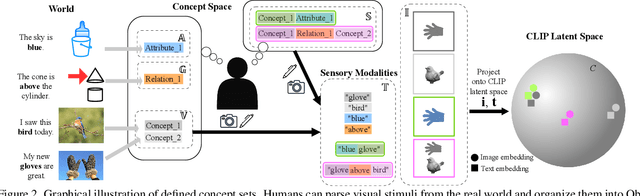
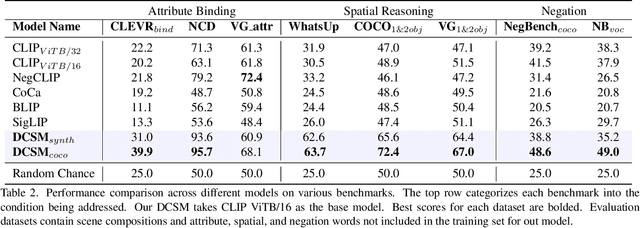
Contrastive Language-Image Pre-Training (CLIP) is a popular method for learning multimodal latent spaces with well-organized semantics. Despite its wide range of applications, CLIP's latent space is known to fail at handling complex visual-textual interactions. Recent works attempt to address its shortcomings with data-centric or algorithmic approaches. But what if the problem is more fundamental, and lies in the geometry of CLIP? Toward this end, we rigorously analyze CLIP's latent space properties, and prove that no CLIP-like joint embedding space exists which can correctly do any two of the following at the same time: 1. represent basic descriptions and image content, 2. represent attribute binding, 3. represent spatial location and relationships, 4. represent negation. Informed by this analysis, we propose Dense Cosine Similarity Maps (DCSMs) as a principled and interpretable scoring method for CLIP-like models, which solves the fundamental limitations of CLIP by retaining the semantic topology of the image patches and text tokens. This method improves upon the performance of classical CLIP-like joint encoder models on a wide array of benchmarks. We share our code and data here for reproducibility: https://github.com/Raphoo/DCSM_Ideal_CLIP
A Rapid Test for Accuracy and Bias of Face Recognition Technology
Feb 20, 2025



Measuring the accuracy of face recognition (FR) systems is essential for improving performance and ensuring responsible use. Accuracy is typically estimated using large annotated datasets, which are costly and difficult to obtain. We propose a novel method for 1:1 face verification that benchmarks FR systems quickly and without manual annotation, starting from approximate labels (e.g., from web search results). Unlike previous methods for training set label cleaning, ours leverages the embedding representation of the models being evaluated, achieving high accuracy in smaller-sized test datasets. Our approach reliably estimates FR accuracy and ranking, significantly reducing the time and cost of manual labeling. We also introduce the first public benchmark of five FR cloud services, revealing demographic biases, particularly lower accuracy for Asian women. Our rapid test method can democratize FR testing, promoting scrutiny and responsible use of the technology. Our method is provided as a publicly accessible tool at https://github.com/caltechvisionlab/frt-rapid-test