 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Mechanisms for Spatiotemporal Reasoning in Vision Language Models
Jan 18, 2026Spatio-temporal reasoning is a remarkable capability of Vision Language Models (VLMs), but the underlying mechanisms of such abilities remain largely opaque. We postulate that visual/geometrical and textual representations of spatial structure must be combined at some point in VLM computations. We search for such confluence, and ask whether the identified representation can causally explain aspects of input-output model behavior through a linear model. We show empirically that VLMs encode object locations by linearly binding \textit{spatial IDs} to textual activations, then perform reasoning via language tokens. Through rigorous causal interventions we demonstrate that these IDs, which are ubiquitous across the model, can systematically mediate model beliefs at intermediate VLM layers. Additionally, we find that spatial IDs serve as a diagnostic tool for identifying limitations in existing VLMs, and as a valuable learning signal. We extend our analysis to video VLMs and identify an analogous linear temporal ID mechanism. By characterizing our proposed spatiotemporal ID mechanism, we elucidate a previously underexplored internal reasoning process in VLMs, toward improved interpretability and the principled design of more aligned and capable models. We release our code for reproducibility: https://github.com/Raphoo/linear-mech-vlms.
Is CLIP ideal? No. Can we fix it? Yes!
Mar 10, 2025

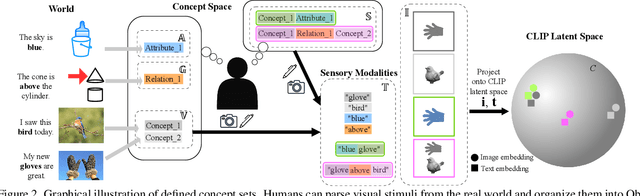
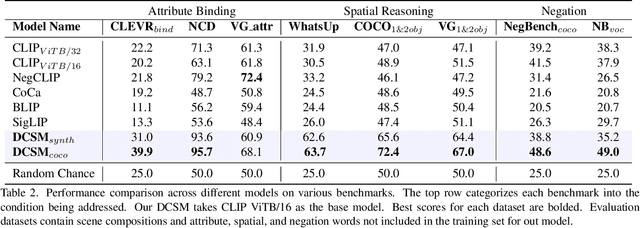
Contrastive Language-Image Pre-Training (CLIP) is a popular method for learning multimodal latent spaces with well-organized semantics. Despite its wide range of applications, CLIP's latent space is known to fail at handling complex visual-textual interactions. Recent works attempt to address its shortcomings with data-centric or algorithmic approaches. But what if the problem is more fundamental, and lies in the geometry of CLIP? Toward this end, we rigorously analyze CLIP's latent space properties, and prove that no CLIP-like joint embedding space exists which can correctly do any two of the following at the same time: 1. represent basic descriptions and image content, 2. represent attribute binding, 3. represent spatial location and relationships, 4. represent negation. Informed by this analysis, we propose Dense Cosine Similarity Maps (DCSMs) as a principled and interpretable scoring method for CLIP-like models, which solves the fundamental limitations of CLIP by retaining the semantic topology of the image patches and text tokens. This method improves upon the performance of classical CLIP-like joint encoder models on a wide array of benchmarks. We share our code and data here for reproducibility: https://github.com/Raphoo/DCSM_Ideal_CLIP