 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly supervised image segmentation for defect-based grading of fresh produce
Nov 25, 2024
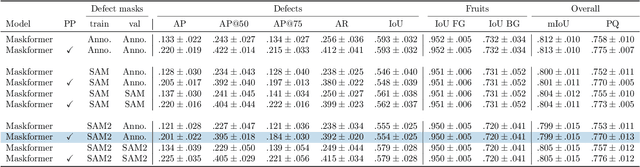
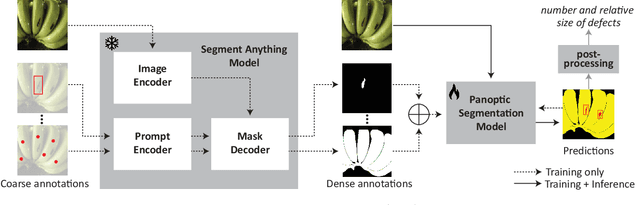
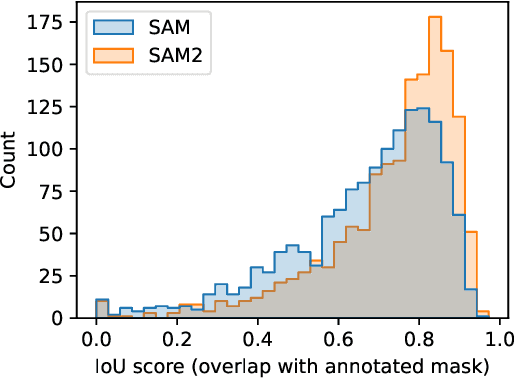
Implementing image-based machine learning in agriculture is often limited by scarce data and annotations, making it hard to achieve high-quality model predictions. This study tackles the issue of postharvest quality assessment of bananas in decentralized supply chains. We propose a method to detect and segment surface defects in banana images using panoptic segmentation to quantify defect size and number. Instead of time-consuming pixel-level annotations, we use weak supervision with coarse labels. A dataset of 476 smartphone images of bananas was collected under real-world field conditions and annotated for bruises and scars. Using the Segment Anything Model (SAM), a recently published foundation model for image segmentation, we generated dense annotations from coarse bounding boxes to train a segmentation model, significantly reducing manual effort while achieving a panoptic quality score of 77.6%. This demonstrates SAM's potential for low-effort, accurate segmentation in agricultural settings with limited data.
A Closer Look at Benchmarking Self-Supervised Pre-training with Image Classification
Jul 18, 2024



Self-supervised learning (SSL) is a machine learning approach where the data itself provides supervision, eliminating the need for external labels. The model is forced to learn about the data structure or context by solving a pretext task. With SSL, models can learn from abundant and cheap unlabeled data, significantly reducing the cost of training models where labels are expensive or inaccessible. In Computer Vision, SSL is widely used as pre-training followed by a downstream task, such as supervised transfer, few-shot learning on smaller labeled data sets, and/or unsupervised clustering. Unfortunately, it is infeasible to evaluate SSL methods on all possible downstream tasks and objectively measure the quality of the learned representation. Instead, SSL methods are evaluated using in-domain evaluation protocols, such as fine-tuning, linear probing, and k-nearest neighbors (kNN). However, it is not well understood how well these evaluation protocols estimate the representation quality of a pre-trained model for different downstream tasks under different conditions, such as dataset, metric, and model architecture. We study how classification-based evaluation protocols for SSL correlate and how well they predict downstream performance on different dataset types. Our study includes eleven common image datasets and 26 models that were pre-trained with different SSL methods or have different model backbones. We find that in-domain linear/kNN probing protocols are, on average, the best general predictors for out-of-domain performance. We further investigate the importance of batch normalization and evaluate how robust correlations are for different kinds of dataset domain shifts. We challenge assumptions about the relationship between discriminative and generative self-supervised methods, finding that most of their performance differences can be explained by changes to model backbones.
Country-Scale Cropland Mapping in Data-Scarce Settings Using Deep Learning: A Case Study of Nigeria
Dec 18, 2023Cropland maps are a core and critical component of remote-sensing-based agricultural monitoring, providing dense and up-to-date information about agricultural development. Machine learning is an effective tool for large-scale agricultural mapping, but relies on geo-referenced ground-truth data for model training and testing, which can be scarce or time-consuming to obtain. In this study, we explore the usefulness of combining a global cropland dataset and a hand-labeled dataset to train machine learning models for generating a new cropland map for Nigeria in 2020 at 10 m resolution. We provide the models with pixel-wise time series input data from remote sensing sources such as Sentinel-1 and 2, ERA5 climate data, and DEM data, in addition to binary labels indicating cropland presence. We manually labeled 1827 evenly distributed pixels across Nigeria, splitting them into 50\% training, 25\% validation, and 25\% test sets used to fit the models and test our output map. We evaluate and compare the performance of single- and multi-headed Long Short-Term Memory (LSTM) neural network classifiers, a Random Forest classifier, and three existing 10 m resolution global land cover maps (Google's Dynamic World, ESRI's Land Cover, and ESA's WorldCover) on our proposed test set. Given the regional variations in cropland appearance, we additionally experimented with excluding or sub-setting the global crowd-sourced Geowiki cropland dataset, to empirically assess the trade-off between data quantity and data quality in terms of the similarity to the target data distribution of Nigeria. We find that the existing WorldCover map performs the best with an F1-score of 0.825 and accuracy of 0.870 on the test set, followed by a single-headed LSTM model trained with our hand-labeled training samples and the Geowiki data points in Nigeria, with a F1-score of 0.814 and accuracy of 0.842.
Facilitated machine learning for image-based fruit quality assessment in developing countries
Jul 10, 2022
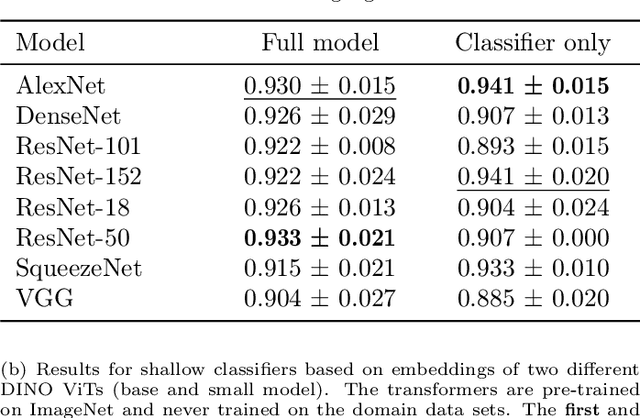
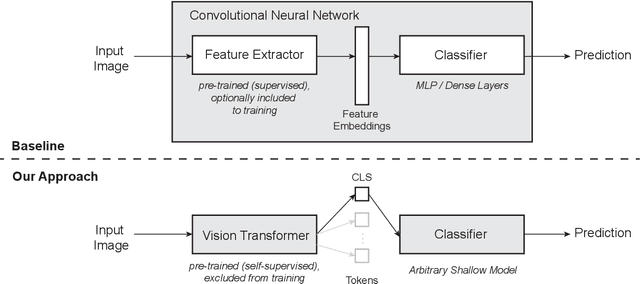
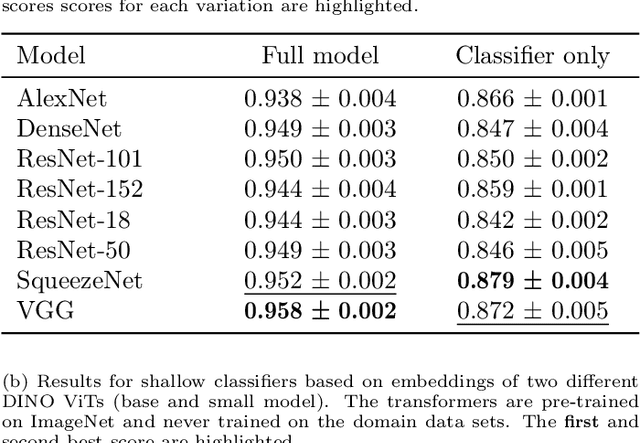
Automated image classification is a common task for supervised machine learning in food science. An example is the image-based classification of the fruit's external quality or ripeness. For this purpose, deep convolutional neural networks (CNNs) are typically used. These models usually require a large number of labeled training samples and enhanced computational resources. While commercial fruit sorting lines readily meet these requirements, the use of machine learning approaches can be hindered by these prerequisites, especially for smallholder farmers in the developing world. We propose an alternative method based on pre-trained vision transformers (ViTs) that is particularly suitable for domains with low availability of data and limited computational resources. It can be easily implemented with limited resources on a standard device, which can democratize the use of these models for smartphone-based image classification in developing countries. We demonstrate the competitiveness of our method by benchmarking two different classification tasks on domain data sets of banana and apple fruits with well-established CNN approaches. Our method achieves a classification accuracy of less than one percent below the best-performing CNN (0.950 vs. 0.958) on a training data set of 3745 images. At the same time, our method is superior when only a small number of labeled training samples is available. It requires three times less data to achieve a 0.90 accuracy compared to CNNs. In addition, visualizations of low-dimensional feature embeddings show that the model used in our study extracts excellent features from unseen data without allocating labels.
Using Machine Learning to generate an open-access cropland map from satellite images time series in the Indian Himalayan Region
Mar 28, 2022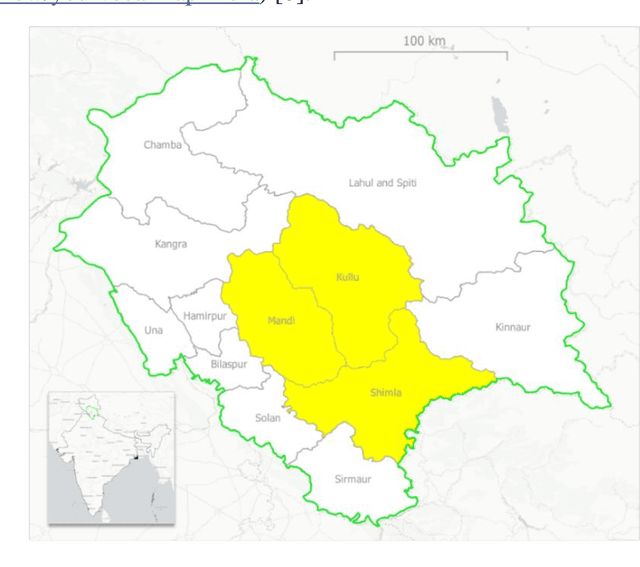
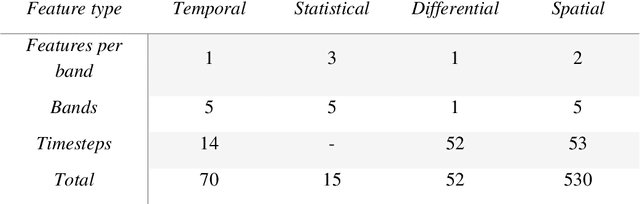
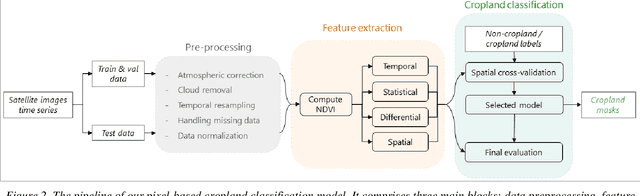
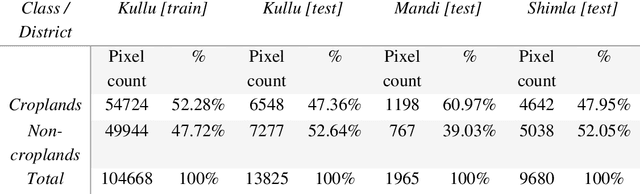
Crop maps are crucial for agricultural monitoring and food management and can additionally support domain-specific applications, such as setting cold supply chain infrastructure in developing countries. Machine learning (ML) models, combined with freely-available satellite imagery, can be used to produce cost-effective and high spatial-resolution crop maps. However, accessing ground truth data for supervised learning is especially challenging in developing countries due to factors such as smallholding and fragmented geography, which often results in a lack of crop type maps or even reliable cropland maps. Our area of interest for this study lies in Himachal Pradesh, India, where we aim at producing an open-access binary cropland map at 10-meter resolution for the Kullu, Shimla, and Mandi districts. To this end, we developed an ML pipeline that relies on Sentinel-2 satellite images time series. We investigated two pixel-based supervised classifiers, support vector machines (SVM) and random forest (RF), which are used to classify per-pixel time series for binary cropland mapping. The ground truth data used for training, validation and testing was manually annotated from a combination of field survey reference points and visual interpretation of very high resolution (VHR) imagery. We trained and validated the models via spatial cross-validation to account for local spatial autocorrelation and selected the RF model due to overall robustness and lower computational cost. We tested the generalization capability of the chosen model at the pixel level by computing the accuracy, recall, precision, and F1-score on hold-out test sets of each district, achieving an average accuracy for the RF (our best model) of 87%. We used this model to generate a cropland map for three districts of Himachal Pradesh, spanning 14,600 km2, which improves the resolution and quality of existing public maps.