 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCountry-Scale Cropland Mapping in Data-Scarce Settings Using Deep Learning: A Case Study of Nigeria
Dec 18, 2023Cropland maps are a core and critical component of remote-sensing-based agricultural monitoring, providing dense and up-to-date information about agricultural development. Machine learning is an effective tool for large-scale agricultural mapping, but relies on geo-referenced ground-truth data for model training and testing, which can be scarce or time-consuming to obtain. In this study, we explore the usefulness of combining a global cropland dataset and a hand-labeled dataset to train machine learning models for generating a new cropland map for Nigeria in 2020 at 10 m resolution. We provide the models with pixel-wise time series input data from remote sensing sources such as Sentinel-1 and 2, ERA5 climate data, and DEM data, in addition to binary labels indicating cropland presence. We manually labeled 1827 evenly distributed pixels across Nigeria, splitting them into 50\% training, 25\% validation, and 25\% test sets used to fit the models and test our output map. We evaluate and compare the performance of single- and multi-headed Long Short-Term Memory (LSTM) neural network classifiers, a Random Forest classifier, and three existing 10 m resolution global land cover maps (Google's Dynamic World, ESRI's Land Cover, and ESA's WorldCover) on our proposed test set. Given the regional variations in cropland appearance, we additionally experimented with excluding or sub-setting the global crowd-sourced Geowiki cropland dataset, to empirically assess the trade-off between data quantity and data quality in terms of the similarity to the target data distribution of Nigeria. We find that the existing WorldCover map performs the best with an F1-score of 0.825 and accuracy of 0.870 on the test set, followed by a single-headed LSTM model trained with our hand-labeled training samples and the Geowiki data points in Nigeria, with a F1-score of 0.814 and accuracy of 0.842.
Self-supervised learning unveils change in urban housing from street-level images
Sep 21, 2023



Cities around the world face a critical shortage of affordable and decent housing. Despite its critical importance for policy, our ability to effectively monitor and track progress in urban housing is limited. Deep learning-based computer vision methods applied to street-level images have been successful in the measurement of socioeconomic and environmental inequalities but did not fully utilize temporal images to track urban change as time-varying labels are often unavailable. We used self-supervised methods to measure change in London using 15 million street images taken between 2008 and 2021. Our novel adaptation of Barlow Twins, Street2Vec, embeds urban structure while being invariant to seasonal and daily changes without manual annotations. It outperformed generic embeddings, successfully identified point-level change in London's housing supply from street-level images, and distinguished between major and minor change. This capability can provide timely information for urban planning and policy decisions toward more liveable, equitable, and sustainable cities.
What You See is What You Classify: Black Box Attributions
May 23, 2022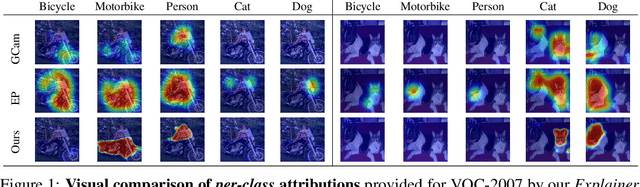
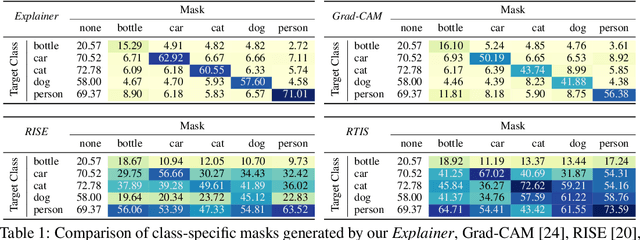
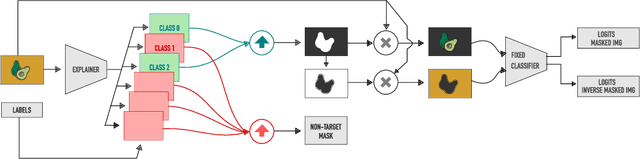
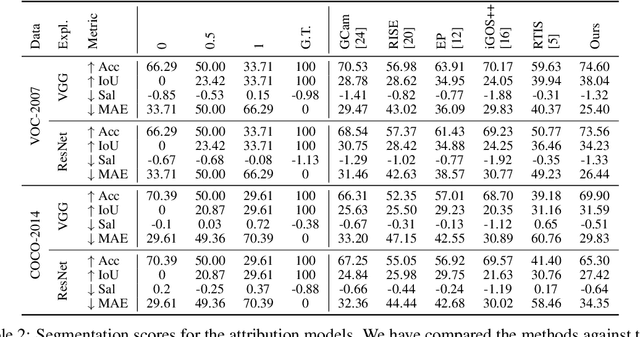
An important step towards explaining deep image classifiers lies in the identification of image regions that contribute to individual class scores in the model's output. However, doing this accurately is a difficult task due to the black-box nature of such networks. Most existing approaches find such attributions either using activations and gradients or by repeatedly perturbing the input. We instead address this challenge by training a second deep network, the Explainer, to predict attributions for a pre-trained black-box classifier, the Explanandum. These attributions are in the form of masks that only show the classifier-relevant parts of an image, masking out the rest. Our approach produces sharper and more boundary-precise masks when compared to the saliency maps generated by other methods. Moreover, unlike most existing approaches, ours is capable of directly generating very distinct class-specific masks. Finally, the proposed method is very efficient for inference since it only takes a single forward pass through the Explainer to generate all class-specific masks. We show that our attributions are superior to established methods both visually and quantitatively, by evaluating them on the PASCAL VOC-2007 and Microsoft COCO-2014 datasets.
Using Machine Learning to generate an open-access cropland map from satellite images time series in the Indian Himalayan Region
Mar 28, 2022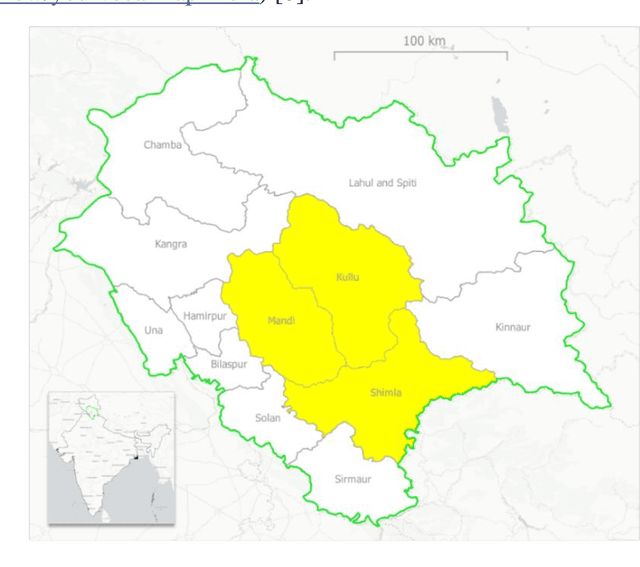
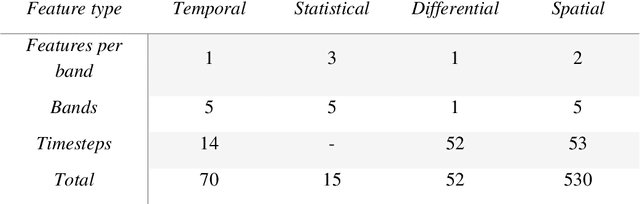
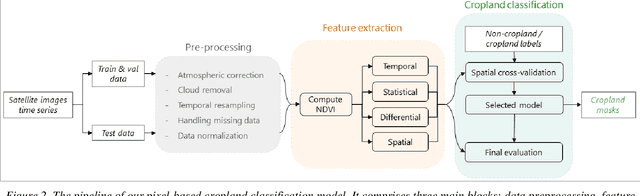
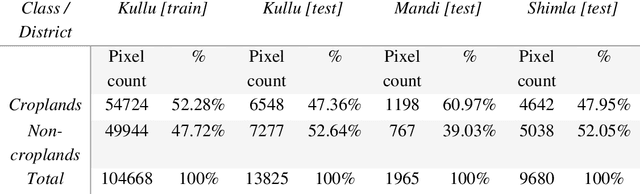
Crop maps are crucial for agricultural monitoring and food management and can additionally support domain-specific applications, such as setting cold supply chain infrastructure in developing countries. Machine learning (ML) models, combined with freely-available satellite imagery, can be used to produce cost-effective and high spatial-resolution crop maps. However, accessing ground truth data for supervised learning is especially challenging in developing countries due to factors such as smallholding and fragmented geography, which often results in a lack of crop type maps or even reliable cropland maps. Our area of interest for this study lies in Himachal Pradesh, India, where we aim at producing an open-access binary cropland map at 10-meter resolution for the Kullu, Shimla, and Mandi districts. To this end, we developed an ML pipeline that relies on Sentinel-2 satellite images time series. We investigated two pixel-based supervised classifiers, support vector machines (SVM) and random forest (RF), which are used to classify per-pixel time series for binary cropland mapping. The ground truth data used for training, validation and testing was manually annotated from a combination of field survey reference points and visual interpretation of very high resolution (VHR) imagery. We trained and validated the models via spatial cross-validation to account for local spatial autocorrelation and selected the RF model due to overall robustness and lower computational cost. We tested the generalization capability of the chosen model at the pixel level by computing the accuracy, recall, precision, and F1-score on hold-out test sets of each district, achieving an average accuracy for the RF (our best model) of 87%. We used this model to generate a cropland map for three districts of Himachal Pradesh, spanning 14,600 km2, which improves the resolution and quality of existing public maps.
Semisupervised Manifold Alignment of Multimodal Remote Sensing Images
Apr 15, 2021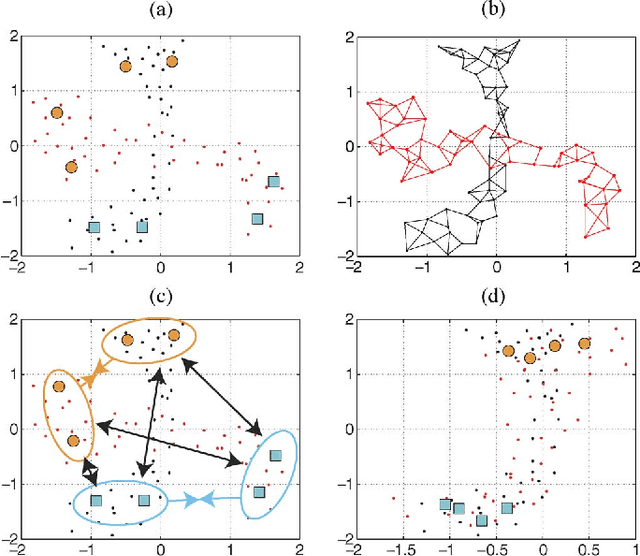
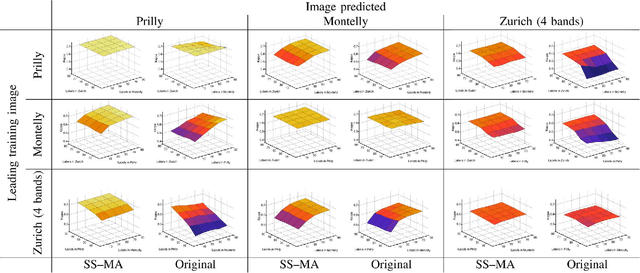
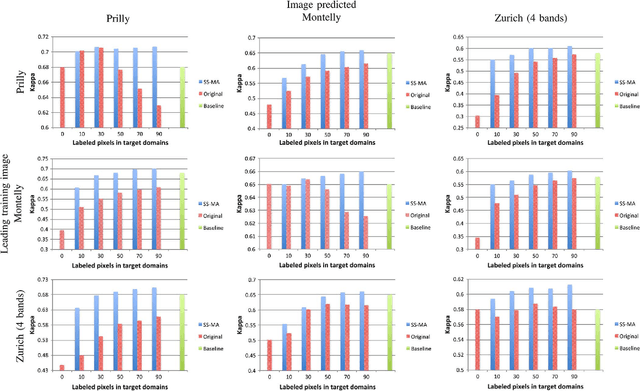

We introduce a method for manifold alignment of different modalities (or domains) of remote sensing images. The problem is recurrent when a set of multitemporal, multisource, multisensor and multiangular images is available. In these situations, images should ideally be spatially coregistred, corrected and compensated for differences in the image domains. Such procedures require the interaction of the user, involve tuning of many parameters and heuristics, and are usually applied separately. Changes of sensors and acquisition conditions translate into shifts, twists, warps and foldings of the image distributions (or manifolds). The proposed semisupervised manifold alignment (SS-MA) method aligns the images working directly on their manifolds, and is thus not restricted to images of the same resolutions, either spectral or spatial. SS-MA pulls close together samples of the same class while pushing those of different classes apart. At the same time, it preserves the geometry of each manifold along the transformation. The method builds a linear invertible transformation to a latent space where all images are alike, and reduces to solving a generalized eigenproblem of moderate size. We study the performance of SS-MA in toy examples and in real multiangular, multitemporal, and multisource image classification problems. The method performs well for strong deformations and leads to accurate classification for all domains.
A survey of active learning algorithms for supervised remote sensing image classification
Apr 15, 2021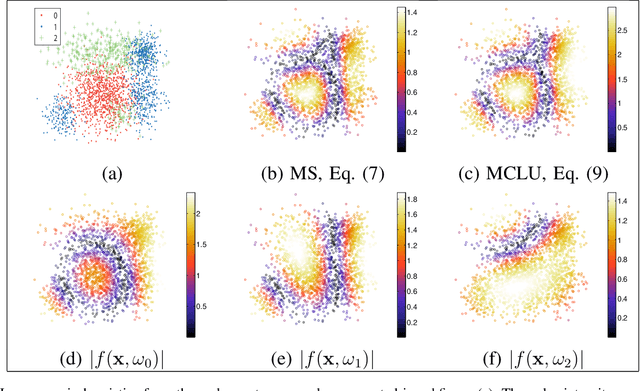
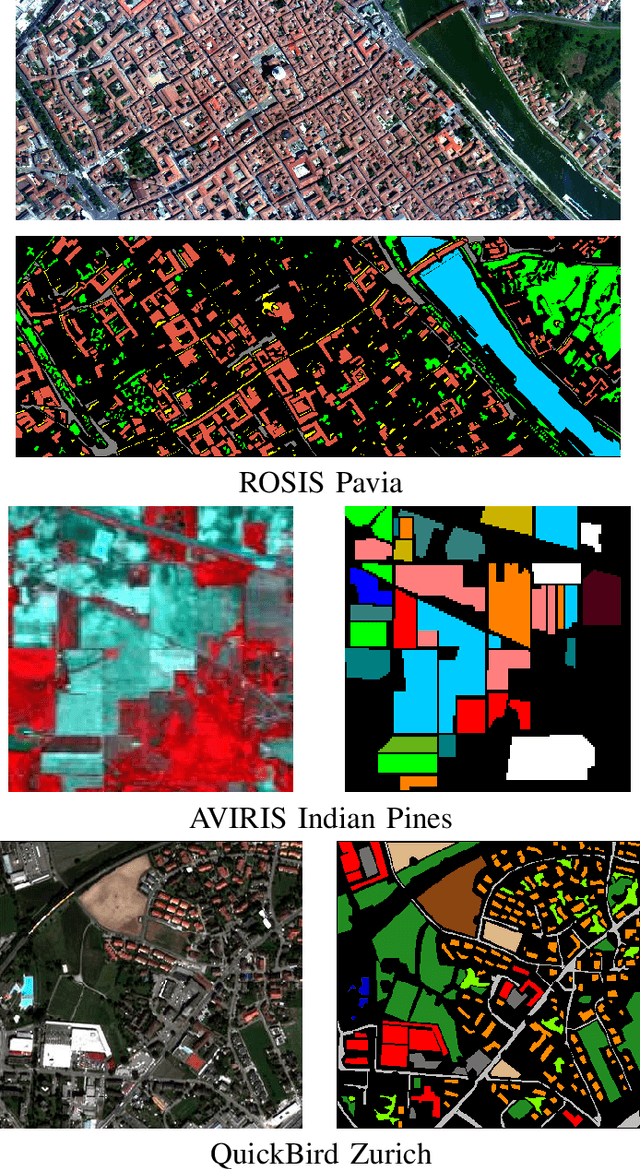
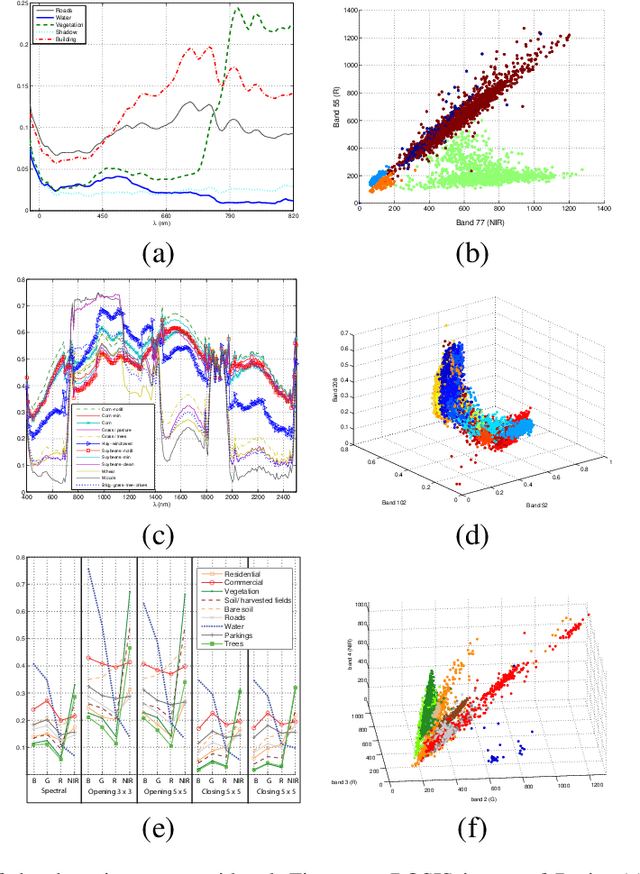
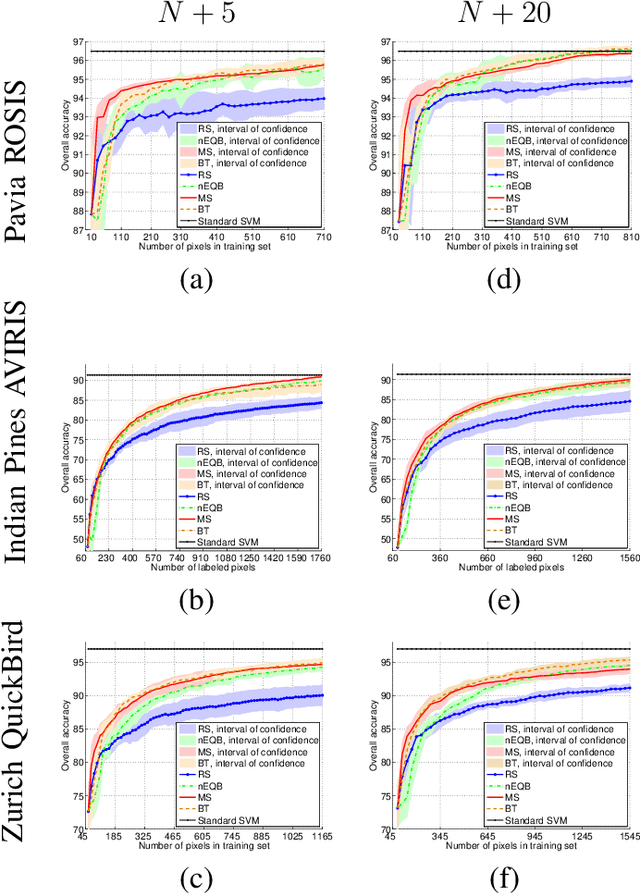
Defining an efficient training set is one of the most delicate phases for the success of remote sensing image classification routines. The complexity of the problem, the limited temporal and financial resources, as well as the high intraclass variance can make an algorithm fail if it is trained with a suboptimal dataset. Active learning aims at building efficient training sets by iteratively improving the model performance through sampling. A user-defined heuristic ranks the unlabeled pixels according to a function of the uncertainty of their class membership and then the user is asked to provide labels for the most uncertain pixels. This paper reviews and tests the main families of active learning algorithms: committee, large margin and posterior probability-based. For each of them, the most recent advances in the remote sensing community are discussed and some heuristics are detailed and tested. Several challenging remote sensing scenarios are considered, including very high spatial resolution and hyperspectral image classification. Finally, guidelines for choosing the good architecture are provided for new and/or unexperienced user.
Decision fusion with multiple spatial supports by conditional random fields
Aug 24, 2018

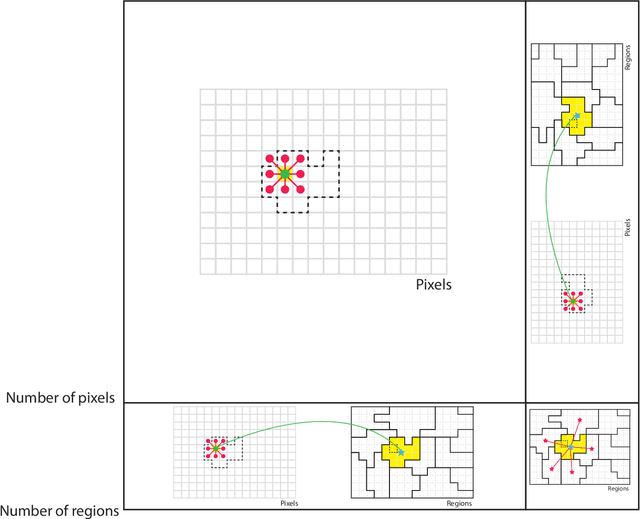

Classification of remotely sensed images into land cover or land use is highly dependent on geographical information at least at two levels. First, land cover classes are observed in a spatially smooth domain separated by sharp region boundaries. Second, land classes and observation scale are also tightly intertwined: they tend to be consistent within areas of homogeneous appearance, or regions, in the sense that all pixels within a roof should be classified as roof, independently on the spatial support used for the classification. In this paper, we follow these two observations and encode them as priors in an energy minimization framework based on conditional random fields (CRFs), where classification results obtained at pixel and region levels are probabilistically fused. The aim is to enforce the final maps to be consistent not only in their own spatial supports (pixel and region) but also across supports, i.e., by getting the predictions on the pixel lattice and on the set of regions to agree. To this end, we define an energy function with three terms: 1) a data term for the individual elements in each support (support-specific nodes); 2) spatial regularization terms in a neighborhood for each of the supports (support-specific edges); and 3) a regularization term between individual pixels and the region containing each of them (intersupports edges). We utilize these priors in a unified energy minimization problem that can be optimized by standard solvers. The proposed 2LCRF model consists of a CRF defined over a bipartite graph, i.e., two interconnected layers within a single graph accounting for interlattice connections.
Deep multi-task learning for a geographically-regularized semantic segmentation of aerial images
Aug 23, 2018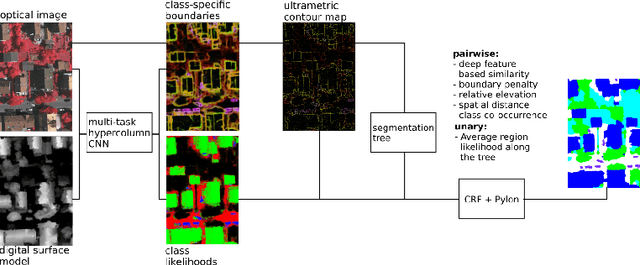
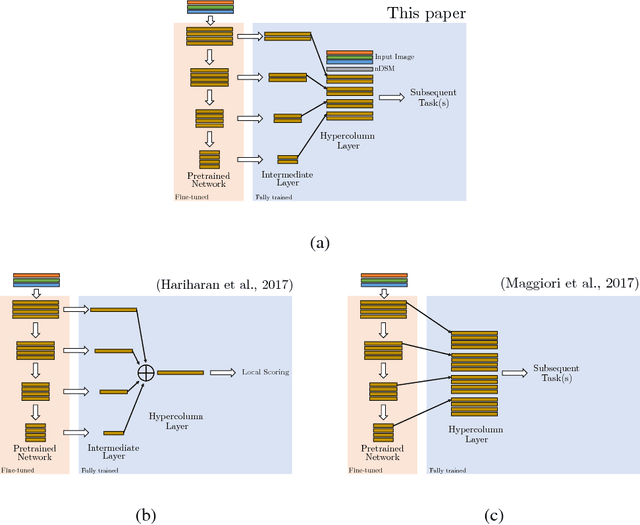
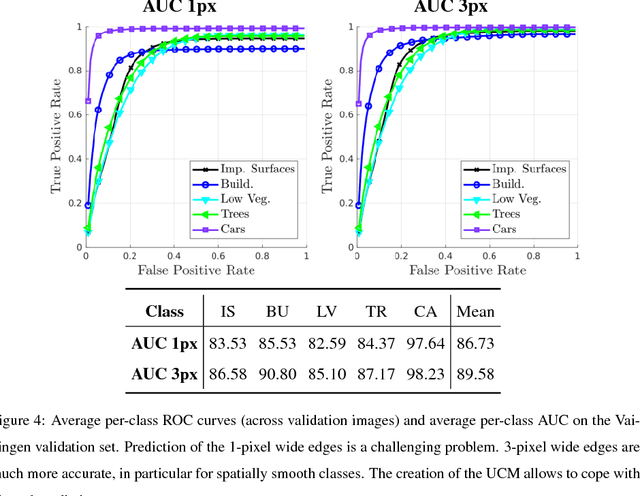
When approaching the semantic segmentation of overhead imagery in the decimeter spatial resolution range, successful strategies usually combine powerful methods to learn the visual appearance of the semantic classes (e.g. convolutional neural networks) with strategies for spatial regularization (e.g. graphical models such as conditional random fields). In this paper, we propose a method to learn evidence in the form of semantic class likelihoods, semantic boundaries across classes and shallow-to-deep visual features, each one modeled by a multi-task convolutional neural network architecture. We combine this bottom-up information with top-down spatial regularization encoded by a conditional random field model optimizing the label space across a hierarchy of segments with constraints related to structural, spatial and data-dependent pairwise relationships between regions. Our results show that such strategy provide better regularization than a series of strong baselines reflecting state-of-the-art technologies. The proposed strategy offers a flexible and principled framework to include several sources of visual and structural information, while allowing for different degrees of spatial regularization accounting for priors about the expected output structures.
Land cover mapping at very high resolution with rotation equivariant CNNs: towards small yet accurate models
Mar 16, 2018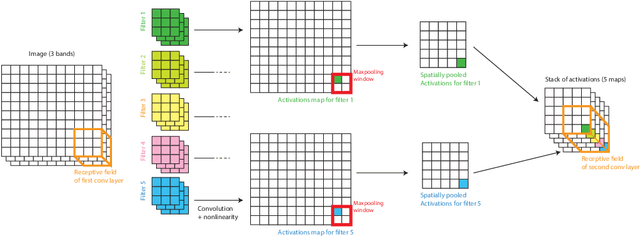
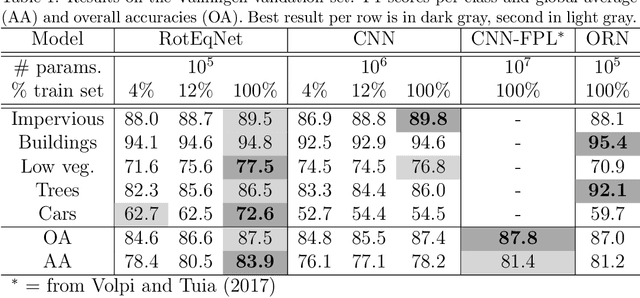
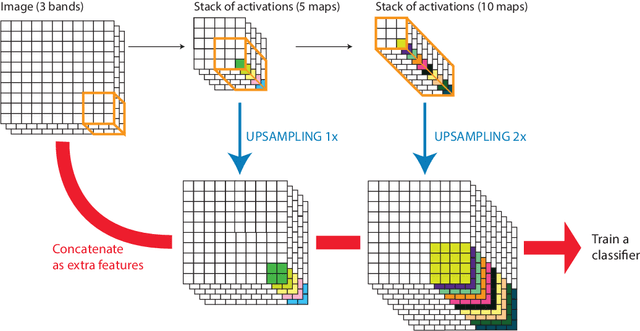
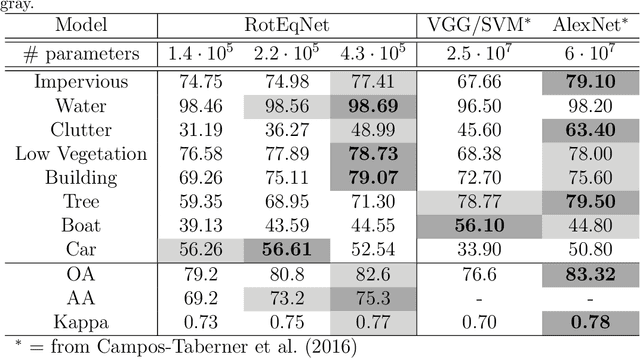
In remote sensing images, the absolute orientation of objects is arbitrary. Depending on an object's orientation and on a sensor's flight path, objects of the same semantic class can be observed in different orientations in the same image. Equivariance to rotation, in this context understood as responding with a rotated semantic label map when subject to a rotation of the input image, is therefore a very desirable feature, in particular for high capacity models, such as Convolutional Neural Networks (CNNs). If rotation equivariance is encoded in the network, the model is confronted with a simpler task and does not need to learn specific (and redundant) weights to address rotated versions of the same object class. In this work we propose a CNN architecture called Rotation Equivariant Vector Field Network (RotEqNet) to encode rotation equivariance in the network itself. By using rotating convolutions as building blocks and passing only the the values corresponding to the maximally activating orientation throughout the network in the form of orientation encoding vector fields, RotEqNet treats rotated versions of the same object with the same filter bank and therefore achieves state-of-the-art performances even when using very small architectures trained from scratch. We test RotEqNet in two challenging sub-decimeter resolution semantic labeling problems, and show that we can perform better than a standard CNN while requiring one order of magnitude less parameters.
Detecting animals in African Savanna with UAVs and the crowds
Sep 06, 2017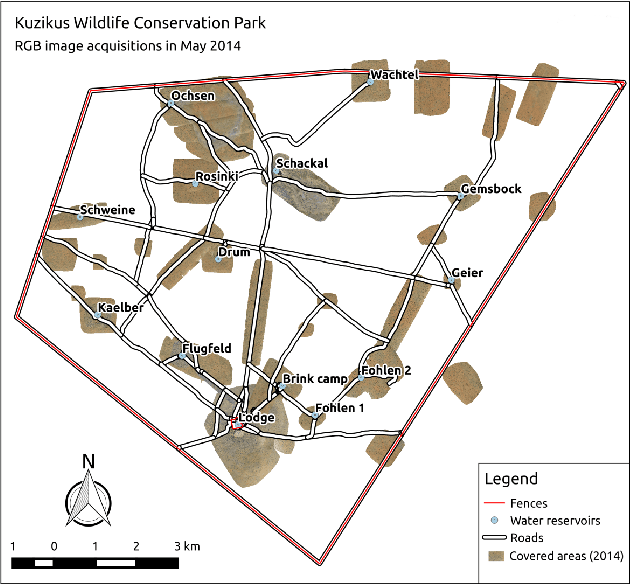


Unmanned aerial vehicles (UAVs) offer new opportunities for wildlife monitoring, with several advantages over traditional field-based methods. They have readily been used to count birds, marine mammals and large herbivores in different environments, tasks which are routinely performed through manual counting in large collections of images. In this paper, we propose a semi-automatic system able to detect large mammals in semi-arid Savanna. It relies on an animal-detection system based on machine learning, trained with crowd-sourced annotations provided by volunteers who manually interpreted sub-decimeter resolution color images. The system achieves a high recall rate and a human operator can then eliminate false detections with limited effort. Our system provides good perspectives for the development of data-driven management practices in wildlife conservation. It shows that the detection of large mammals in semi-arid Savanna can be approached by processing data provided by standard RGB cameras mounted on affordable fixed wings UAVs.