 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-temporal estimation of wind speed and wind power using machine learning: predictions, uncertainty and technical potential
Jul 29, 2021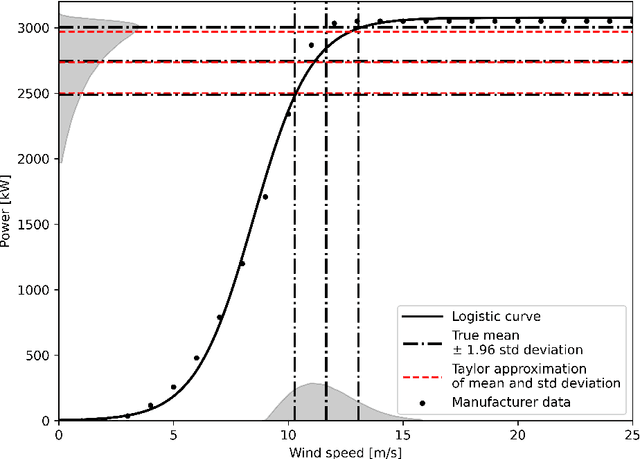
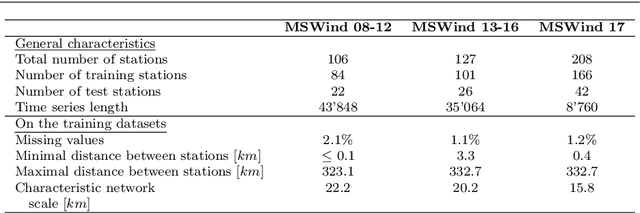
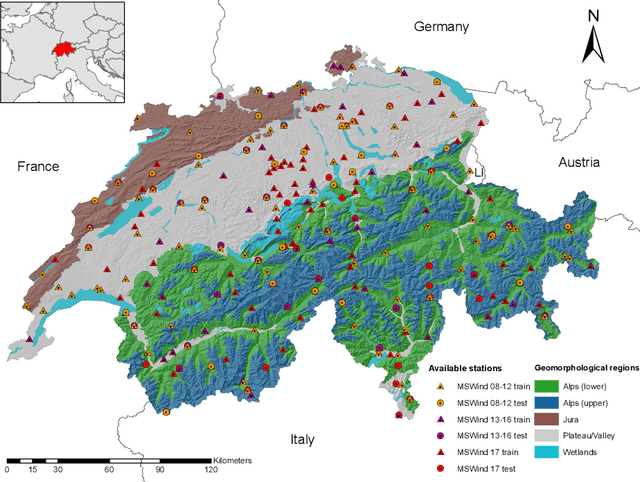
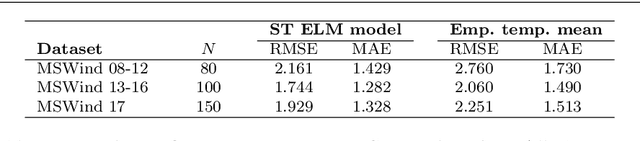
The growth of wind generation capacities in the past decades has shown that wind energy can contribute to the energy transition in many parts of the world. Being highly variable and complex to model, the quantification of the spatio-temporal variation of wind power and the related uncertainty is highly relevant for energy planners. Machine Learning has become a popular tool to perform wind-speed and power predictions. However, the existing approaches have several limitations. These include (i) insufficient consideration of spatio-temporal correlations in wind-speed data, (ii) a lack of existing methodologies to quantify the uncertainty of wind speed prediction and its propagation to the wind-power estimation, and (iii) a focus on less than hourly frequencies. To overcome these limitations, we introduce a framework to reconstruct a spatio-temporal field on a regular grid from irregularly distributed wind-speed measurements. After decomposing data into temporally referenced basis functions and their corresponding spatially distributed coefficients, the latter are spatially modelled using Extreme Learning Machines. Estimates of both model and prediction uncertainties, and of their propagation after the transformation of wind speed into wind power, are then provided without any assumptions on distribution patterns of the data. The methodology is applied to the study of hourly wind power potential on a grid of $250\times 250$ m$^2$ for turbines of 100 meters hub height in Switzerland, generating the first dataset of its type for the country. The potential wind power generation is combined with the available area for wind turbine installations to yield an estimate of the technical potential for wind power in Switzerland. The wind power estimate presented here represents an important input for planners to support the design of future energy systems with increased wind power generation.
A survey of active learning algorithms for supervised remote sensing image classification
Apr 15, 2021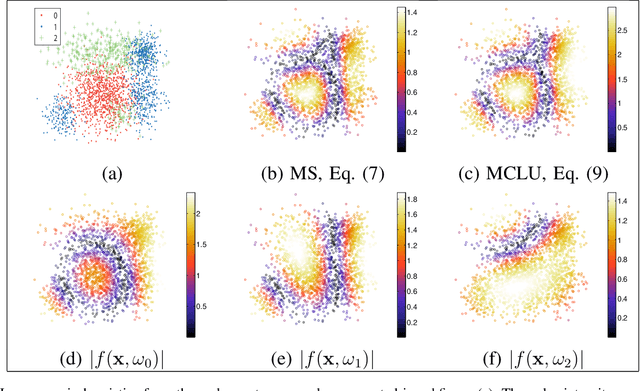
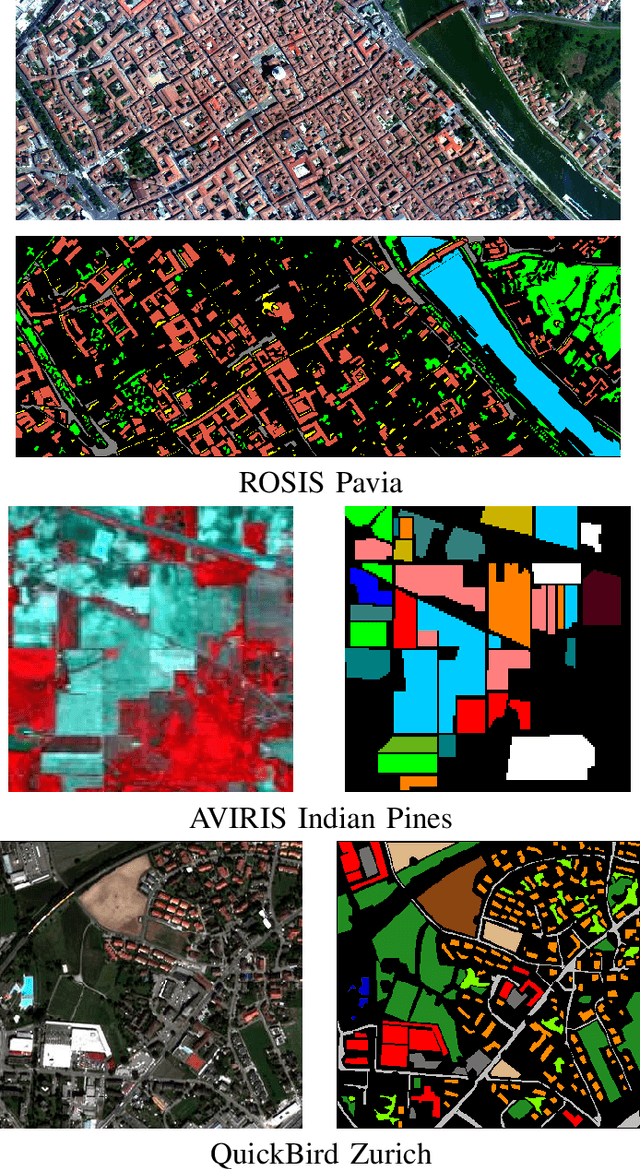
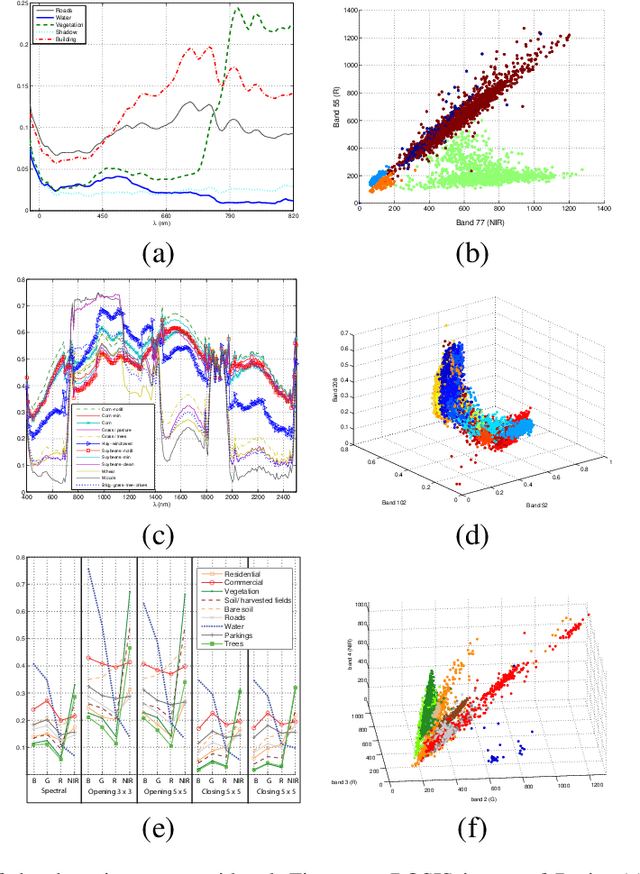
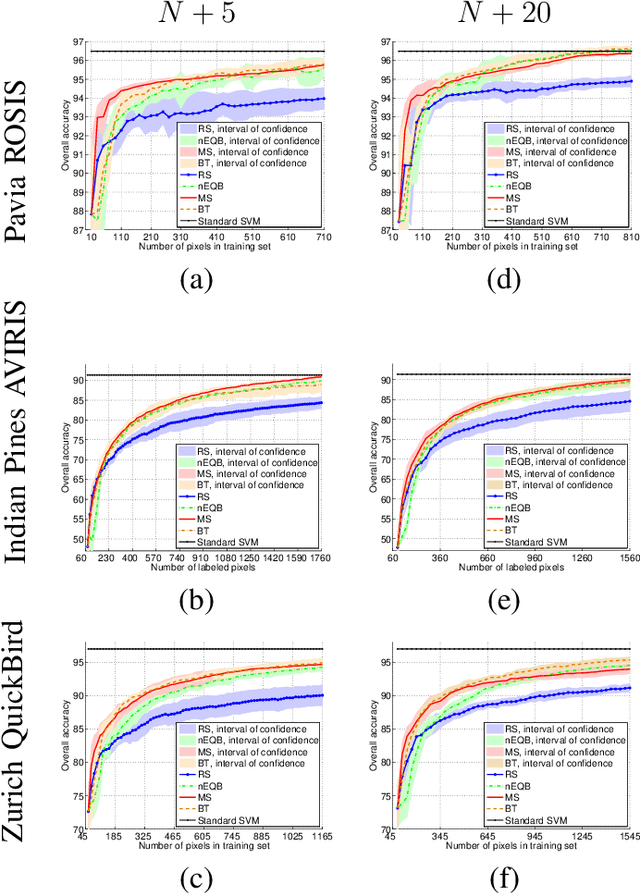
Defining an efficient training set is one of the most delicate phases for the success of remote sensing image classification routines. The complexity of the problem, the limited temporal and financial resources, as well as the high intraclass variance can make an algorithm fail if it is trained with a suboptimal dataset. Active learning aims at building efficient training sets by iteratively improving the model performance through sampling. A user-defined heuristic ranks the unlabeled pixels according to a function of the uncertainty of their class membership and then the user is asked to provide labels for the most uncertain pixels. This paper reviews and tests the main families of active learning algorithms: committee, large margin and posterior probability-based. For each of them, the most recent advances in the remote sensing community are discussed and some heuristics are detailed and tested. Several challenging remote sensing scenarios are considered, including very high spatial resolution and hyperspectral image classification. Finally, guidelines for choosing the good architecture are provided for new and/or unexperienced user.
Uncertainty Quantification in Extreme Learning Machine: Analytical Developments, Variance Estimates and Confidence Intervals
Nov 03, 2020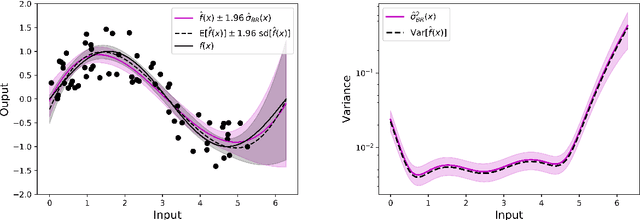
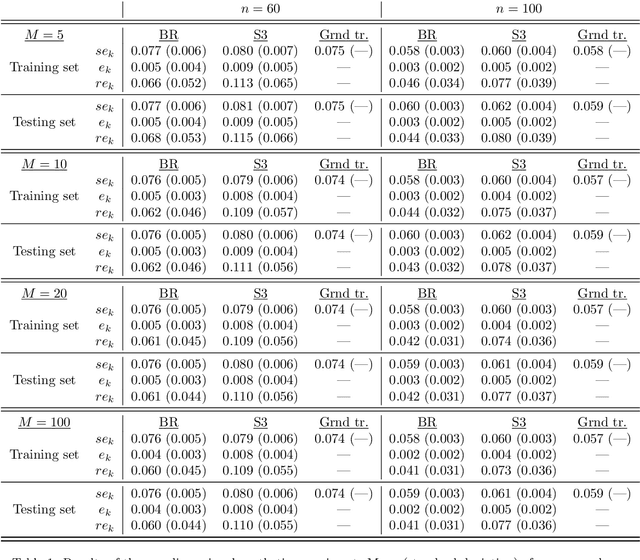
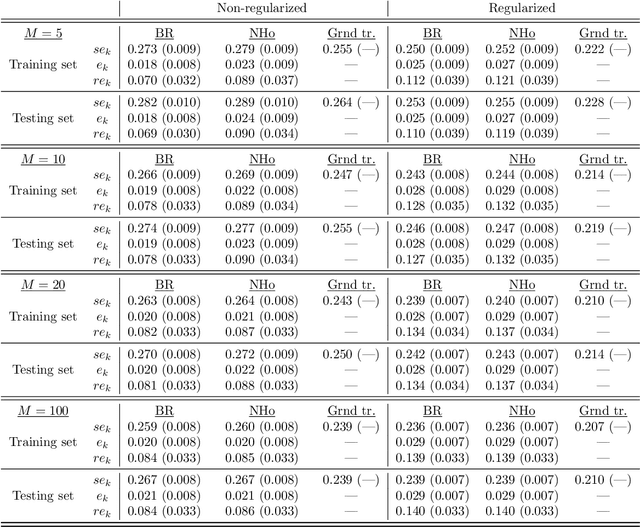
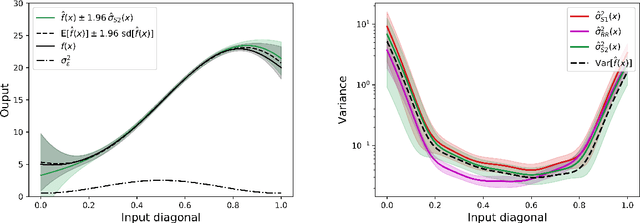
Uncertainty quantification is crucial to assess prediction quality of a machine learning model. In the case of Extreme Learning Machines (ELM), most methods proposed in the literature make strong assumptions on the data, ignore the randomness of input weights or neglect the bias contribution in confidence interval estimations. This paper presents novel estimations that overcome these constraints and improve the understanding of ELM variability. Analytical derivations are provided under general assumptions, supporting the identification and the interpretation of the contribution of different variability sources. Under both homoskedasticity and heteroskedasticity, several variance estimates are proposed, investigated, and numerically tested, showing their effectiveness in replicating the expected variance behaviours. Finally, the feasibility of confidence intervals estimation is discussed by adopting a critical approach, hence raising the awareness of ELM users concerning some of their pitfalls. The paper is accompanied with a scikit-learn compatible Python library enabling efficient computation of all estimates discussed herein.
On Feature Selection Using Anisotropic General Regression Neural Network
Oct 12, 2020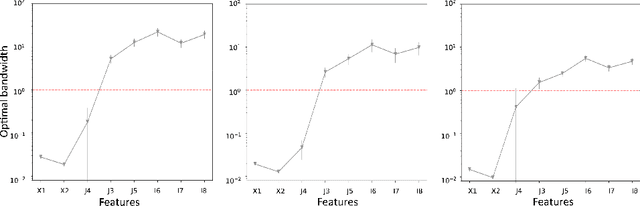

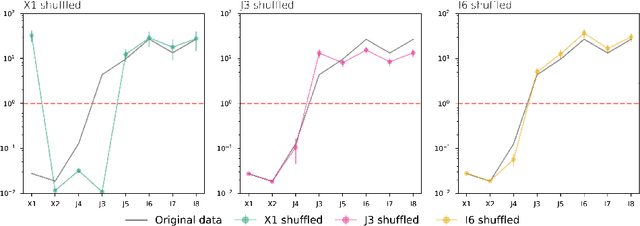
The presence of irrelevant features in the input dataset tends to reduce the interpretability and predictive quality of machine learning models. Therefore, the development of feature selection methods to recognize irrelevant features is a crucial topic in machine learning. Here we show how the General Regression Neural Network used with an anisotropic Gaussian Kernel can be used to perform feature selection. A number of numerical experiments are conducted using simulated data to study the robustness of the proposed methodology and its sensitivity to sample size. Finally, a comparison with four other feature selection methods is performed on several real world datasets.
A Novel Framework for Spatio-Temporal Prediction of Climate Data Using Deep Learning
Jul 23, 2020
As the role played by statistical and computational sciences in climate modelling and prediction becomes more important, Machine Learning researchers are becoming more aware of the relevance of their work to help tackle the climate crisis. Indeed, being universal nonlinear fucntion approximation tools, Machine Learning algorithms are efficient in analysing and modelling spatially and temporally variable climate data. While Deep Learning models have proved to be able to capture spatial, temporal, and spatio-temporal dependencies through their automatic feature representation learning, the problem of the interpolation of continuous spatio-temporal fields measured on a set of irregular points in space is still under-investigated. To fill this gap, we introduce here a framework for spatio-temporal prediction of climate and environmental data using deep learning. Specifically, we show how spatio-temporal processes can be decomposed in terms of a sum of products of temporally referenced basis functions, and of stochastic spatial coefficients which can be spatially modelled and mapped on a regular grid, allowing the reconstruction of the complete spatio-temporal signal. Applications on two case studies based on simulated and real-world data will show the effectiveness of the proposed framework in modelling coherent spatio-temporal fields.
Multifractal analysis of the time series of daily means of wind speed in complex regions
Oct 04, 2017
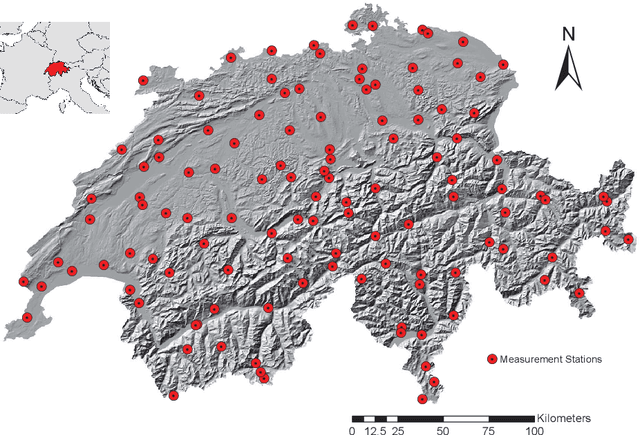
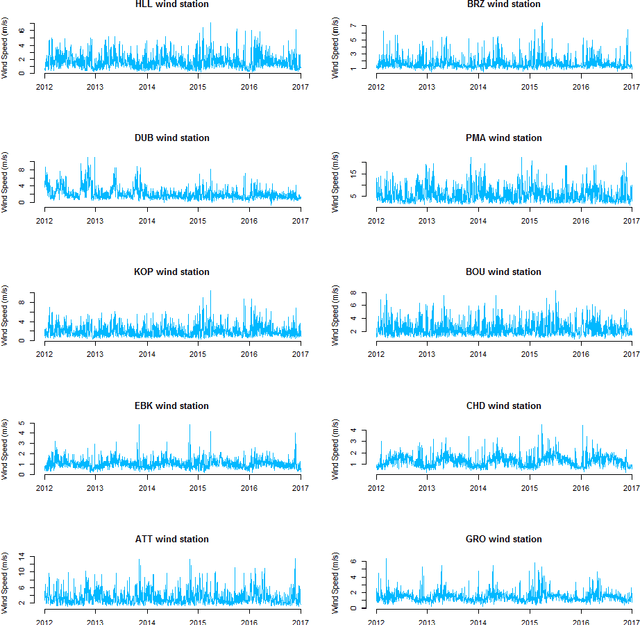
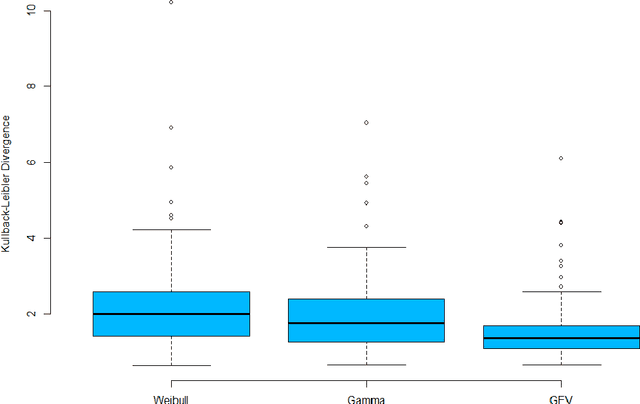
In this paper, we applied the multifractal detrended fluctuation analysis to the daily means of wind speed measured by 119 weather stations distributed over the territory of Switzerland. The analysis was focused on the inner time fluctuations of wind speed, which could be more linked with the local conditions of the highly varying topography of Switzerland. Our findings point out to a persistent behaviour of all the measured wind speed series (indicated by a Hurst exponent significantly larger than 0.5), and to a high multifractality degree indicating a relative dominance of the large fluctuations in the dynamics of wind speed, especially in the Swiss plateau, which is comprised between the Jura and Alp mountain ranges. The study represents a contribution to the understanding of the dynamical mechanisms of wind speed variability in mountainous regions.
Unsupervised Feature Selection Based on Space Filling Concept
Jun 27, 2017

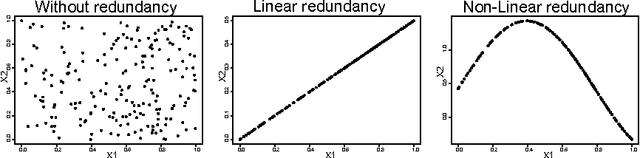

The paper deals with the adaptation of a new measure for the unsupervised feature selection problems. The proposed measure is based on space filling concept and is called the coverage measure. This measure was used for judging the quality of an experimental space filling design. In the present work, the coverage measure is adapted for selecting the smallest informative subset of variables by reducing redundancy in data. This paper proposes a simple analogy to apply this measure. It is implemented in a filter algorithm for unsupervised feature selection problems. The proposed filter algorithm is robust with high dimensional data and can be implemented without extra parameters. Further, it is tested with simulated data and real world case studies including environmental data and hyperspectral image. Finally, the results are evaluated by using random forest algorithm.
Unsupervised Feature Selection Based on the Morisita Estimator of Intrinsic Dimension
Jun 02, 2017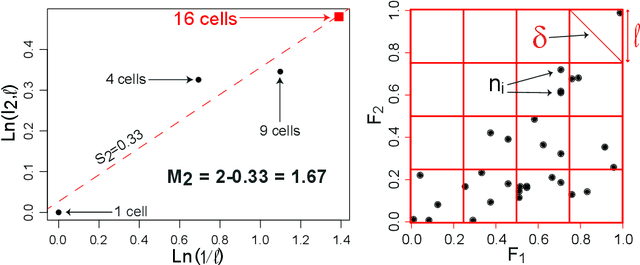

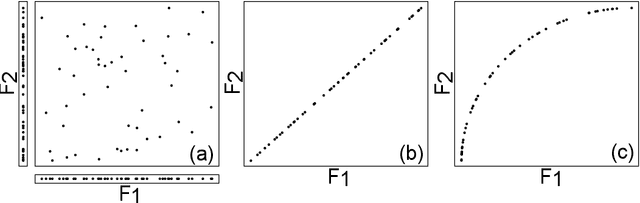
This paper deals with a new filter algorithm for selecting the smallest subset of features carrying all the information content of a data set (i.e. for removing redundant features). It is an advanced version of the fractal dimension reduction technique, and it relies on the recently introduced Morisita estimator of Intrinsic Dimension (ID). Here, the ID is used to quantify dependencies between subsets of features, which allows the effective processing of highly non-linear data. The proposed algorithm is successfully tested on simulated and real world case studies. Different levels of sample size and noise are examined along with the variability of the results. In addition, a comprehensive procedure based on random forests shows that the data dimensionality is significantly reduced by the algorithm without loss of relevant information. And finally, comparisons with benchmark feature selection techniques demonstrate the promising performance of this new filter.
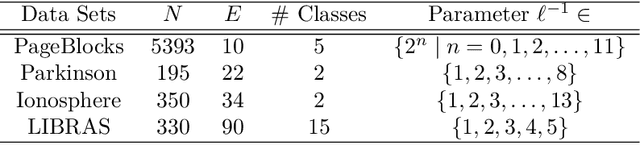
Feature Selection for Regression Problems Based on the Morisita Estimator of Intrinsic Dimension
Apr 04, 2017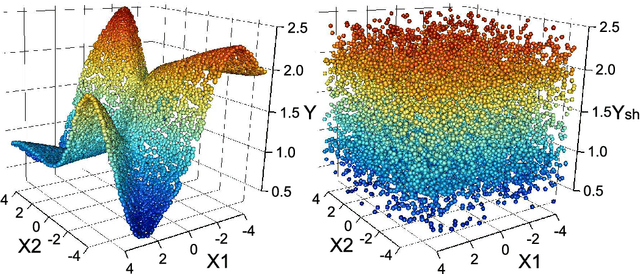


Data acquisition, storage and management have been improved, while the key factors of many phenomena are not well known. Consequently, irrelevant and redundant features artificially increase the size of datasets, which complicates learning tasks, such as regression. To address this problem, feature selection methods have been proposed. This paper introduces a new supervised filter based on the Morisita estimator of intrinsic dimension. It can identify relevant features and distinguish between redundant and irrelevant information. Besides, it offers a clear graphical representation of the results, and it can be easily implemented in different programming languages. Comprehensive numerical experiments are conducted using simulated datasets characterized by different levels of complexity, sample size and noise. The suggested algorithm is also successfully tested on a selection of real world applications and compared with RReliefF using extreme learning machine. In addition, a new measure of feature relevance is presented and discussed.