 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultifractal analysis of the time series of daily means of wind speed in complex regions
Oct 04, 2017
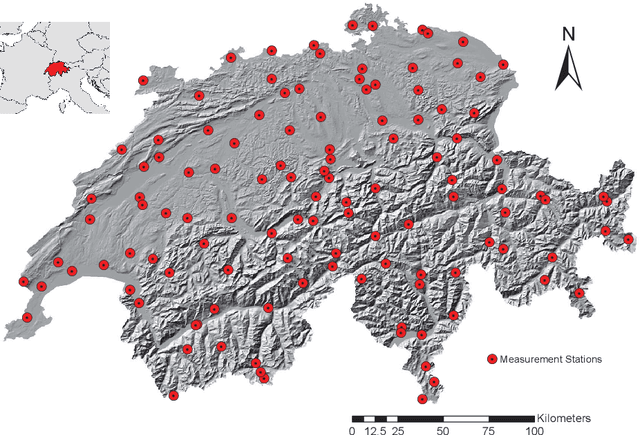
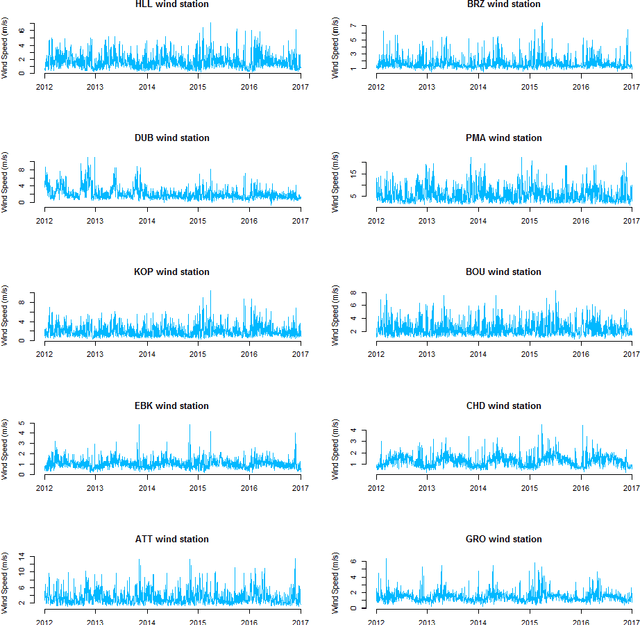
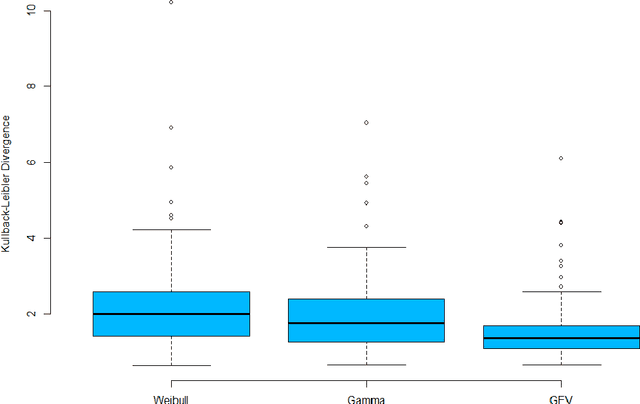
In this paper, we applied the multifractal detrended fluctuation analysis to the daily means of wind speed measured by 119 weather stations distributed over the territory of Switzerland. The analysis was focused on the inner time fluctuations of wind speed, which could be more linked with the local conditions of the highly varying topography of Switzerland. Our findings point out to a persistent behaviour of all the measured wind speed series (indicated by a Hurst exponent significantly larger than 0.5), and to a high multifractality degree indicating a relative dominance of the large fluctuations in the dynamics of wind speed, especially in the Swiss plateau, which is comprised between the Jura and Alp mountain ranges. The study represents a contribution to the understanding of the dynamical mechanisms of wind speed variability in mountainous regions.
Unsupervised Feature Selection Based on the Morisita Estimator of Intrinsic Dimension
Jun 02, 2017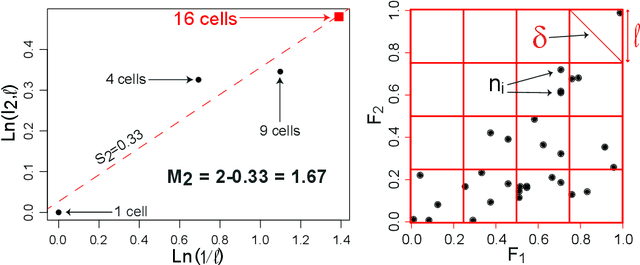

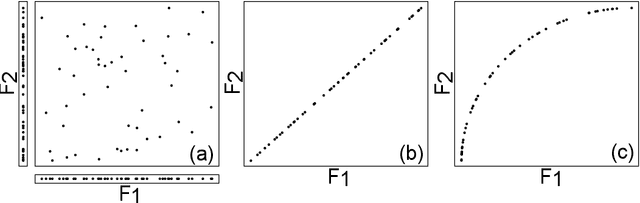
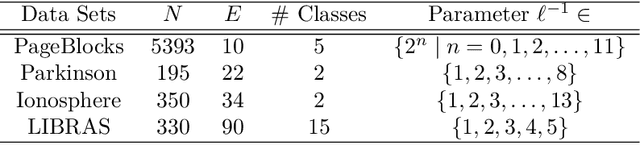
This paper deals with a new filter algorithm for selecting the smallest subset of features carrying all the information content of a data set (i.e. for removing redundant features). It is an advanced version of the fractal dimension reduction technique, and it relies on the recently introduced Morisita estimator of Intrinsic Dimension (ID). Here, the ID is used to quantify dependencies between subsets of features, which allows the effective processing of highly non-linear data. The proposed algorithm is successfully tested on simulated and real world case studies. Different levels of sample size and noise are examined along with the variability of the results. In addition, a comprehensive procedure based on random forests shows that the data dimensionality is significantly reduced by the algorithm without loss of relevant information. And finally, comparisons with benchmark feature selection techniques demonstrate the promising performance of this new filter.
Feature Selection for Regression Problems Based on the Morisita Estimator of Intrinsic Dimension
Apr 04, 2017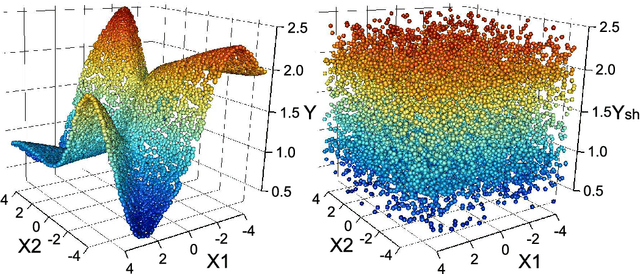
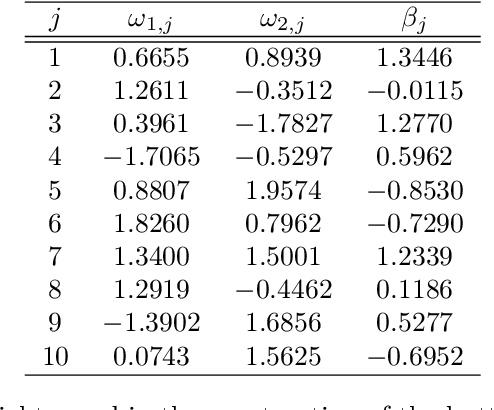


Data acquisition, storage and management have been improved, while the key factors of many phenomena are not well known. Consequently, irrelevant and redundant features artificially increase the size of datasets, which complicates learning tasks, such as regression. To address this problem, feature selection methods have been proposed. This paper introduces a new supervised filter based on the Morisita estimator of intrinsic dimension. It can identify relevant features and distinguish between redundant and irrelevant information. Besides, it offers a clear graphical representation of the results, and it can be easily implemented in different programming languages. Comprehensive numerical experiments are conducted using simulated datasets characterized by different levels of complexity, sample size and noise. The suggested algorithm is also successfully tested on a selection of real world applications and compared with RReliefF using extreme learning machine. In addition, a new measure of feature relevance is presented and discussed.