 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting the Signal-Leak Bias in Diffusion Models
Sep 27, 2023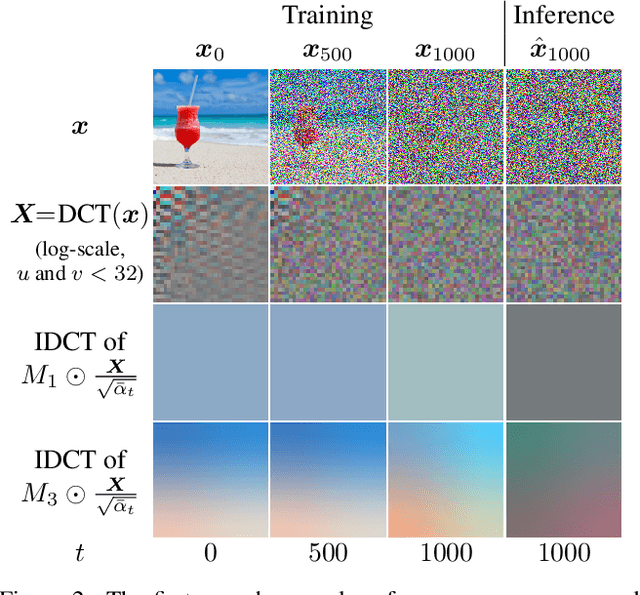



There is a bias in the inference pipeline of most diffusion models. This bias arises from a signal leak whose distribution deviates from the noise distribution, creating a discrepancy between training and inference processes. We demonstrate that this signal-leak bias is particularly significant when models are tuned to a specific style, causing sub-optimal style matching. Recent research tries to avoid the signal leakage during training. We instead show how we can exploit this signal-leak bias in existing diffusion models to allow more control over the generated images. This enables us to generate images with more varied brightness, and images that better match a desired style or color. By modeling the distribution of the signal leak in the spatial frequency and pixel domains, and including a signal leak in the initial latent, we generate images that better match expected results without any additional training.
What You See is What You Classify: Black Box Attributions
May 23, 2022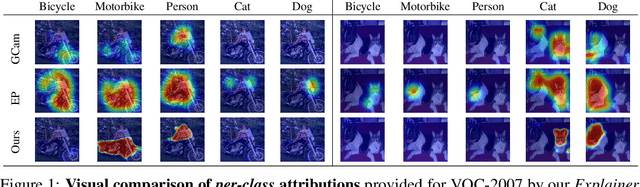
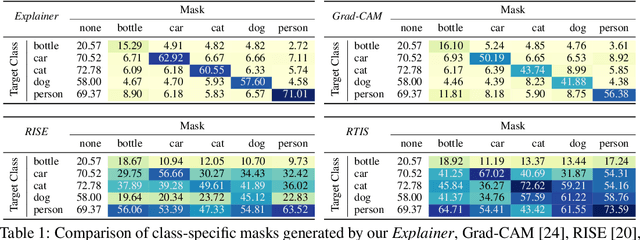
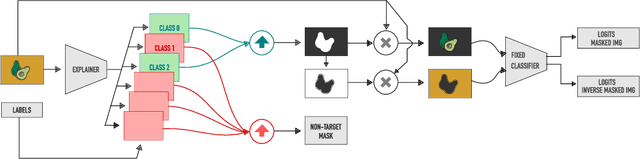
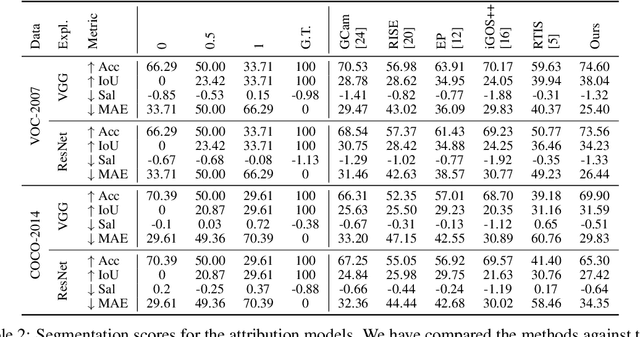
An important step towards explaining deep image classifiers lies in the identification of image regions that contribute to individual class scores in the model's output. However, doing this accurately is a difficult task due to the black-box nature of such networks. Most existing approaches find such attributions either using activations and gradients or by repeatedly perturbing the input. We instead address this challenge by training a second deep network, the Explainer, to predict attributions for a pre-trained black-box classifier, the Explanandum. These attributions are in the form of masks that only show the classifier-relevant parts of an image, masking out the rest. Our approach produces sharper and more boundary-precise masks when compared to the saliency maps generated by other methods. Moreover, unlike most existing approaches, ours is capable of directly generating very distinct class-specific masks. Finally, the proposed method is very efficient for inference since it only takes a single forward pass through the Explainer to generate all class-specific masks. We show that our attributions are superior to established methods both visually and quantitatively, by evaluating them on the PASCAL VOC-2007 and Microsoft COCO-2014 datasets.
Uncertainty Surrogates for Deep Learning
Apr 16, 2021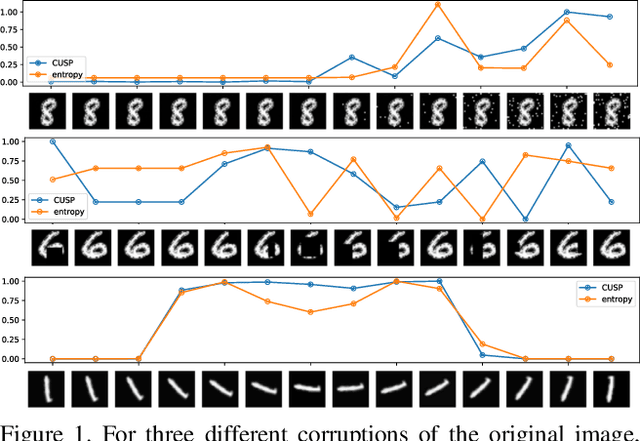



In this paper we introduce a novel way of estimating prediction uncertainty in deep networks through the use of uncertainty surrogates. These surrogates are features of the penultimate layer of a deep network that are forced to match predefined patterns. The patterns themselves can be, among other possibilities, a known visual symbol. We show how our approach can be used for estimating uncertainty in prediction and out-of-distribution detection. Additionally, the surrogates allow for interpretability of the ability of the deep network to learn and at the same time lend robustness against adversarial attacks. Despite its simplicity, our approach is superior to the state-of-the-art approaches on standard metrics as well as computational efficiency and ease of implementation. A wide range of experiments are performed on standard datasets to prove the efficacy of our approach.
Self-Binarizing Networks
Feb 02, 2019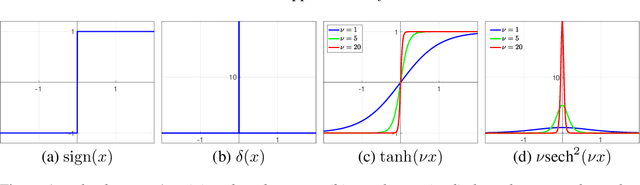
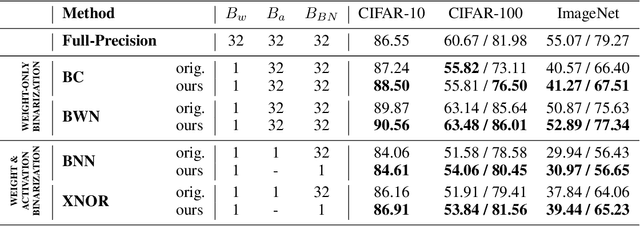
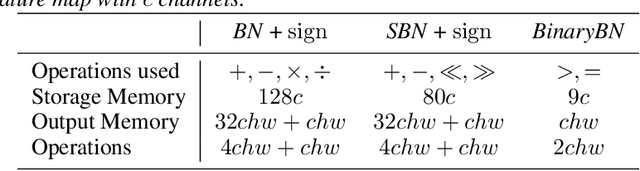
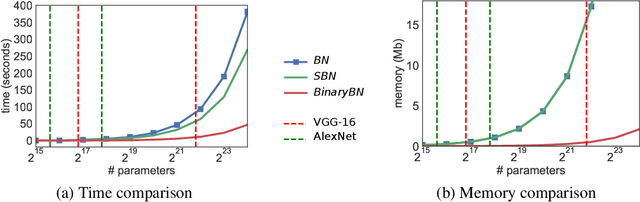
We present a method to train self-binarizing neural networks, that is, networks that evolve their weights and activations during training to become binary. To obtain similar binary networks, existing methods rely on the sign activation function. This function, however, has no gradients for non-zero values, which makes standard backpropagation impossible. To circumvent the difficulty of training a network relying on the sign activation function, these methods alternate between floating-point and binary representations of the network during training, which is sub-optimal and inefficient. We approach the binarization task by training on a unique representation involving a smooth activation function, which is iteratively sharpened during training until it becomes a binary representation equivalent to the sign activation function. Additionally, we introduce a new technique to perform binary batch normalization that simplifies the conventional batch normalization by transforming it into a simple comparison operation. This is unlike existing methods, which are forced to the retain the conventional floating-point-based batch normalization. Our binary networks, apart from displaying advantages of lower memory and computation as compared to conventional floating-point and binary networks, also show higher classification accuracy than existing state-of-the-art methods on multiple benchmark datasets.
Deep Feature Factorization For Concept Discovery
Oct 08, 2018
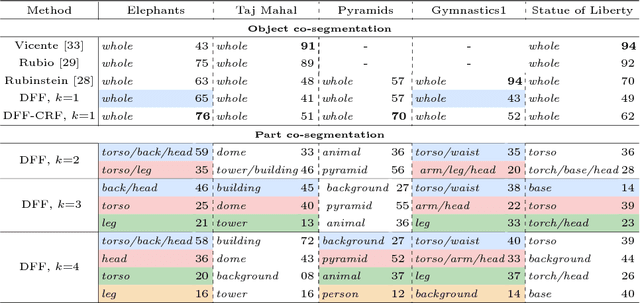
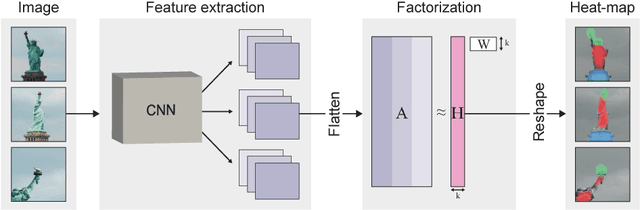
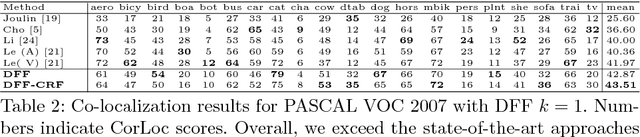
We propose Deep Feature Factorization (DFF), a method capable of localizing similar semantic concepts within an image or a set of images. We use DFF to gain insight into a deep convolutional neural network's learned features, where we detect hierarchical cluster structures in feature space. This is visualized as heat maps, which highlight semantically matching regions across a set of images, revealing what the network `perceives' as similar. DFF can also be used to perform co-segmentation and co-localization, and we report state-of-the-art results on these tasks.
Fourier-Domain Optimization for Image Processing
Sep 11, 2018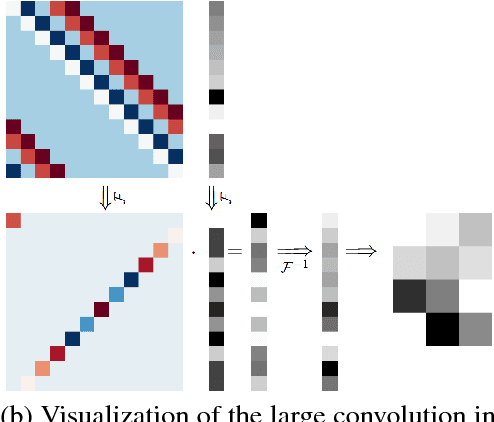
Image optimization problems encompass many applications such as spectral fusion, deblurring, deconvolution, dehazing, matting, reflection removal and image interpolation, among others. With current image sizes in the order of megabytes, it is extremely expensive to run conventional algorithms such as gradient descent, making them unfavorable especially when closed-form solutions can be derived and computed efficiently. This paper explains in detail the framework for solving convex image optimization and deconvolution in the Fourier domain. We begin by explaining the mathematical background and motivating why the presented setups can be transformed and solved very efficiently in the Fourier domain. We also show how to practically use these solutions, by providing the corresponding implementations. The explanations are aimed at a broad audience with minimal knowledge of convolution and image optimization. The eager reader can jump to Section 3 for a footprint of how to solve and implement a sample optimization function, and Section 5 for the more complex cases.
Deep Residual Network for Joint Demosaicing and Super-Resolution
Feb 19, 2018
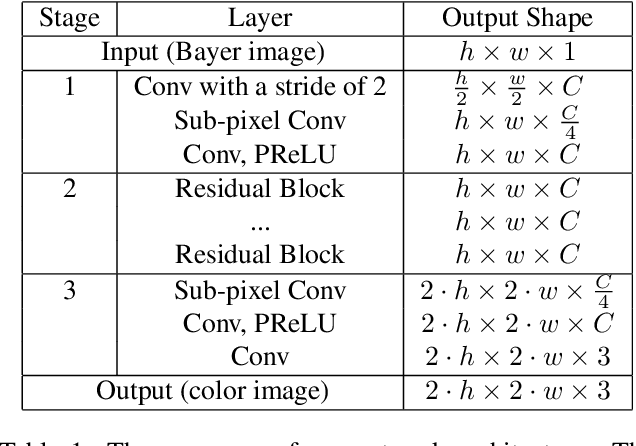


In digital photography, two image restoration tasks have been studied extensively and resolved independently: demosaicing and super-resolution. Both these tasks are related to resolution limitations of the camera. Performing super-resolution on a demosaiced images simply exacerbates the artifacts introduced by demosaicing. In this paper, we show that such accumulation of errors can be easily averted by jointly performing demosaicing and super-resolution. To this end, we propose a deep residual network for learning an end-to-end mapping between Bayer images and high-resolution images. By training on high-quality samples, our deep residual demosaicing and super-resolution network is able to recover high-quality super-resolved images from low-resolution Bayer mosaics in a single step without producing the artifacts common to such processing when the two operations are done separately. We perform extensive experiments to show that our deep residual network achieves demosaiced and super-resolved images that are superior to the state-of-the-art both qualitatively and in terms of PSNR and SSIM metrics.
Uniform Information Segmentation
Nov 27, 2016

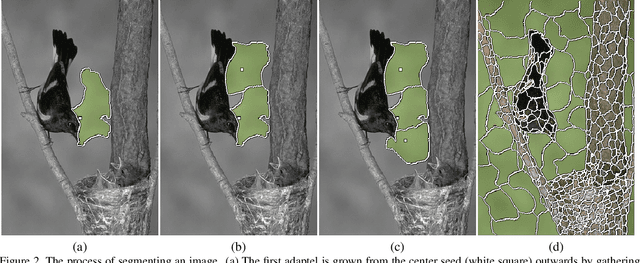

Size uniformity is one of the main criteria of superpixel methods. But size uniformity rarely conforms to the varying content of an image. The chosen size of the superpixels therefore represents a compromise - how to obtain the fewest superpixels without losing too much important detail. We propose that a more appropriate criterion for creating image segments is information uniformity. We introduce a novel method for segmenting an image based on this criterion. Since information is a natural way of measuring image complexity, our proposed algorithm leads to image segments that are smaller and denser in areas of high complexity and larger in homogeneous regions, thus simplifying the image while preserving its details. Our algorithm is simple and requires just one input parameter - a threshold on the information content. On segmentation comparison benchmarks it proves to be superior to the state-of-the-art. In addition, our method is computationally very efficient, approaching real-time performance, and is easily extensible to three-dimensional image stacks and video volumes.