 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGDA-Decoupled: Geometry-Aware Multi-Objective Optimisation for DPO-based LLM Alignment
Apr 22, 2026Aligning large language models (LLMs) to desirable human values requires balancing multiple, potentially conflicting objectives such as helpfulness, truthfulness, and harmlessness, which presents a multi-objective optimisation challenge. Most alignment pipelines rely on a fixed scalarisation of these objectives, which can introduce procedural unfairness by systematically under-weighting harder-to-optimise or minority objectives. To promote more equitable trade-offs, we introduce MGDA-Decoupled, a geometry-based multi-objective optimisation algorithm that finds a shared descent direction while explicitly accounting for each objective's convergence dynamics. In contrast to prior methods that depend on reinforcement learning (e.g., GAPO) or explicit reward models (e.g., MODPO), our approach operates entirely within the lightweight Direct Preference Optimisation (DPO) paradigm. Experiments on the UltraFeedback dataset show that geometry-aware methods -- and MGDA-Decoupled in particular -- achieve the highest win rates against golden responses, both overall and per objective.
Supervised Contrastive Block Disentanglement
Feb 11, 2025



Real-world datasets often combine data collected under different experimental conditions. This yields larger datasets, but also introduces spurious correlations that make it difficult to model the phenomena of interest. We address this by learning two embeddings to independently represent the phenomena of interest and the spurious correlations. The embedding representing the phenomena of interest is correlated with the target variable $y$, and is invariant to the environment variable $e$. In contrast, the embedding representing the spurious correlations is correlated with $e$. The invariance to $e$ is difficult to achieve on real-world datasets. Our primary contribution is an algorithm called Supervised Contrastive Block Disentanglement (SCBD) that effectively enforces this invariance. It is based purely on Supervised Contrastive Learning, and applies to real-world data better than existing approaches. We empirically validate SCBD on two challenging problems. The first problem is domain generalization, where we achieve strong performance on a synthetic dataset, as well as on Camelyon17-WILDS. We introduce a single hyperparameter $\alpha$ to control the degree of invariance to $e$. When we increase $\alpha$ to strengthen the degree of invariance, out-of-distribution performance improves at the expense of in-distribution performance. The second problem is batch correction, in which we apply SCBD to preserve biological signal and remove inter-well batch effects when modeling single-cell perturbations from 26 million Optical Pooled Screening images.
MoleCLUEs: Optimizing Molecular Conformers by Minimization of Differentiable Uncertainty
Jun 20, 2023



Structure-based models in the molecular sciences can be highly sensitive to input geometries and give predictions with large variance under subtle coordinate perturbations. We present an approach to mitigate this failure mode by generating conformations that explicitly minimize uncertainty in a predictive model. To achieve this, we compute differentiable estimates of aleatoric \textit{and} epistemic uncertainties directly from learned embeddings. We then train an optimizer that iteratively samples embeddings to reduce these uncertainties according to their gradients. As our predictive model is constructed as a variational autoencoder, the new embeddings can be decoded to their corresponding inputs, which we call \textit{MoleCLUEs}, or (molecular) counterfactual latent uncertainty explanations \citep{antoran2020getting}. We provide results of our algorithm for the task of predicting drug properties with maximum confidence as well as analysis of the differentiable structure simulations.
Vision Paper: Causal Inference for Interpretable and Robust Machine Learning in Mobility Analysis
Oct 18, 2022Artificial intelligence (AI) is revolutionizing many areas of our lives, leading a new era of technological advancement. Particularly, the transportation sector would benefit from the progress in AI and advance the development of intelligent transportation systems. Building intelligent transportation systems requires an intricate combination of artificial intelligence and mobility analysis. The past few years have seen rapid development in transportation applications using advanced deep neural networks. However, such deep neural networks are difficult to interpret and lack robustness, which slows the deployment of these AI-powered algorithms in practice. To improve their usability, increasing research efforts have been devoted to developing interpretable and robust machine learning methods, among which the causal inference approach recently gained traction as it provides interpretable and actionable information. Moreover, most of these methods are developed for image or sequential data which do not satisfy specific requirements of mobility data analysis. This vision paper emphasizes research challenges in deep learning-based mobility analysis that require interpretability and robustness, summarizes recent developments in using causal inference for improving the interpretability and robustness of machine learning methods, and highlights opportunities in developing causally-enabled machine learning models tailored for mobility analysis. This research direction will make AI in the transportation sector more interpretable and reliable, thus contributing to safer, more efficient, and more sustainable future transportation systems.
Uncertainty Surrogates for Deep Learning
Apr 16, 2021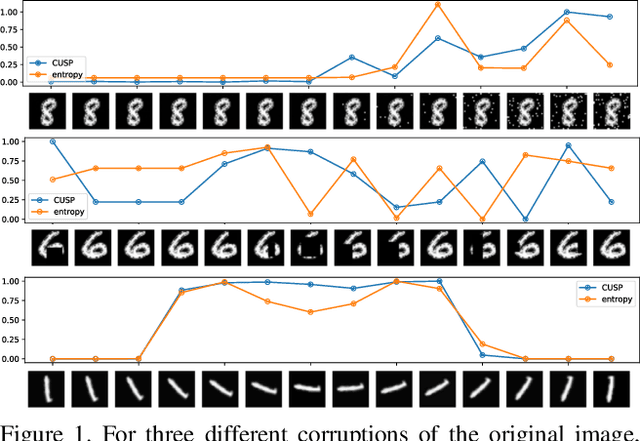



In this paper we introduce a novel way of estimating prediction uncertainty in deep networks through the use of uncertainty surrogates. These surrogates are features of the penultimate layer of a deep network that are forced to match predefined patterns. The patterns themselves can be, among other possibilities, a known visual symbol. We show how our approach can be used for estimating uncertainty in prediction and out-of-distribution detection. Additionally, the surrogates allow for interpretability of the ability of the deep network to learn and at the same time lend robustness against adversarial attacks. Despite its simplicity, our approach is superior to the state-of-the-art approaches on standard metrics as well as computational efficiency and ease of implementation. A wide range of experiments are performed on standard datasets to prove the efficacy of our approach.
Copulas as High-Dimensional Generative Models: Vine Copula Autoencoders
Jun 12, 2019



We propose a vine copula autoencoder to construct flexible generative models for high-dimensional distributions in a straightforward three-step procedure. First, an autoencoder compresses the data using a lower dimensional representation. Second, the multivariate distribution of the encoded data is estimated with vine copulas. Third, a generative model is obtained by combining the estimated distribution with the decoder part of the autoencoder. This approach can transform any already trained autoencoder into a flexible generative model at a low computational cost. This is an advantage over existing generative models such as adversarial networks and variational autoencoders which can be difficult to train and can impose strong assumptions on the latent space. Experiments on MNIST, Street View House Numbers and Large-Scale CelebFaces Attributes datasets show that vine copulas autoencoders can achieve competitive results to standard baselines.
Deep Smoothing of the Implied Volatility Surface
Jun 12, 2019


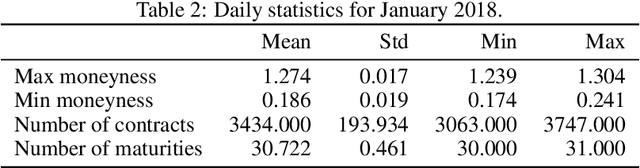
We present an artificial neural network (ANN) approach to value financial derivatives. Atypically to standard ANN applications, practitioners equally use option pricing models to validate market prices and to infer unobserved prices. Importantly, models need to generate realistic arbitrage-free prices, meaning that no option portfolio can lead to risk-free profits. The absence of arbitrage opportunities is guaranteed by penalizing the loss using soft constraints on an extended grid of input values. ANNs can be pre-trained by first calibrating a standard option pricing model, and then training an ANN to a larger synthetic dataset generated from the calibrated model. The parameters transfer as well as the non-arbitrage constraints appear to be particularly useful when only sparse or erroneous data are available. We also explore how deeper ANNs improve over shallower ones, as well as other properties of the network architecture. We benchmark our method against standard option pricing models, such as Heston with and without jumps. We validate our method both on training sets, and testing sets, namely, highlighting both their capacity to reproduce observed prices and predict new ones.
Generative Models for Simulating Mobility Trajectories
Nov 30, 2018

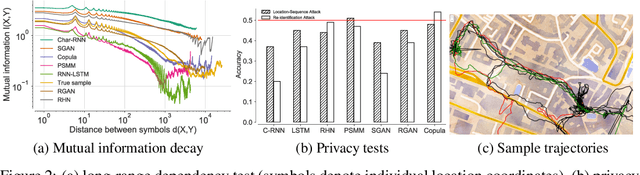

Mobility datasets are fundamental for evaluating algorithms pertaining to geographic information systems and facilitating experimental reproducibility. But privacy implications restrict sharing such datasets, as even aggregated location-data is vulnerable to membership inference attacks. Current synthetic mobility dataset generators attempt to superficially match a priori modeled mobility characteristics which do not accurately reflect the real-world characteristics. Modeling human mobility to generate synthetic yet semantically and statistically realistic trajectories is therefore crucial for publishing trajectory datasets having satisfactory utility level while preserving user privacy. Specifically, long-range dependencies inherent to human mobility are challenging to capture with both discriminative and generative models. In this paper, we benchmark the performance of recurrent neural architectures (RNNs), generative adversarial networks (GANs) and nonparametric copulas to generate synthetic mobility traces. We evaluate the generated trajectories with respect to their geographic and semantic similarity, circadian rhythms, long-range dependencies, training and generation time. We also include two sample tests to assess statistical similarity between the observed and simulated distributions, and we analyze the privacy tradeoffs with respect to membership inference and location-sequence attacks.
Frequentist uncertainty estimates for deep learning
Nov 02, 2018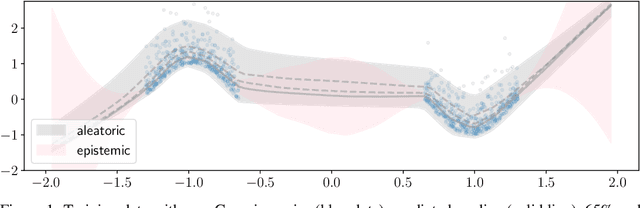
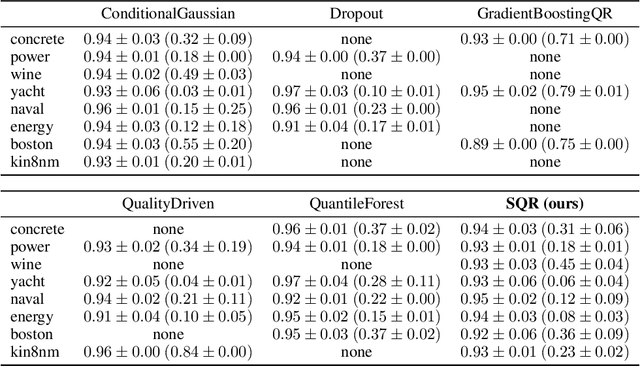
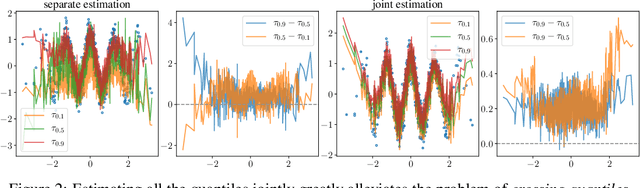
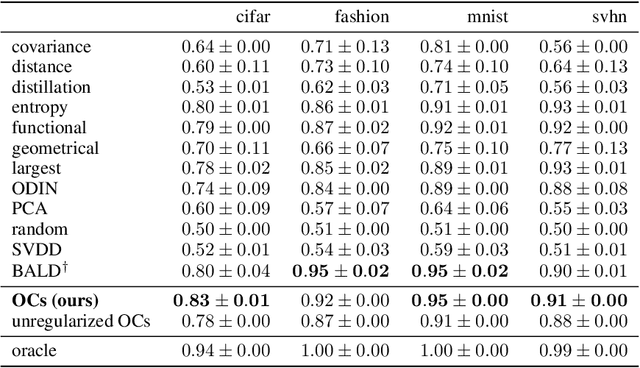
We provide frequentist estimates of aleatoric and epistemic uncertainty for deep neural networks. To estimate aleatoric uncertainty we propose simultaneous quantile regression, a loss function to learn all the conditional quantiles of a given target variable. These quantiles lead to well-calibrated prediction intervals. To estimate epistemic uncertainty we propose training certificates, a collection of diverse non-trivial functions that map all training samples to zero. These certificates map out-of-distribution examples to non-zero values, signaling high epistemic uncertainty. We compare our proposals to prior art in various experiments.
Nonparametric Quantile-Based Causal Discovery
Oct 07, 2018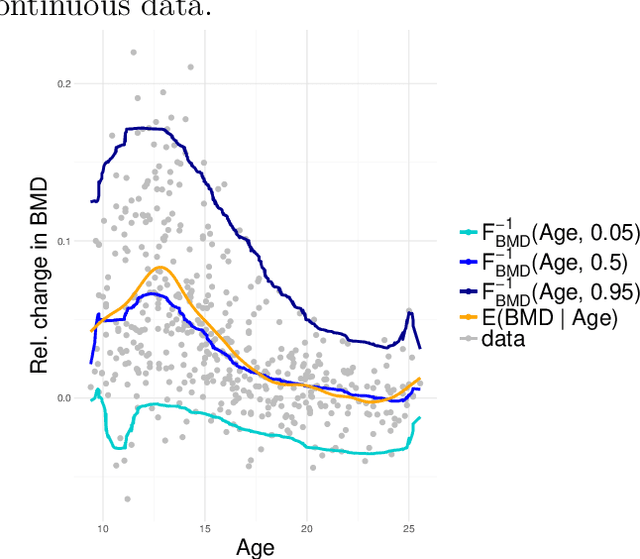
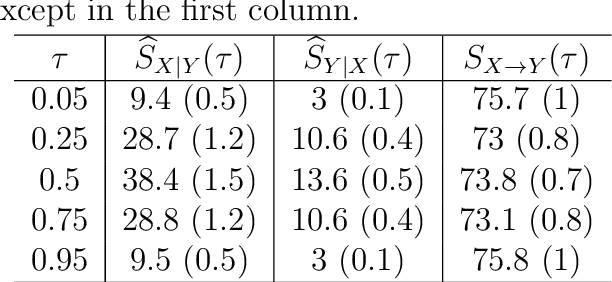
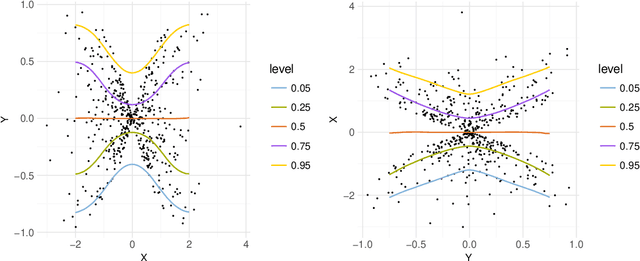
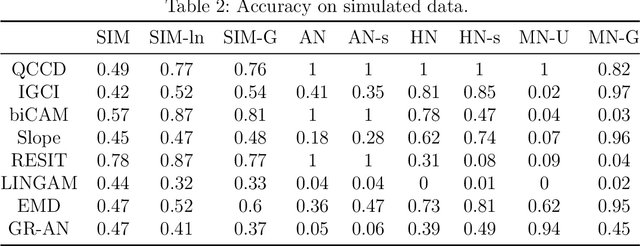
Distinguishing cause from effect using observational data is a challenging problem, especially in the bivariate case. Contemporary methods often assume an independence between the cause and the generating mechanism of the effect given the cause. From this postulate, they derive asymmetries to uncover causal relationships. Leveraging the same postulate, in this work, we propose a novel approach based on the link between Kolmogorov complexity and quantile scoring. We use a nonparametric conditional quantile estimator based on copulas to implement our procedure, thus avoiding restrictive assumptions about the joint distribution between cause and effect. In an extensive study on real and synthetic data, we show that quantile copula causal discovery (QCCD) compares favorably to state-of-the-art methods.