 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEBULA: Neural Empirical Bayes Under Latent Representations for Efficient and Controllable Design of Molecular Libraries
Jul 03, 2024We present NEBULA, the first latent 3D generative model for scalable generation of large molecular libraries around a seed compound of interest. Such libraries are crucial for scientific discovery, but it remains challenging to generate large numbers of high quality samples efficiently. 3D-voxel-based methods have recently shown great promise for generating high quality samples de novo from random noise (Pinheiro et al., 2023). However, sampling in 3D-voxel space is computationally expensive and use in library generation is prohibitively slow. Here, we instead perform neural empirical Bayes sampling (Saremi & Hyvarinen, 2019) in the learned latent space of a vector-quantized variational autoencoder. NEBULA generates large molecular libraries nearly an order of magnitude faster than existing methods without sacrificing sample quality. Moreover, NEBULA generalizes better to unseen drug-like molecules, as demonstrated on two public datasets and multiple recently released drugs. We expect the approach herein to be highly enabling for machine learning-based drug discovery. The code is available at https://github.com/prescient-design/nebula
MoleCLUEs: Optimizing Molecular Conformers by Minimization of Differentiable Uncertainty
Jun 20, 2023



Structure-based models in the molecular sciences can be highly sensitive to input geometries and give predictions with large variance under subtle coordinate perturbations. We present an approach to mitigate this failure mode by generating conformations that explicitly minimize uncertainty in a predictive model. To achieve this, we compute differentiable estimates of aleatoric \textit{and} epistemic uncertainties directly from learned embeddings. We then train an optimizer that iteratively samples embeddings to reduce these uncertainties according to their gradients. As our predictive model is constructed as a variational autoencoder, the new embeddings can be decoded to their corresponding inputs, which we call \textit{MoleCLUEs}, or (molecular) counterfactual latent uncertainty explanations \citep{antoran2020getting}. We provide results of our algorithm for the task of predicting drug properties with maximum confidence as well as analysis of the differentiable structure simulations.
3D molecule generation by denoising voxel grids
Jun 13, 2023We propose a new score-based approach to generate 3D molecules represented as atomic densities on regular grids. First, we train a denoising neural network that learns to map from a smooth distribution of noisy molecules to the distribution of real molecules. Then, we follow the neural empirical Bayes framework [Saremi and Hyvarinen, 2019] and generate molecules in two steps: (i) sample noisy density grids from a smooth distribution via underdamped Langevin Markov chain Monte Carlo, and (ii) recover the ``clean'' molecule by denoising the noisy grid with a single step. Our method, VoxMol, generates molecules in a fundamentally different way than the current state of the art (i.e., diffusion models applied to atom point clouds). It differs in terms of the data representation, the noise model, the network architecture and the generative modeling algorithm. VoxMol achieves comparable results to state of the art on unconditional 3D molecule generation while being simpler to train and faster to generate molecules.
BOtied: Multi-objective Bayesian optimization with tied multivariate ranks
Jun 01, 2023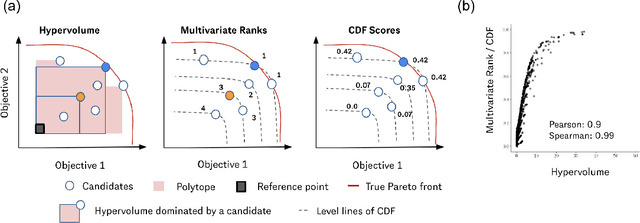
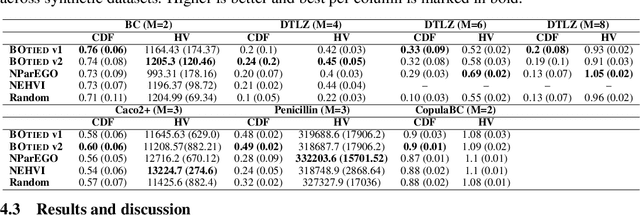
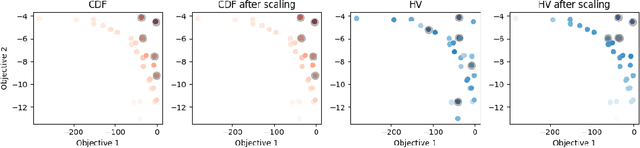
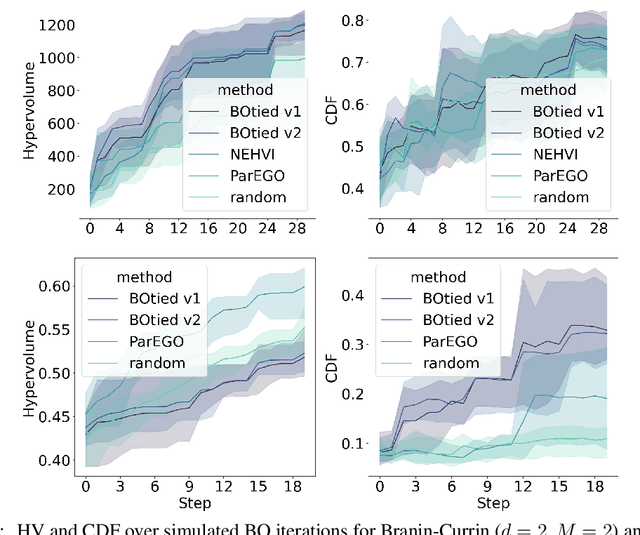
Many scientific and industrial applications require joint optimization of multiple, potentially competing objectives. Multi-objective Bayesian optimization (MOBO) is a sample-efficient framework for identifying Pareto-optimal solutions. We show a natural connection between non-dominated solutions and the highest multivariate rank, which coincides with the outermost level line of the joint cumulative distribution function (CDF). We propose the CDF indicator, a Pareto-compliant metric for evaluating the quality of approximate Pareto sets that complements the popular hypervolume indicator. At the heart of MOBO is the acquisition function, which determines the next candidate to evaluate by navigating the best compromises among the objectives. Multi-objective acquisition functions that rely on box decomposition of the objective space, such as the expected hypervolume improvement (EHVI) and entropy search, scale poorly to a large number of objectives. We propose an acquisition function, called BOtied, based on the CDF indicator. BOtied can be implemented efficiently with copulas, a statistical tool for modeling complex, high-dimensional distributions. We benchmark BOtied against common acquisition functions, including EHVI and random scalarization (ParEGO), in a series of synthetic and real-data experiments. BOtied performs on par with the baselines across datasets and metrics while being computationally efficient.
SupSiam: Non-contrastive Auxiliary Loss for Learning from Molecular Conformers
Feb 15, 2023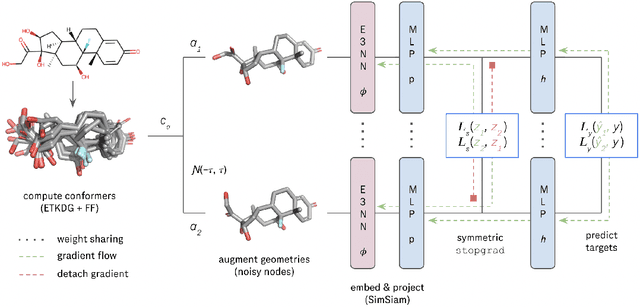

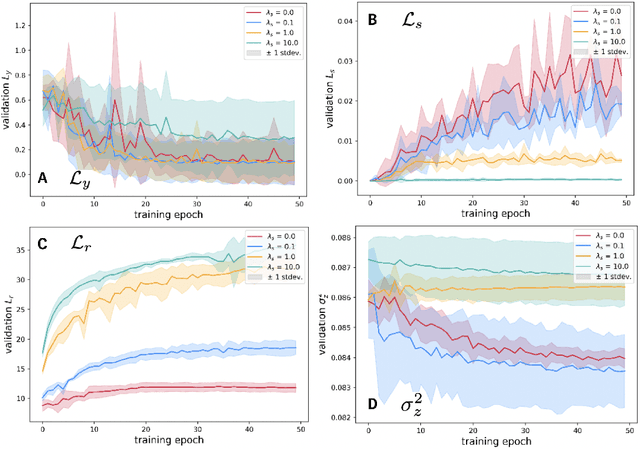

We investigate Siamese networks for learning related embeddings for augmented samples of molecular conformers. We find that a non-contrastive (positive-pair only) auxiliary task aids in supervised training of Euclidean neural networks (E3NNs) and increases manifold smoothness (MS) around point-cloud geometries. We demonstrate this property for multiple drug-activity prediction tasks while maintaining relevant performance metrics, and propose an extension of MS to probabilistic and regression settings. We provide an analysis of representation collapse, finding substantial effects of task-weighting, latent dimension, and regularization. We expect the presented protocol to aid in the development of reliable E3NNs from molecular conformers, even for small-data drug discovery programs.