 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore-based 3D molecule generation with neural fields
Jan 15, 2025We introduce a new representation for 3D molecules based on their continuous atomic density fields. Using this representation, we propose a new model based on walk-jump sampling for unconditional 3D molecule generation in the continuous space using neural fields. Our model, FuncMol, encodes molecular fields into latent codes using a conditional neural field, samples noisy codes from a Gaussian-smoothed distribution with Langevin MCMC (walk), denoises these samples in a single step (jump), and finally decodes them into molecular fields. FuncMol performs all-atom generation of 3D molecules without assumptions on the molecular structure and scales well with the size of molecules, unlike most approaches. Our method achieves competitive results on drug-like molecules and easily scales to macro-cyclic peptides, with at least one order of magnitude faster sampling. The code is available at https://github.com/prescient-design/funcmol.
NEBULA: Neural Empirical Bayes Under Latent Representations for Efficient and Controllable Design of Molecular Libraries
Jul 03, 2024We present NEBULA, the first latent 3D generative model for scalable generation of large molecular libraries around a seed compound of interest. Such libraries are crucial for scientific discovery, but it remains challenging to generate large numbers of high quality samples efficiently. 3D-voxel-based methods have recently shown great promise for generating high quality samples de novo from random noise (Pinheiro et al., 2023). However, sampling in 3D-voxel space is computationally expensive and use in library generation is prohibitively slow. Here, we instead perform neural empirical Bayes sampling (Saremi & Hyvarinen, 2019) in the learned latent space of a vector-quantized variational autoencoder. NEBULA generates large molecular libraries nearly an order of magnitude faster than existing methods without sacrificing sample quality. Moreover, NEBULA generalizes better to unseen drug-like molecules, as demonstrated on two public datasets and multiple recently released drugs. We expect the approach herein to be highly enabling for machine learning-based drug discovery. The code is available at https://github.com/prescient-design/nebula
Structure-based drug design by denoising voxel grids
May 07, 2024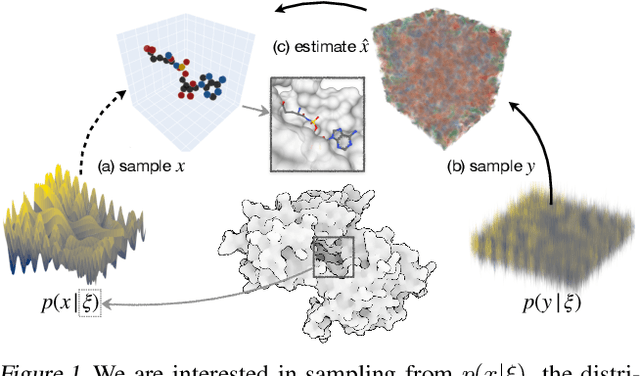
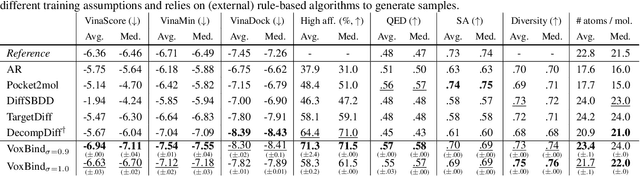
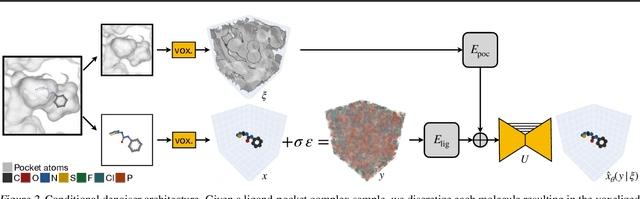
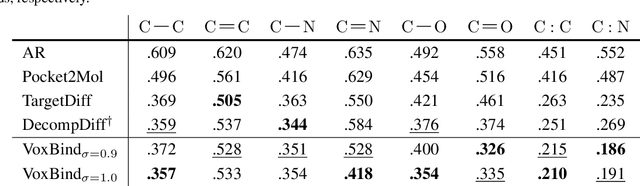
We present VoxBind, a new score-based generative model for 3D molecules conditioned on protein structures. Our approach represents molecules as 3D atomic density grids and leverages a 3D voxel-denoising network for learning and generation. We extend the neural empirical Bayes formalism (Saremi & Hyvarinen, 2019) to the conditional setting and generate structure-conditioned molecules with a two-step procedure: (i) sample noisy molecules from the Gaussian-smoothed conditional distribution with underdamped Langevin MCMC using the learned score function and (ii) estimate clean molecules from the noisy samples with single-step denoising. Compared to the current state of the art, our model is simpler to train, significantly faster to sample from, and achieves better results on extensive in silico benchmarks -- the generated molecules are more diverse, exhibit fewer steric clashes, and bind with higher affinity to protein pockets.
3D molecule generation by denoising voxel grids
Jun 13, 2023We propose a new score-based approach to generate 3D molecules represented as atomic densities on regular grids. First, we train a denoising neural network that learns to map from a smooth distribution of noisy molecules to the distribution of real molecules. Then, we follow the neural empirical Bayes framework [Saremi and Hyvarinen, 2019] and generate molecules in two steps: (i) sample noisy density grids from a smooth distribution via underdamped Langevin Markov chain Monte Carlo, and (ii) recover the ``clean'' molecule by denoising the noisy grid with a single step. Our method, VoxMol, generates molecules in a fundamentally different way than the current state of the art (i.e., diffusion models applied to atom point clouds). It differs in terms of the data representation, the noise model, the network architecture and the generative modeling algorithm. VoxMol achieves comparable results to state of the art on unconditional 3D molecule generation while being simpler to train and faster to generate molecules.
Touch-based Curiosity for Sparse-Reward Tasks
Apr 01, 2021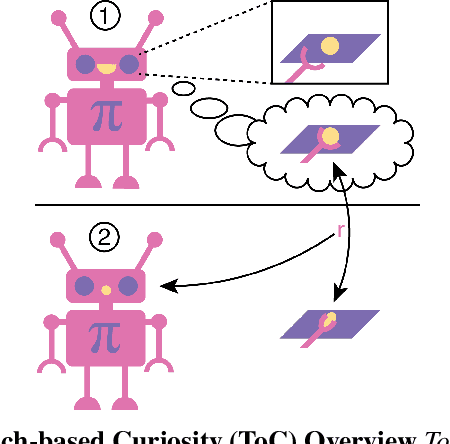
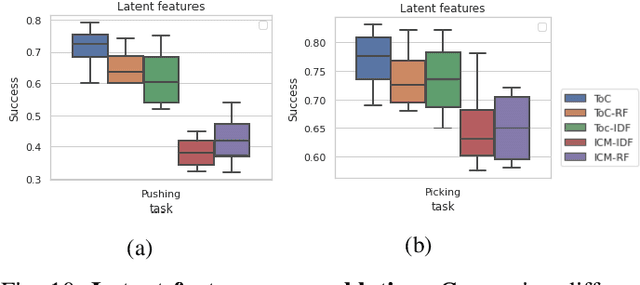
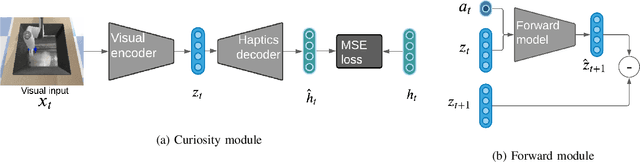
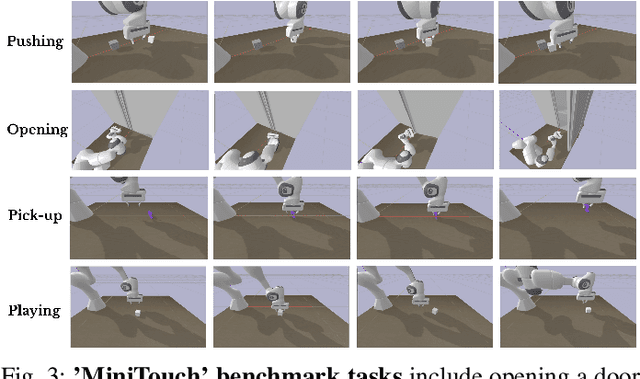
Robots in many real-world settings have access to force/torque sensors in their gripper and tactile sensing is often necessary in tasks that involve contact-rich motion. In this work, we leverage surprise from mismatches in touch feedback to guide exploration in hard sparse-reward reinforcement learning tasks. Our approach, Touch-based Curiosity (ToC), learns what visible objects interactions are supposed to "feel" like. We encourage exploration by rewarding interactions where the expectation and the experience don't match. In our proposed method, an initial task-independent exploration phase is followed by an on-task learning phase, in which the original interactions are relabeled with on-task rewards. We test our approach on a range of touch-intensive robot arm tasks (e.g. pushing objects, opening doors), which we also release as part of this work. Across multiple experiments in a simulated setting, we demonstrate that our method is able to learn these difficult tasks through sparse reward and curiosity alone. We compare our cross-modal approach to single-modality (touch- or vision-only) approaches as well as other curiosity-based methods and find that our method performs better and is more sample-efficient.
Unsupervised Learning of Dense Visual Representations
Nov 11, 2020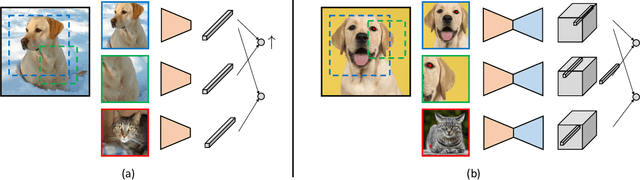


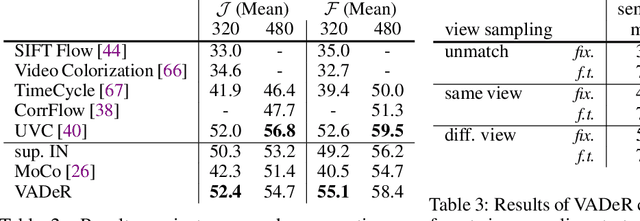
Contrastive self-supervised learning has emerged as a promising approach to unsupervised visual representation learning. In general, these methods learn global (image-level) representations that are invariant to different views (i.e., compositions of data augmentation) of the same image. However, many visual understanding tasks require dense (pixel-level) representations. In this paper, we propose View-Agnostic Dense Representation (VADeR) for unsupervised learning of dense representations. VADeR learns pixelwise representations by forcing local features to remain constant over different viewing conditions. Specifically, this is achieved through pixel-level contrastive learning: matching features (that is, features that describes the same location of the scene on different views) should be close in an embedding space, while non-matching features should be apart. VADeR provides a natural representation for dense prediction tasks and transfers well to downstream tasks. Our method outperforms ImageNet supervised pretraining (and strong unsupervised baselines) in multiple dense prediction tasks.
Reinforced active learning for image segmentation
Feb 16, 2020
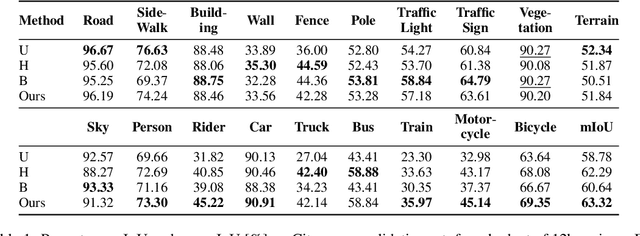


Learning-based approaches for semantic segmentation have two inherent challenges. First, acquiring pixel-wise labels is expensive and time-consuming. Second, realistic segmentation datasets are highly unbalanced: some categories are much more abundant than others, biasing the performance to the most represented ones. In this paper, we are interested in focusing human labelling effort on a small subset of a larger pool of data, minimizing this effort while maximizing performance of a segmentation model on a hold-out set. We present a new active learning strategy for semantic segmentation based on deep reinforcement learning (RL). An agent learns a policy to select a subset of small informative image regions -- opposed to entire images -- to be labeled, from a pool of unlabeled data. The region selection decision is made based on predictions and uncertainties of the segmentation model being trained. Our method proposes a new modification of the deep Q-network (DQN) formulation for active learning, adapting it to the large-scale nature of semantic segmentation problems. We test the proof of concept in CamVid and provide results in the large-scale dataset Cityscapes. On Cityscapes, our deep RL region-based DQN approach requires roughly 30% less additional labeled data than our most competitive baseline to reach the same performance. Moreover, we find that our method asks for more labels of under-represented categories compared to the baselines, improving their performance and helping to mitigate class imbalance.
Neural Multisensory Scene Inference
Nov 08, 2019
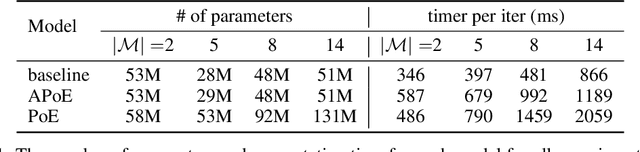
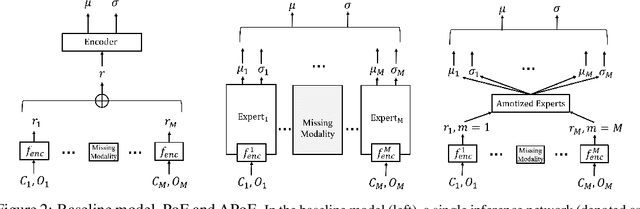
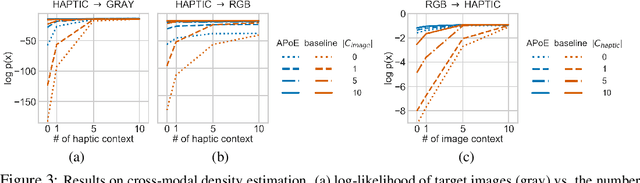
For embodied agents to infer representations of the underlying 3D physical world they inhabit, they should efficiently combine multisensory cues from numerous trials, e.g., by looking at and touching objects. Despite its importance, multisensory 3D scene representation learning has received less attention compared to the unimodal setting. In this paper, we propose the Generative Multisensory Network (GMN) for learning latent representations of 3D scenes which are partially observable through multiple sensory modalities. We also introduce a novel method, called the Amortized Product-of-Experts, to improve the computational efficiency and the robustness to unseen combinations of modalities at test time. Experimental results demonstrate that the proposed model can efficiently infer robust modality-invariant 3D-scene representations from arbitrary combinations of modalities and perform accurate cross-modal generation. To perform this exploration, we also develop the Multisensory Embodied 3D-Scene Environment (MESE).
Instance Segmentation with Point Supervision
Jun 14, 2019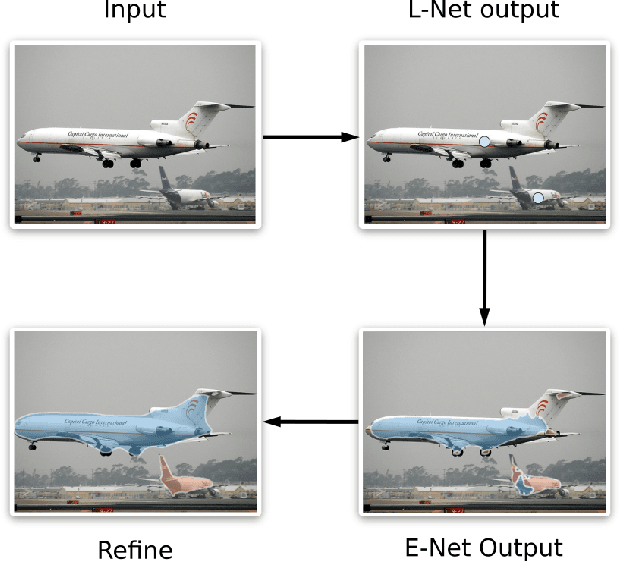



Instance segmentation methods often require costly per-pixel labels. We propose a method that only requires point-level annotations. During training, the model only has access to a single pixel label per object, yet the task is to output full segmentation masks. To address this challenge, we construct a network with two branches: (1) a localization network (L-Net) that predicts the location of each object; and (2) an embedding network (E-Net) that learns an embedding space where pixels of the same object are close. The segmentation masks for the located objects are obtained by grouping pixels with similar embeddings. At training time, while L-Net only requires point-level annotations, E-Net uses pseudo-labels generated by a class-agnostic object proposal method. We evaluate our approach on PASCAL VOC, COCO, KITTI and CityScapes datasets. The experiments show that our method (1) obtains competitive results compared to fully-supervised methods in certain scenarios; (2) outperforms fully- and weakly- supervised methods with a fixed annotation budget; and (3) is a first strong baseline for instance segmentation with point-level supervision.
Predicting Global Variations in Outdoor PM2.5 Concentrations using Satellite Images and Deep Convolutional Neural Networks
Jun 01, 2019

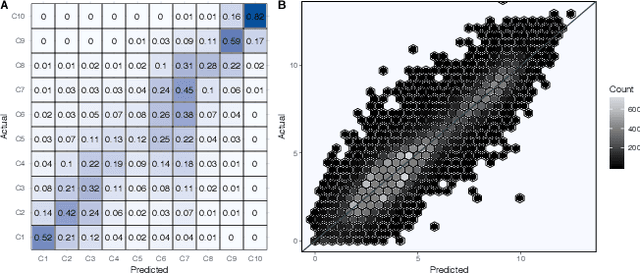
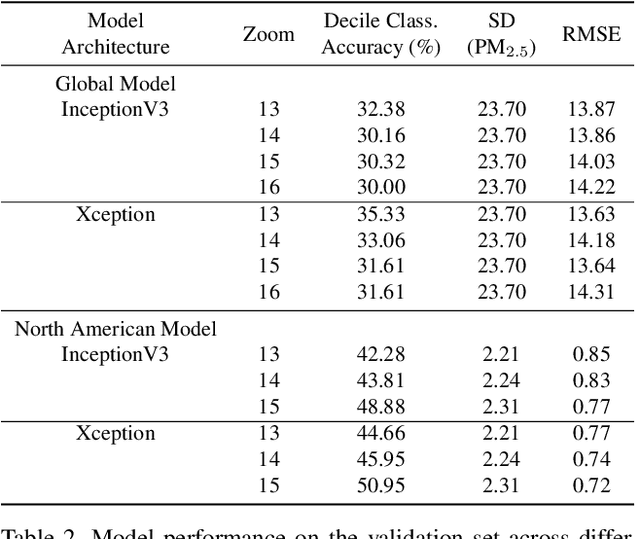
Here we present a new method of estimating global variations in outdoor PM$_{2.5}$ concentrations using satellite images combined with ground-level measurements and deep convolutional neural networks. Specifically, new deep learning models were trained over the global PM$_{2.5}$ concentration range ($<$1-436 $\mu$g/m$^3$) using a large database of satellite images paired with ground level PM$_{2.5}$ measurements available from the World Health Organization. Final model selection was based on a systematic evaluation of well-known architectures for the convolutional base including InceptionV3, Xception, and VGG16. The Xception architecture performed best and the final global model had a root mean square error (RMSE) value of 13.01 $\mu$g/m$^3$ (R$^2$=0.75) in the disjoint test set. The predictive performance of our new global model (called IMAGE-PM$_{2.5}$) is similar to the current state-of-the-art model used in the Global Burden of Disease study but relies only on satellite images as input. As a result, the IMAGE-PM$_{2.5}$ model offers a fast, cost-effective means of estimating global variations in long-term average PM$_{2.5}$ concentrations and may be particularly useful for regions without ground monitoring data or detailed emissions inventories. The IMAGE-PM$_{2.5}$ model can be used as a stand-alone method of global exposure estimation or incorporated into more complex hierarchical model structures.