 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore-based Diffusion Models in Function Space
Feb 14, 2023



Diffusion models have recently emerged as a powerful framework for generative modeling. They consist of a forward process that perturbs input data with Gaussian white noise and a reverse process that learns a score function to generate samples by denoising. Despite their tremendous success, they are mostly formulated on finite-dimensional spaces, e.g. Euclidean, limiting their applications to many domains where the data has a functional form such as in scientific computing and 3D geometric data analysis. In this work, we introduce a mathematically rigorous framework called Denoising Diffusion Operators (DDOs) for training diffusion models in function space. In DDOs, the forward process perturbs input functions gradually using a Gaussian process. The generative process is formulated by integrating a function-valued Langevin dynamic. Our approach requires an appropriate notion of the score for the perturbed data distribution, which we obtain by generalizing denoising score matching to function spaces that can be infinite-dimensional. We show that the corresponding discretized algorithm generates accurate samples at a fixed cost that is independent of the data resolution. We theoretically and numerically verify the applicability of our approach on a set of problems, including generating solutions to the Navier-Stokes equation viewed as the push-forward distribution of forcings from a Gaussian Random Field (GRF).
A Variational Perspective on Diffusion-Based Generative Models and Score Matching
Jun 05, 2021


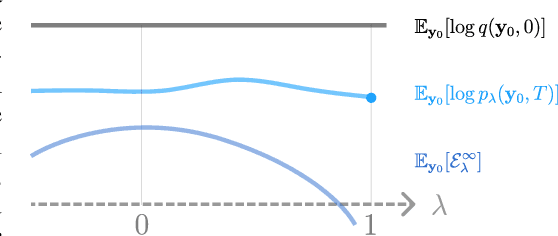
Discrete-time diffusion-based generative models and score matching methods have shown promising results in modeling high-dimensional image data. Recently, Song et al. (2021) show that diffusion processes that transform data into noise can be reversed via learning the score function, i.e. the gradient of the log-density of the perturbed data. They propose to plug the learned score function into an inverse formula to define a generative diffusion process. Despite the empirical success, a theoretical underpinning of this procedure is still lacking. In this work, we approach the (continuous-time) generative diffusion directly and derive a variational framework for likelihood estimation, which includes continuous-time normalizing flows as a special case, and can be seen as an infinitely deep variational autoencoder. Under this framework, we show that minimizing the score-matching loss is equivalent to maximizing a lower bound of the likelihood of the plug-in reverse SDE proposed by Song et al. (2021), bridging the theoretical gap.
AR-DAE: Towards Unbiased Neural Entropy Gradient Estimation
Jun 09, 2020
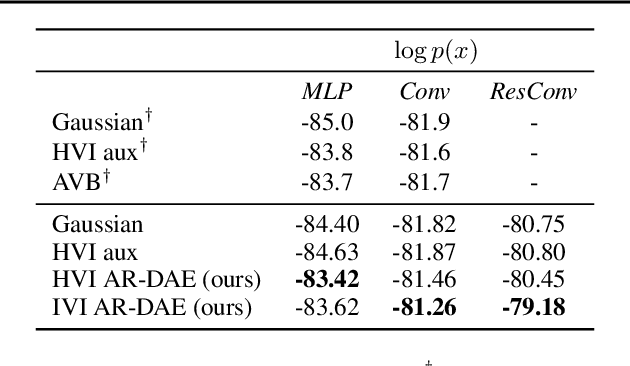
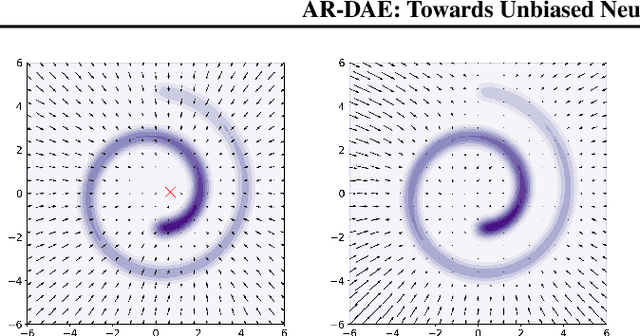

Entropy is ubiquitous in machine learning, but it is in general intractable to compute the entropy of the distribution of an arbitrary continuous random variable. In this paper, we propose the amortized residual denoising autoencoder (AR-DAE) to approximate the gradient of the log density function, which can be used to estimate the gradient of entropy. Amortization allows us to significantly reduce the error of the gradient approximator by approaching asymptotic optimality of a regular DAE, in which case the estimation is in theory unbiased. We conduct theoretical and experimental analyses on the approximation error of the proposed method, as well as extensive studies on heuristics to ensure its robustness. Finally, using the proposed gradient approximator to estimate the gradient of entropy, we demonstrate state-of-the-art performance on density estimation with variational autoencoders and continuous control with soft actor-critic.
Neural Multisensory Scene Inference
Nov 08, 2019
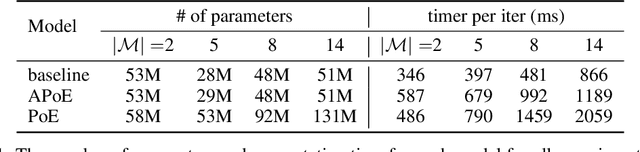
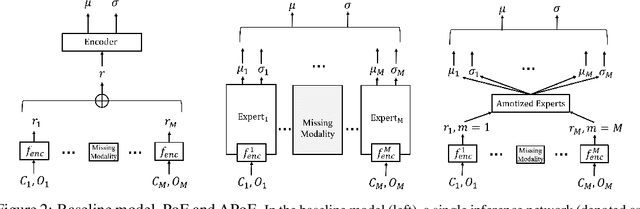
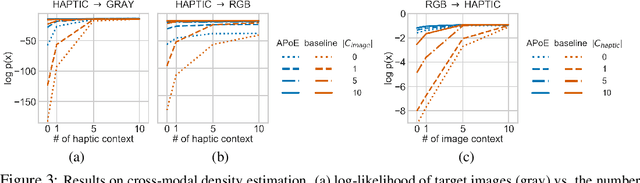
For embodied agents to infer representations of the underlying 3D physical world they inhabit, they should efficiently combine multisensory cues from numerous trials, e.g., by looking at and touching objects. Despite its importance, multisensory 3D scene representation learning has received less attention compared to the unimodal setting. In this paper, we propose the Generative Multisensory Network (GMN) for learning latent representations of 3D scenes which are partially observable through multiple sensory modalities. We also introduce a novel method, called the Amortized Product-of-Experts, to improve the computational efficiency and the robustness to unseen combinations of modalities at test time. Experimental results demonstrate that the proposed model can efficiently infer robust modality-invariant 3D-scene representations from arbitrary combinations of modalities and perform accurate cross-modal generation. To perform this exploration, we also develop the Multisensory Embodied 3D-Scene Environment (MESE).
Geometric GAN
May 09, 2017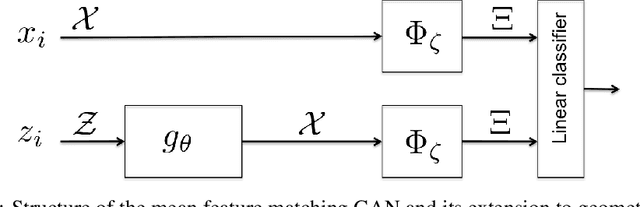

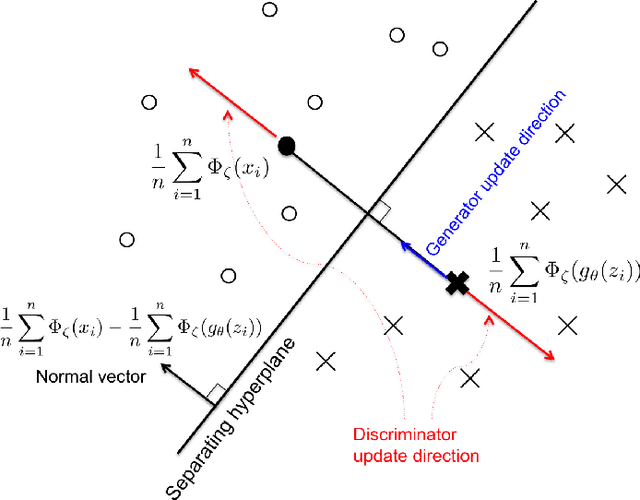

Generative Adversarial Nets (GANs) represent an important milestone for effective generative models, which has inspired numerous variants seemingly different from each other. One of the main contributions of this paper is to reveal a unified geometric structure in GAN and its variants. Specifically, we show that the adversarial generative model training can be decomposed into three geometric steps: separating hyperplane search, discriminator parameter update away from the separating hyperplane, and the generator update along the normal vector direction of the separating hyperplane. This geometric intuition reveals the limitations of the existing approaches and leads us to propose a new formulation called geometric GAN using SVM separating hyperplane that maximizes the margin. Our theoretical analysis shows that the geometric GAN converges to a Nash equilibrium between the discriminator and generator. In addition, extensive numerical results show that the superior performance of geometric GAN.