 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShared Latent Structures Enable Unified Backdoor Detection and Mitigation in LLMs
Jun 06, 2026Backdoor attacks in large language models (LLMs) are often treated as isolated trigger-response failures, motivating defenses tailored to specific triggers or behaviors. We show this view is incomplete. Across diverse backdoor behaviors, we identify a shared latent mechanism that can be detected, causally controlled, and suppressed. Using sparse autoencoders (SAEs) on residual-stream activations, we find a small set of latent features consistently activated across jailbreaking, refusal manipulation, password-locking, bias induction, sentiment misclassification, and country-conditioned harmful advice. These features generalize across Qwen3, Gemma~3, and Llama~3.1 models from 4B to 32B parameters, and across both fine-tuning and weight-editing attacks. Through bidirectional activation steering, we show these features are causal: suppressing them reduces attack success, while amplifying them induces target behaviors on clean prompts. We further train lightweight SAE-feature classifiers that generalize zero-shot to unseen backdoors and outperform residual-stream and weight-diffing baselines. Finally, we introduce Concept Ablation Fine-Tuning (CAFT), which suppresses backdoor formation by ablating the shared latent subspace during training. Together, our results suggest that many backdoors rely on a transferable latent mechanism, enabling unified detection and mitigation.
A Unified Framework to Quantify Cultural Intelligence of AI
Mar 01, 2026As generative AI technologies are increasingly being launched across the globe, assessing their competence to operate in different cultural contexts is exigently becoming a priority. While recent years have seen numerous and much-needed efforts on cultural benchmarking, these efforts have largely focused on specific aspects of culture and evaluation. While these efforts contribute to our understanding of cultural competence, a unified and systematic evaluation approach is needed for us as a field to comprehensively assess diverse cultural dimensions at scale. Drawing on measurement theory, we present a principled framework to aggregate multifaceted indicators of cultural capabilities into a unified assessment of cultural intelligence. We start by developing a working definition of culture that includes identifying core domains of culture. We then introduce a broad-purpose, systematic, and extensible framework for assessing cultural intelligence of AI systems. Drawing on theoretical framing from psychometric measurement validity theory, we decouple the background concept (i.e., cultural intelligence) from its operationalization via measurement. We conceptualize cultural intelligence as a suite of core capabilities spanning diverse domains, which we then operationalize through a set of indicators designed for reliable measurement. Finally, we identify the considerations, challenges, and research pathways to meaningfully measure these indicators, specifically focusing on data collection, probing strategies, and evaluation metrics.
Multilingual Amnesia: On the Transferability of Unlearning in Multilingual LLMs
Jan 09, 2026As multilingual large language models become more widely used, ensuring their safety and fairness across diverse linguistic contexts presents unique challenges. While existing research on machine unlearning has primarily focused on monolingual settings, typically English, multilingual environments introduce additional complexities due to cross-lingual knowledge transfer and biases embedded in both pretraining and fine-tuning data. In this work, we study multilingual unlearning using the Aya-Expanse 8B model under two settings: (1) data unlearning and (2) concept unlearning. We extend benchmarks for factual knowledge and stereotypes to ten languages through translation: English, French, Arabic, Japanese, Russian, Farsi, Korean, Hindi, Hebrew, and Indonesian. These languages span five language families and a wide range of resource levels. Our experiments show that unlearning in high-resource languages is generally more stable, with asymmetric transfer effects observed between typologically related languages. Furthermore, our analysis of linguistic distances indicates that syntactic similarity is the strongest predictor of cross-lingual unlearning behavior.
Cultural Evaluations of Vision-Language Models Have a Lot to Learn from Cultural Theory
May 28, 2025Modern vision-language models (VLMs) often fail at cultural competency evaluations and benchmarks. Given the diversity of applications built upon VLMs, there is renewed interest in understanding how they encode cultural nuances. While individual aspects of this problem have been studied, we still lack a comprehensive framework for systematically identifying and annotating the nuanced cultural dimensions present in images for VLMs. This position paper argues that foundational methodologies from visual culture studies (cultural studies, semiotics, and visual studies) are necessary for cultural analysis of images. Building upon this review, we propose a set of five frameworks, corresponding to cultural dimensions, that must be considered for a more complete analysis of the cultural competencies of VLMs.
Understanding the Local Geometry of Generative Model Manifolds
Aug 15, 2024



Deep generative models learn continuous representations of complex data manifolds using a finite number of samples during training. For a pre-trained generative model, the common way to evaluate the quality of the manifold representation learned, is by computing global metrics like Fr\'echet Inception Distance using a large number of generated and real samples. However, generative model performance is not uniform across the learned manifold, e.g., for \textit{foundation models} like Stable Diffusion generation performance can vary significantly based on the conditioning or initial noise vector being denoised. In this paper we study the relationship between the \textit{local geometry of the learned manifold} and downstream generation. Based on the theory of continuous piecewise-linear (CPWL) generators, we use three geometric descriptors - scaling ($\psi$), rank ($\nu$), and complexity ($\delta$) - to characterize a pre-trained generative model manifold locally. We provide quantitative and qualitative evidence showing that for a given latent, the local descriptors are correlated with generation aesthetics, artifacts, uncertainty, and even memorization. Finally we demonstrate that training a \textit{reward model} on the local geometry can allow controlling the likelihood of a generated sample under the learned distribution.
Position: Cracking the Code of Cascading Disparity Towards Marginalized Communities
Jun 03, 2024
The rise of foundation models holds immense promise for advancing AI, but this progress may amplify existing risks and inequalities, leaving marginalized communities behind. In this position paper, we discuss that disparities towards marginalized communities - performance, representation, privacy, robustness, interpretability and safety - are not isolated concerns but rather interconnected elements of a cascading disparity phenomenon. We contrast foundation models with traditional models and highlight the potential for exacerbated disparity against marginalized communities. Moreover, we emphasize the unique threat of cascading impacts in foundation models, where interconnected disparities can trigger long-lasting negative consequences, specifically to the people on the margin. We define marginalized communities within the machine learning context and explore the multifaceted nature of disparities. We analyze the sources of these disparities, tracing them from data creation, training and deployment procedures to highlight the complex technical and socio-technical landscape. To mitigate the pressing crisis, we conclude with a set of calls to action to mitigate disparity at its source.
A Toolbox for Surfacing Health Equity Harms and Biases in Large Language Models
Mar 18, 2024Large language models (LLMs) hold immense promise to serve complex health information needs but also have the potential to introduce harm and exacerbate health disparities. Reliably evaluating equity-related model failures is a critical step toward developing systems that promote health equity. In this work, we present resources and methodologies for surfacing biases with potential to precipitate equity-related harms in long-form, LLM-generated answers to medical questions and then conduct an empirical case study with Med-PaLM 2, resulting in the largest human evaluation study in this area to date. Our contributions include a multifactorial framework for human assessment of LLM-generated answers for biases, and EquityMedQA, a collection of seven newly-released datasets comprising both manually-curated and LLM-generated questions enriched for adversarial queries. Both our human assessment framework and dataset design process are grounded in an iterative participatory approach and review of possible biases in Med-PaLM 2 answers to adversarial queries. Through our empirical study, we find that the use of a collection of datasets curated through a variety of methodologies, coupled with a thorough evaluation protocol that leverages multiple assessment rubric designs and diverse rater groups, surfaces biases that may be missed via narrower evaluation approaches. Our experience underscores the importance of using diverse assessment methodologies and involving raters of varying backgrounds and expertise. We emphasize that while our framework can identify specific forms of bias, it is not sufficient to holistically assess whether the deployment of an AI system promotes equitable health outcomes. We hope the broader community leverages and builds on these tools and methods towards realizing a shared goal of LLMs that promote accessible and equitable healthcare for all.
The Case for Globalizing Fairness: A Mixed Methods Study on Colonialism, AI, and Health in Africa
Mar 11, 2024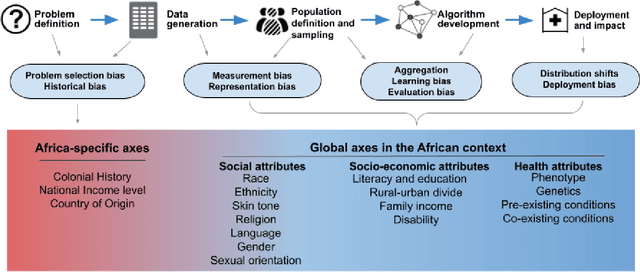
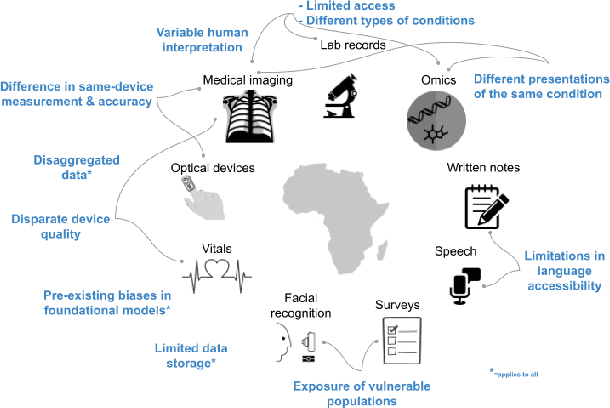
With growing application of machine learning (ML) technologies in healthcare, there have been calls for developing techniques to understand and mitigate biases these systems may exhibit. Fair-ness considerations in the development of ML-based solutions for health have particular implications for Africa, which already faces inequitable power imbalances between the Global North and South.This paper seeks to explore fairness for global health, with Africa as a case study. We conduct a scoping review to propose axes of disparities for fairness consideration in the African context and delineate where they may come into play in different ML-enabled medical modalities. We then conduct qualitative research studies with 672 general population study participants and 28 experts inML, health, and policy focused on Africa to obtain corroborative evidence on the proposed axes of disparities. Our analysis focuses on colonialism as the attribute of interest and examines the interplay between artificial intelligence (AI), health, and colonialism. Among the pre-identified attributes, we found that colonial history, country of origin, and national income level were specific axes of disparities that participants believed would cause an AI system to be biased.However, there was also divergence of opinion between experts and general population participants. Whereas experts generally expressed a shared view about the relevance of colonial history for the development and implementation of AI technologies in Africa, the majority of the general population participants surveyed did not think there was a direct link between AI and colonialism. Based on these findings, we provide practical recommendations for developing fairness-aware ML solutions for health in Africa.
From plane crashes to algorithmic harm: applicability of safety engineering frameworks for responsible ML
Oct 06, 2022
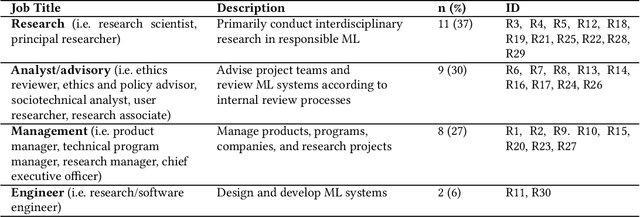
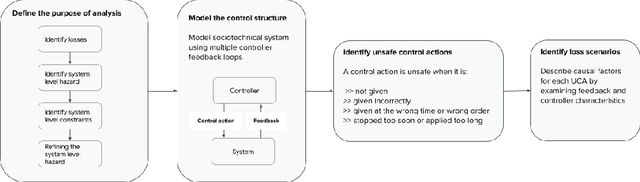
Inappropriate design and deployment of machine learning (ML) systems leads to negative downstream social and ethical impact -- described here as social and ethical risks -- for users, society and the environment. Despite the growing need to regulate ML systems, current processes for assessing and mitigating risks are disjointed and inconsistent. We interviewed 30 industry practitioners on their current social and ethical risk management practices, and collected their first reactions on adapting safety engineering frameworks into their practice -- namely, System Theoretic Process Analysis (STPA) and Failure Mode and Effects Analysis (FMEA). Our findings suggest STPA/FMEA can provide appropriate structure toward social and ethical risk assessment and mitigation processes. However, we also find nontrivial challenges in integrating such frameworks in the fast-paced culture of the ML industry. We call on the ML research community to strengthen existing frameworks and assess their efficacy, ensuring that ML systems are safer for all people.
Inducing bias is simpler than you think
May 31, 2022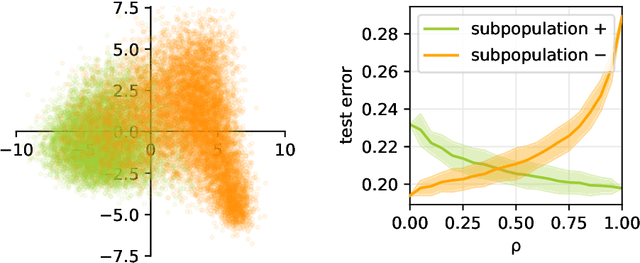
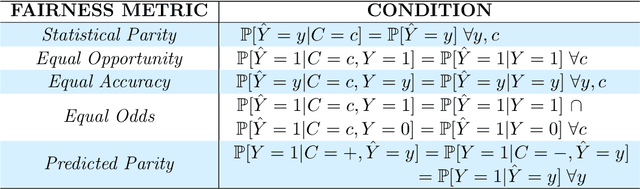
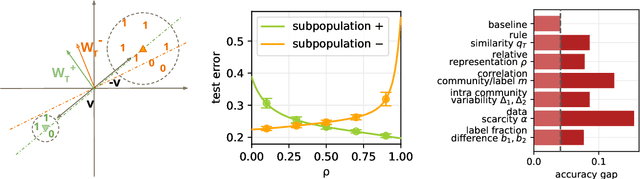
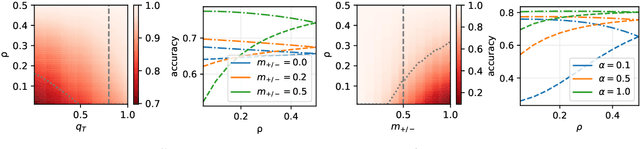
Machine learning may be oblivious to human bias but it is not immune to its perpetuation. Marginalisation and iniquitous group representation are often traceable in the very data used for training, and may be reflected or even enhanced by the learning models. To counter this, some of the model accuracy can be traded off for a secondary objective that helps prevent a specific type of bias. Multiple notions of fairness have been proposed to this end but recent studies show that some fairness criteria often stand in mutual competition. In the present work, we introduce a solvable high-dimensional model of data imbalance, where parametric control over the many bias-inducing factors allows for an extensive exploration of the bias inheritance mechanism. Through the tools of statistical physics, we analytically characterise the typical behaviour of learning models trained in our synthetic framework and find similar unfairness behaviours as those observed on more realistic data. However, we also identify a positive transfer effect between the different subpopulations within the data. This suggests that mixing data with different statistical properties could be helpful, provided the learning model is made aware of this structure. Finally, we analyse the issue of bias mitigation: by reweighing the various terms in the training loss, we indirectly minimise standard unfairness metrics and highlight their incompatibilities. Leveraging the insights on positive transfer, we also propose a theory-informed mitigation strategy, based on the introduction of coupled learning models. By allowing each model to specialise on a different community within the data, we find that multiple fairness criteria and high accuracy can be achieved simultaneously.