 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInducing bias is simpler than you think
Paper and Code
May 31, 2022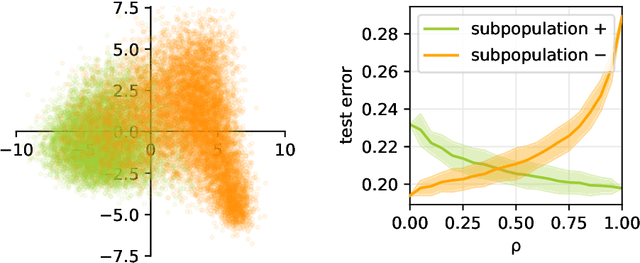
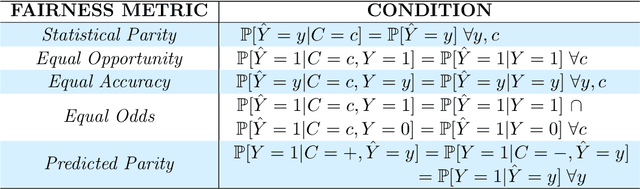
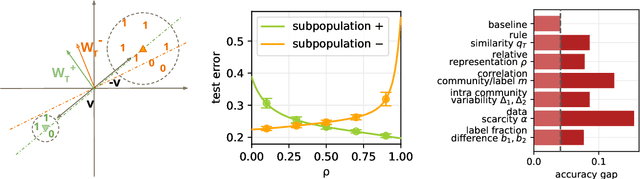
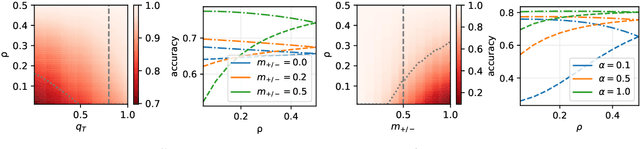
Machine learning may be oblivious to human bias but it is not immune to its perpetuation. Marginalisation and iniquitous group representation are often traceable in the very data used for training, and may be reflected or even enhanced by the learning models. To counter this, some of the model accuracy can be traded off for a secondary objective that helps prevent a specific type of bias. Multiple notions of fairness have been proposed to this end but recent studies show that some fairness criteria often stand in mutual competition. In the present work, we introduce a solvable high-dimensional model of data imbalance, where parametric control over the many bias-inducing factors allows for an extensive exploration of the bias inheritance mechanism. Through the tools of statistical physics, we analytically characterise the typical behaviour of learning models trained in our synthetic framework and find similar unfairness behaviours as those observed on more realistic data. However, we also identify a positive transfer effect between the different subpopulations within the data. This suggests that mixing data with different statistical properties could be helpful, provided the learning model is made aware of this structure. Finally, we analyse the issue of bias mitigation: by reweighing the various terms in the training loss, we indirectly minimise standard unfairness metrics and highlight their incompatibilities. Leveraging the insights on positive transfer, we also propose a theory-informed mitigation strategy, based on the introduction of coupled learning models. By allowing each model to specialise on a different community within the data, we find that multiple fairness criteria and high accuracy can be achieved simultaneously.