 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEscape dynamics and implicit bias of one-pass SGD in overparameterized quadratic networks
Apr 03, 2026We analyze the one-pass stochastic gradient descent dynamics of a two-layer neural network with quadratic activations in a teacher--student framework. In the high-dimensional regime, where the input dimension $N$ and the number of samples $M$ diverge at fixed ratio $α= M/N$, and for finite hidden widths $(p,p^*)$ of the student and teacher, respectively, we study the low-dimensional ordinary differential equations that govern the evolution of the student--teacher and student--student overlap matrices. We show that overparameterization ($p>p^*$) only modestly accelerates escape from a plateau of poor generalization by modifying the prefactor of the exponential decay of the loss. We then examine how unconstrained weight norms introduce a continuous rotational symmetry that results in a nontrivial manifold of zero-loss solutions for $p>1$. From this manifold the dynamics consistently selects the closest solution to the random initialization, as enforced by a conserved quantity in the ODEs governing the evolution of the overlaps. Finally, a Hessian analysis of the population-loss landscape confirms that the plateau and the solution manifold correspond to saddles with at least one negative eigenvalue and to marginal minima in the population-loss geometry, respectively.
Biased Generalization in Diffusion Models
Mar 03, 2026Generalization in generative modeling is defined as the ability to learn an underlying distribution from a finite dataset and produce novel samples, with evaluation largely driven by held-out performance and perceived sample quality. In practice, training is often stopped at the minimum of the test loss, taken as an operational indicator of generalization. We challenge this viewpoint by identifying a phase of biased generalization during training, in which the model continues to decrease the test loss while favoring samples with anomalously high proximity to training data. By training the same network on two disjoint datasets and comparing the mutual distances of generated samples and their similarity to training data, we introduce a quantitative measure of bias and demonstrate its presence on real images. We then study the mechanism of bias, using a controlled hierarchical data model where access to exact scores and ground-truth statistics allows us to precisely characterize its onset. We attribute this phenomenon to the sequential nature of feature learning in deep networks, where coarse structure is learned early in a data-independent manner, while finer features are resolved later in a way that increasingly depends on individual training samples. Our results show that early stopping at the test loss minimum, while optimal under standard generalization criteria, may be insufficient for privacy-critical applications.
How transformers learn structured data: insights from hierarchical filtering
Aug 27, 2024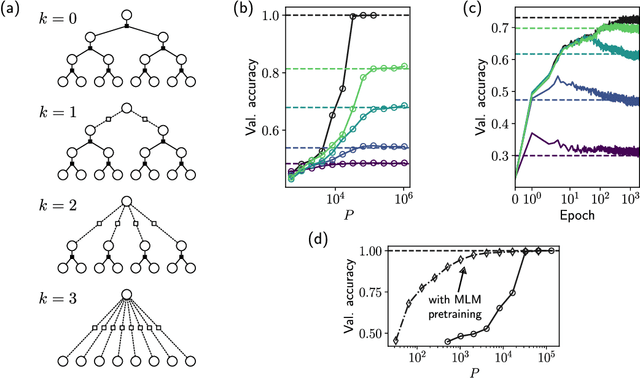

We introduce a hierarchical filtering procedure for generative models of sequences on trees, enabling control over the range of positional correlations in the data. Leveraging this controlled setting, we provide evidence that vanilla encoder-only transformer architectures can implement the optimal Belief Propagation algorithm on both root classification and masked language modeling tasks. Correlations at larger distances corresponding to increasing layers of the hierarchy are sequentially included as the network is trained. We analyze how the transformer layers succeed by focusing on attention maps from models trained with varying degrees of filtering. These attention maps show clear evidence for iterative hierarchical reconstruction of correlations, and we can relate these observations to a plausible implementation of the exact inference algorithm for the network sizes considered.
Tilting the Odds at the Lottery: the Interplay of Overparameterisation and Curricula in Neural Networks
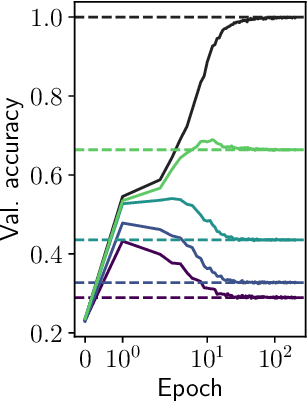
Jun 03, 2024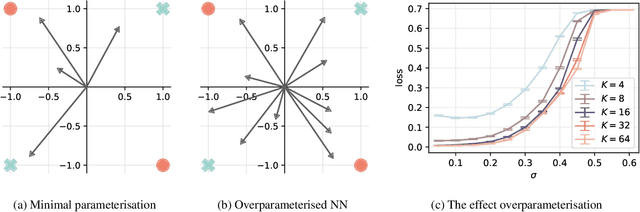
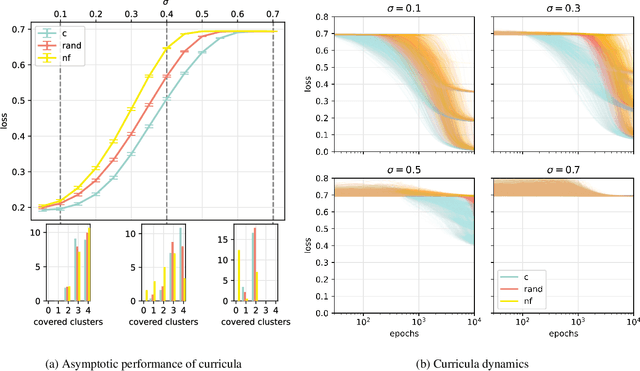
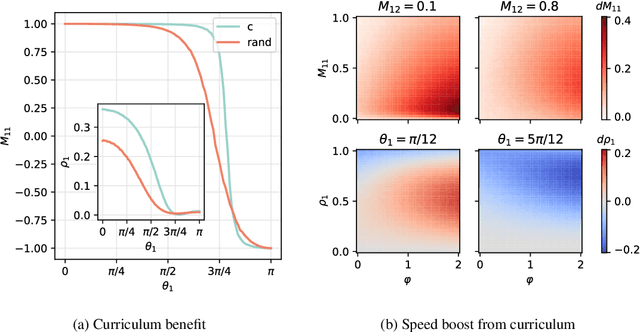
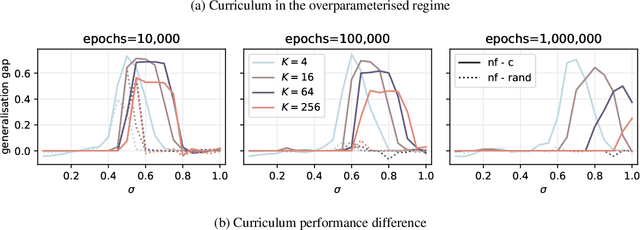
A wide range of empirical and theoretical works have shown that overparameterisation can amplify the performance of neural networks. According to the lottery ticket hypothesis, overparameterised networks have an increased chance of containing a sub-network that is well-initialised to solve the task at hand. A more parsimonious approach, inspired by animal learning, consists in guiding the learner towards solving the task by curating the order of the examples, i.e. providing a curriculum. However, this learning strategy seems to be hardly beneficial in deep learning applications. In this work, we undertake an analytical study that connects curriculum learning and overparameterisation. In particular, we investigate their interplay in the online learning setting for a 2-layer network in the XOR-like Gaussian Mixture problem. Our results show that a high degree of overparameterisation -- while simplifying the problem -- can limit the benefit from curricula, providing a theoretical account of the ineffectiveness of curricula in deep learning.
The twin peaks of learning neural networks
Jan 23, 2024Recent works demonstrated the existence of a double-descent phenomenon for the generalization error of neural networks, where highly overparameterized models escape overfitting and achieve good test performance, at odds with the standard bias-variance trade-off described by statistical learning theory. In the present work, we explore a link between this phenomenon and the increase of complexity and sensitivity of the function represented by neural networks. In particular, we study the Boolean mean dimension (BMD), a metric developed in the context of Boolean function analysis. Focusing on a simple teacher-student setting for the random feature model, we derive a theoretical analysis based on the replica method that yields an interpretable expression for the BMD, in the high dimensional regime where the number of data points, the number of features, and the input size grow to infinity. We find that, as the degree of overparameterization of the network is increased, the BMD reaches an evident peak at the interpolation threshold, in correspondence with the generalization error peak, and then slowly approaches a low asymptotic value. The same phenomenology is then traced in numerical experiments with different model classes and training setups. Moreover, we find empirically that adversarially initialized models tend to show higher BMD values, and that models that are more robust to adversarial attacks exhibit a lower BMD.
The star-shaped space of solutions of the spherical negative perceptron
May 18, 2023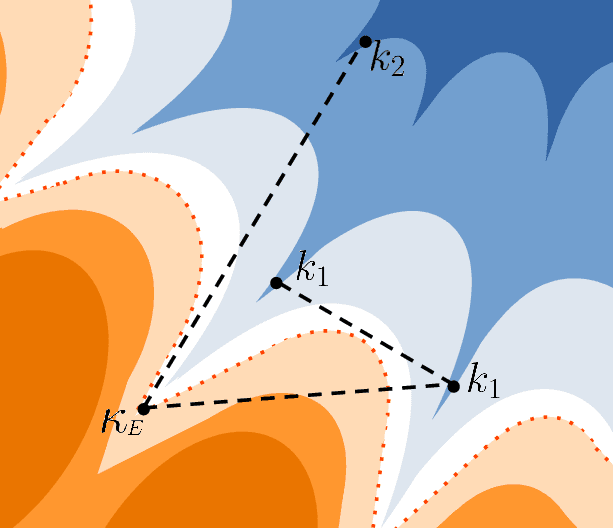
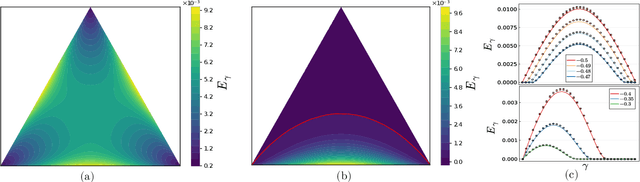
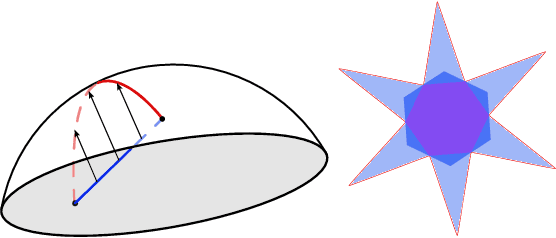
Empirical studies on the landscape of neural networks have shown that low-energy configurations are often found in complex connected structures, where zero-energy paths between pairs of distant solutions can be constructed. Here we consider the spherical negative perceptron, a prototypical non-convex neural network model framed as a continuous constraint satisfaction problem. We introduce a general analytical method for computing energy barriers in the simplex with vertex configurations sampled from the equilibrium. We find that in the over-parameterized regime the solution manifold displays simple connectivity properties. There exists a large geodesically convex component that is attractive for a wide range of optimization dynamics. Inside this region we identify a subset of atypically robust solutions that are geodesically connected with most other solutions, giving rise to a star-shaped geometry. We analytically characterize the organization of the connected space of solutions and show numerical evidence of a transition, at larger constraint densities, where the aforementioned simple geodesic connectivity breaks down.
Optimal transfer protocol by incremental layer defrosting
Mar 02, 2023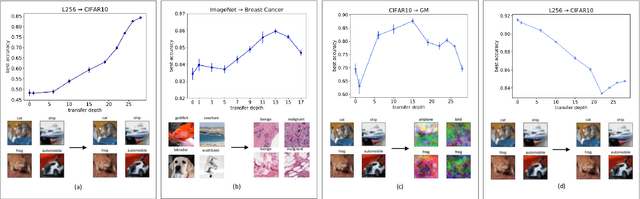
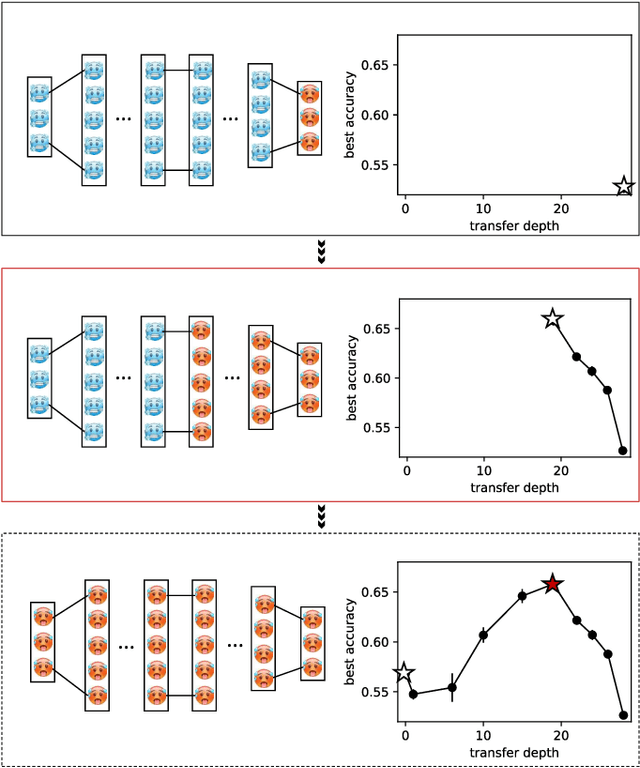
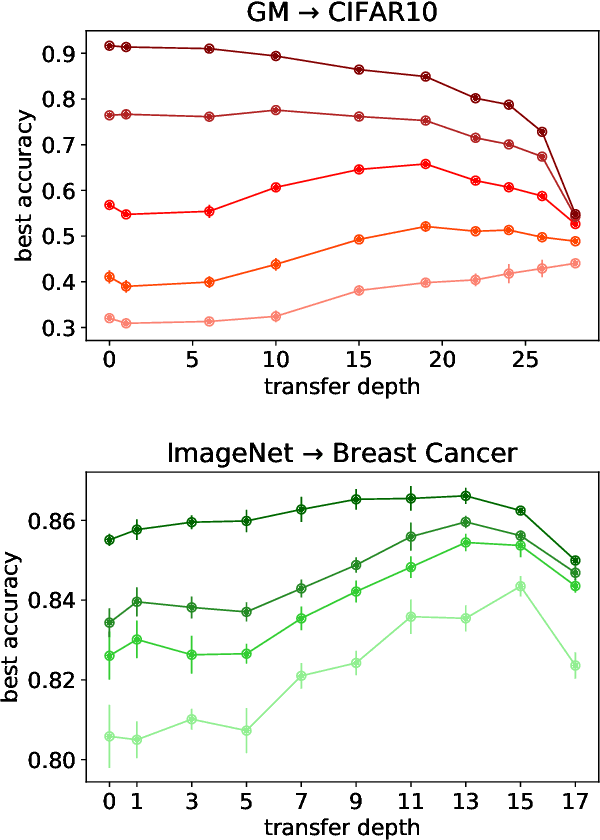
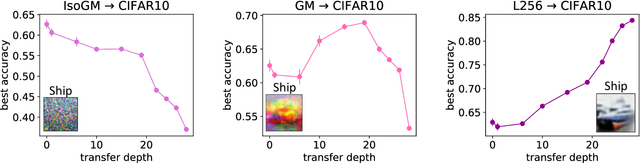
Transfer learning is a powerful tool enabling model training with limited amounts of data. This technique is particularly useful in real-world problems where data availability is often a serious limitation. The simplest transfer learning protocol is based on ``freezing" the feature-extractor layers of a network pre-trained on a data-rich source task, and then adapting only the last layers to a data-poor target task. This workflow is based on the assumption that the feature maps of the pre-trained model are qualitatively similar to the ones that would have been learned with enough data on the target task. In this work, we show that this protocol is often sub-optimal, and the largest performance gain may be achieved when smaller portions of the pre-trained network are kept frozen. In particular, we make use of a controlled framework to identify the optimal transfer depth, which turns out to depend non-trivially on the amount of available training data and on the degree of source-target task correlation. We then characterize transfer optimality by analyzing the internal representations of two networks trained from scratch on the source and the target task through multiple established similarity measures.
Inducing bias is simpler than you think
May 31, 2022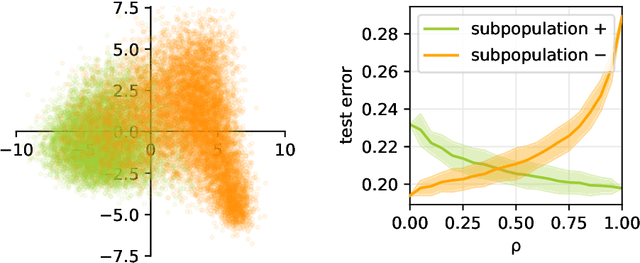
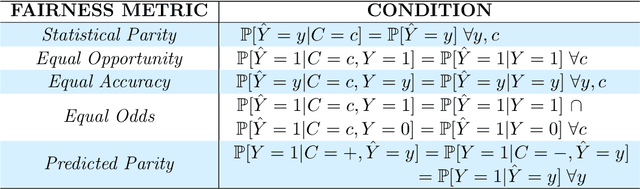
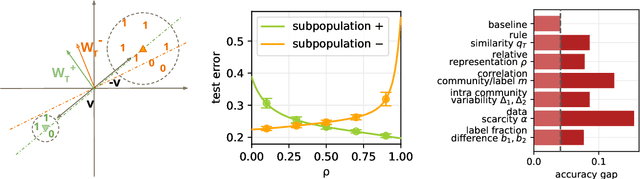
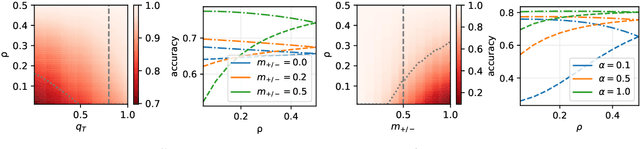
Machine learning may be oblivious to human bias but it is not immune to its perpetuation. Marginalisation and iniquitous group representation are often traceable in the very data used for training, and may be reflected or even enhanced by the learning models. To counter this, some of the model accuracy can be traded off for a secondary objective that helps prevent a specific type of bias. Multiple notions of fairness have been proposed to this end but recent studies show that some fairness criteria often stand in mutual competition. In the present work, we introduce a solvable high-dimensional model of data imbalance, where parametric control over the many bias-inducing factors allows for an extensive exploration of the bias inheritance mechanism. Through the tools of statistical physics, we analytically characterise the typical behaviour of learning models trained in our synthetic framework and find similar unfairness behaviours as those observed on more realistic data. However, we also identify a positive transfer effect between the different subpopulations within the data. This suggests that mixing data with different statistical properties could be helpful, provided the learning model is made aware of this structure. Finally, we analyse the issue of bias mitigation: by reweighing the various terms in the training loss, we indirectly minimise standard unfairness metrics and highlight their incompatibilities. Leveraging the insights on positive transfer, we also propose a theory-informed mitigation strategy, based on the introduction of coupled learning models. By allowing each model to specialise on a different community within the data, we find that multiple fairness criteria and high accuracy can be achieved simultaneously.
An Analytical Theory of Curriculum Learning in Teacher-Student Networks
Jun 15, 2021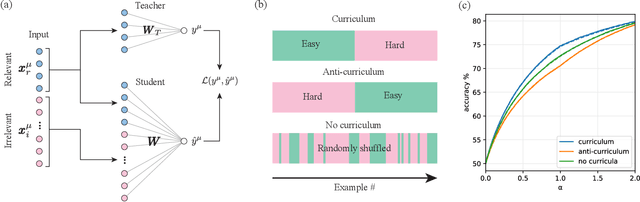
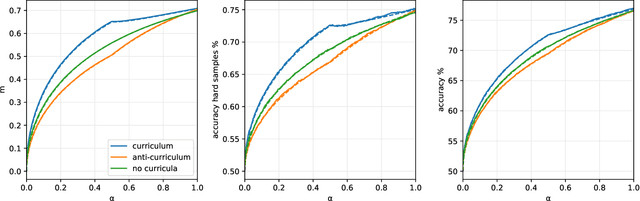
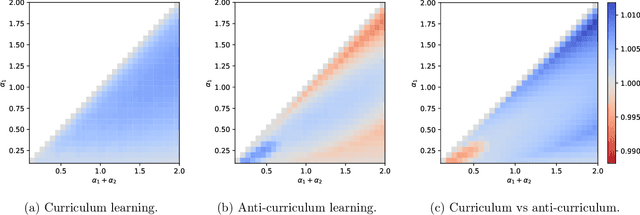
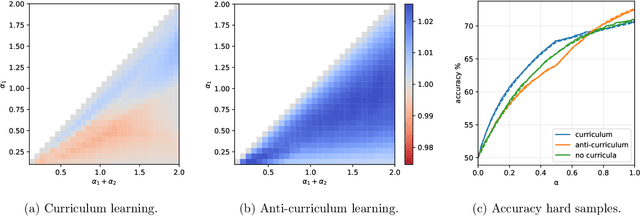
In humans and animals, curriculum learning -- presenting data in a curated order - is critical to rapid learning and effective pedagogy. Yet in machine learning, curricula are not widely used and empirically often yield only moderate benefits. This stark difference in the importance of curriculum raises a fundamental theoretical question: when and why does curriculum learning help? In this work, we analyse a prototypical neural network model of curriculum learning in the high-dimensional limit, employing statistical physics methods. Curricula could in principle change both the learning speed and asymptotic performance of a model. To study the former, we provide an exact description of the online learning setting, confirming the long-standing experimental observation that curricula can modestly speed up learning. To study the latter, we derive performance in a batch learning setting, in which a network trains to convergence in successive phases of learning on dataset slices of varying difficulty. With standard training losses, curriculum does not provide generalisation benefit, in line with empirical observations. However, we show that by connecting different learning phases through simple Gaussian priors, curriculum can yield a large improvement in test performance. Taken together, our reduced analytical descriptions help reconcile apparently conflicting empirical results and trace regimes where curriculum learning yields the largest gains. More broadly, our results suggest that fully exploiting a curriculum may require explicit changes to the loss function at curriculum boundaries.
Probing transfer learning with a model of synthetic correlated datasets
Jun 09, 2021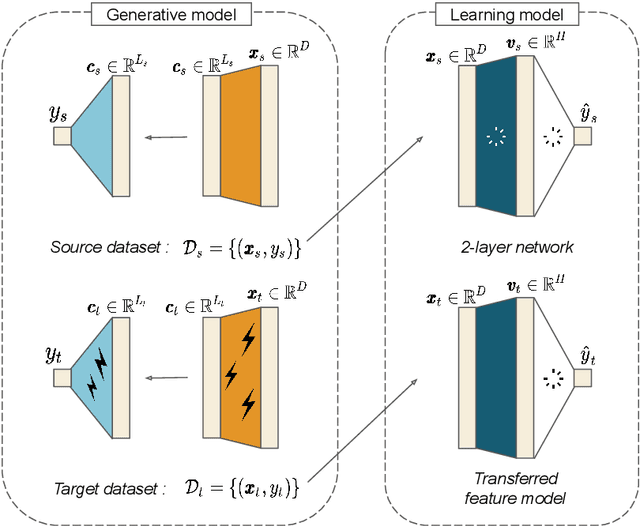
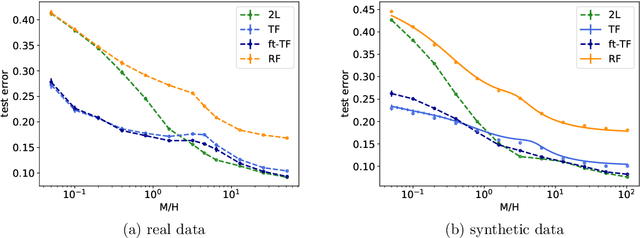
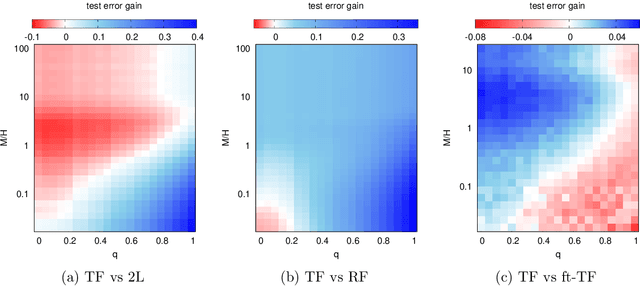
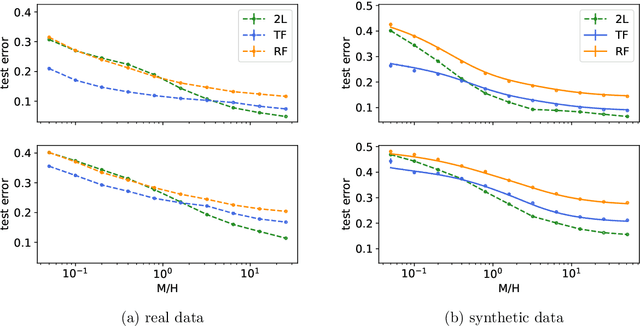
Transfer learning can significantly improve the sample efficiency of neural networks, by exploiting the relatedness between a data-scarce target task and a data-abundant source task. Despite years of successful applications, transfer learning practice often relies on ad-hoc solutions, while theoretical understanding of these procedures is still limited. In the present work, we re-think a solvable model of synthetic data as a framework for modeling correlation between data-sets. This setup allows for an analytic characterization of the generalization performance obtained when transferring the learned feature map from the source to the target task. Focusing on the problem of training two-layer networks in a binary classification setting, we show that our model can capture a range of salient features of transfer learning with real data. Moreover, by exploiting parametric control over the correlation between the two data-sets, we systematically investigate under which conditions the transfer of features is beneficial for generalization.