 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiased Generalization in Diffusion Models
Mar 03, 2026Generalization in generative modeling is defined as the ability to learn an underlying distribution from a finite dataset and produce novel samples, with evaluation largely driven by held-out performance and perceived sample quality. In practice, training is often stopped at the minimum of the test loss, taken as an operational indicator of generalization. We challenge this viewpoint by identifying a phase of biased generalization during training, in which the model continues to decrease the test loss while favoring samples with anomalously high proximity to training data. By training the same network on two disjoint datasets and comparing the mutual distances of generated samples and their similarity to training data, we introduce a quantitative measure of bias and demonstrate its presence on real images. We then study the mechanism of bias, using a controlled hierarchical data model where access to exact scores and ground-truth statistics allows us to precisely characterize its onset. We attribute this phenomenon to the sequential nature of feature learning in deep networks, where coarse structure is learned early in a data-independent manner, while finer features are resolved later in a way that increasingly depends on individual training samples. Our results show that early stopping at the test loss minimum, while optimal under standard generalization criteria, may be insufficient for privacy-critical applications.
Theory of Speciation Transitions in Diffusion Models with General Class Structure
Feb 04, 2026Diffusion Models generate data by reversing a stochastic diffusion process, progressively transforming noise into structured samples drawn from a target distribution. Recent theoretical work has shown that this backward dynamics can undergo sharp qualitative transitions, known as speciation transitions, during which trajectories become dynamically committed to data classes. Existing theoretical analyses, however, are limited to settings where classes are identifiable through first moments, such as mixtures of Gaussians with well-separated means. In this work, we develop a general theory of speciation in diffusion models that applies to arbitrary target distributions admitting well-defined classes. We formalize the notion of class structure through Bayes classification and characterize speciation times in terms of free-entropy difference between classes. This criterion recovers known results in previously studied Gaussian-mixture models, while extending to situations in which classes are not distinguishable by first moments and may instead differ through higher-order or collective features. Our framework also accommodates multiple classes and predicts the existence of successive speciation times associated with increasingly fine-grained class commitment. We illustrate the theory on two analytically tractable examples: mixtures of one-dimensional Ising models at different temperatures and mixtures of zero-mean Gaussians with distinct covariance structures. In the Ising case, we obtain explicit expressions for speciation times by mapping the problem onto a random-field Ising model and solving it via the replica method. Our results provide a unified and broadly applicable description of speciation transitions in diffusion-based generative models.
Dynamical Learning in Deep Asymmetric Recurrent Neural Networks
Sep 05, 2025



We show that asymmetric deep recurrent neural networks, enhanced with additional sparse excitatory couplings, give rise to an exponentially large, dense accessible manifold of internal representations which can be found by different algorithms, including simple iterative dynamics. Building on the geometrical properties of the stable configurations, we propose a distributed learning scheme in which input-output associations emerge naturally from the recurrent dynamics, without any need of gradient evaluation. A critical feature enabling the learning process is the stability of the configurations reached at convergence, even after removal of the supervisory output signal. Extensive simulations demonstrate that this approach performs competitively on standard AI benchmarks. The model can be generalized in multiple directions, both computational and biological, potentially contributing to narrowing the gap between AI and computational neuroscience.
Why Diffusion Models Don't Memorize: The Role of Implicit Dynamical Regularization in Training
May 23, 2025Diffusion models have achieved remarkable success across a wide range of generative tasks. A key challenge is understanding the mechanisms that prevent their memorization of training data and allow generalization. In this work, we investigate the role of the training dynamics in the transition from generalization to memorization. Through extensive experiments and theoretical analysis, we identify two distinct timescales: an early time $\tau_\mathrm{gen}$ at which models begin to generate high-quality samples, and a later time $\tau_\mathrm{mem}$ beyond which memorization emerges. Crucially, we find that $\tau_\mathrm{mem}$ increases linearly with the training set size $n$, while $\tau_\mathrm{gen}$ remains constant. This creates a growing window of training times with $n$ where models generalize effectively, despite showing strong memorization if training continues beyond it. It is only when $n$ becomes larger than a model-dependent threshold that overfitting disappears at infinite training times. These findings reveal a form of implicit dynamical regularization in the training dynamics, which allow to avoid memorization even in highly overparameterized settings. Our results are supported by numerical experiments with standard U-Net architectures on realistic and synthetic datasets, and by a theoretical analysis using a tractable random features model studied in the high-dimensional limit.
How transformers learn structured data: insights from hierarchical filtering
Aug 27, 2024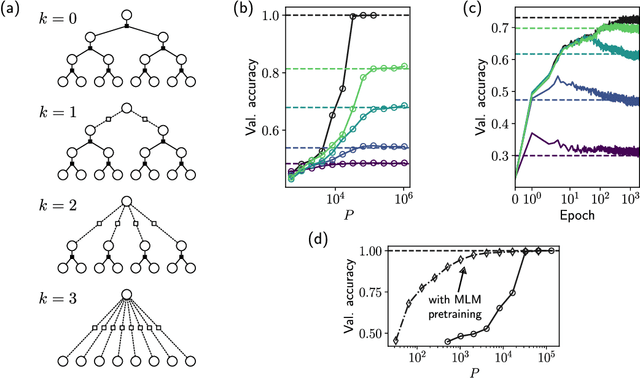
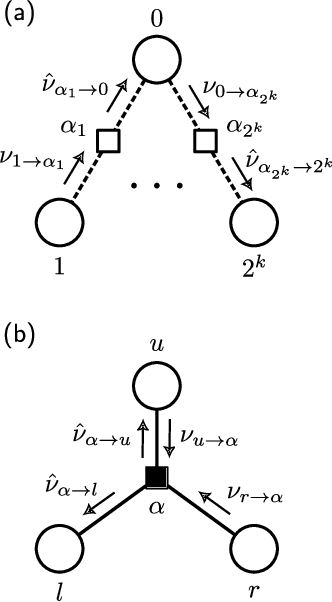

We introduce a hierarchical filtering procedure for generative models of sequences on trees, enabling control over the range of positional correlations in the data. Leveraging this controlled setting, we provide evidence that vanilla encoder-only transformer architectures can implement the optimal Belief Propagation algorithm on both root classification and masked language modeling tasks. Correlations at larger distances corresponding to increasing layers of the hierarchy are sequentially included as the network is trained. We analyze how the transformer layers succeed by focusing on attention maps from models trained with varying degrees of filtering. These attention maps show clear evidence for iterative hierarchical reconstruction of correlations, and we can relate these observations to a plausible implementation of the exact inference algorithm for the network sizes considered.
Kernel Density Estimators in Large Dimensions
Aug 11, 2024This paper studies Kernel density estimation for a high-dimensional distribution $\rho(x)$. Traditional approaches have focused on the limit of large number of data points $n$ and fixed dimension $d$. We analyze instead the regime where both the number $n$ of data points $y_i$ and their dimensionality $d$ grow with a fixed ratio $\alpha=(\log n)/d$. Our study reveals three distinct statistical regimes for the kernel-based estimate of the density $\hat \rho_h^{\mathcal {D}}(x)=\frac{1}{n h^d}\sum_{i=1}^n K\left(\frac{x-y_i}{h}\right)$, depending on the bandwidth $h$: a classical regime for large bandwidth where the Central Limit Theorem (CLT) holds, which is akin to the one found in traditional approaches. Below a certain value of the bandwidth, $h_{CLT}(\alpha)$, we find that the CLT breaks down. The statistics of $\hat \rho_h^{\mathcal {D}}(x)$ for a fixed $x$ drawn from $\rho(x)$ is given by a heavy-tailed distribution (an alpha-stable distribution). In particular below a value $h_G(\alpha)$, we find that $\hat \rho_h^{\mathcal {D}}(x)$ is governed by extreme value statistics: only a few points in the database matter and give the dominant contribution to the density estimator. We provide a detailed analysis for high-dimensional multivariate Gaussian data. We show that the optimal bandwidth threshold based on Kullback-Leibler divergence lies in the new statistical regime identified in this paper. Our findings reveal limitations of classical approaches, show the relevance of these new statistical regimes, and offer new insights for Kernel density estimation in high-dimensional settings.
Dynamical Regimes of Diffusion Models
Feb 28, 2024Using statistical physics methods, we study generative diffusion models in the regime where the dimension of space and the number of data are large, and the score function has been trained optimally. Our analysis reveals three distinct dynamical regimes during the backward generative diffusion process. The generative dynamics, starting from pure noise, encounters first a 'speciation' transition where the gross structure of data is unraveled, through a mechanism similar to symmetry breaking in phase transitions. It is followed at later time by a 'collapse' transition where the trajectories of the dynamics become attracted to one of the memorized data points, through a mechanism which is similar to the condensation in a glass phase. For any dataset, the speciation time can be found from a spectral analysis of the correlation matrix, and the collapse time can be found from the estimation of an 'excess entropy' in the data. The dependence of the collapse time on the dimension and number of data provides a thorough characterization of the curse of dimensionality for diffusion models. Analytical solutions for simple models like high-dimensional Gaussian mixtures substantiate these findings and provide a theoretical framework, while extensions to more complex scenarios and numerical validations with real datasets confirm the theoretical predictions.
The Decimation Scheme for Symmetric Matrix Factorization
Jul 31, 2023Matrix factorization is an inference problem that has acquired importance due to its vast range of applications that go from dictionary learning to recommendation systems and machine learning with deep networks. The study of its fundamental statistical limits represents a true challenge, and despite a decade-long history of efforts in the community, there is still no closed formula able to describe its optimal performances in the case where the rank of the matrix scales linearly with its size. In the present paper, we study this extensive rank problem, extending the alternative 'decimation' procedure that we recently introduced, and carry out a thorough study of its performance. Decimation aims at recovering one column/line of the factors at a time, by mapping the problem into a sequence of neural network models of associative memory at a tunable temperature. Though being sub-optimal, decimation has the advantage of being theoretically analyzable. We extend its scope and analysis to two families of matrices. For a large class of compactly supported priors, we show that the replica symmetric free entropy of the neural network models takes a universal form in the low temperature limit. For sparse Ising prior, we show that the storage capacity of the neural network models diverges as sparsity in the patterns increases, and we introduce a simple algorithm based on a ground state search that implements decimation and performs matrix factorization, with no need of an informative initialization.
Sparse Representations, Inference and Learning
Jun 28, 2023In recent years statistical physics has proven to be a valuable tool to probe into large dimensional inference problems such as the ones occurring in machine learning. Statistical physics provides analytical tools to study fundamental limitations in their solutions and proposes algorithms to solve individual instances. In these notes, based on the lectures by Marc M\'ezard in 2022 at the summer school in Les Houches, we will present a general framework that can be used in a large variety of problems with weak long-range interactions, including the compressed sensing problem, or the problem of learning in a perceptron. We shall see how these problems can be studied at the replica symmetric level, using developments of the cavity methods, both as a theoretical tool and as an algorithm.
Matrix factorization with neural networks
Dec 05, 2022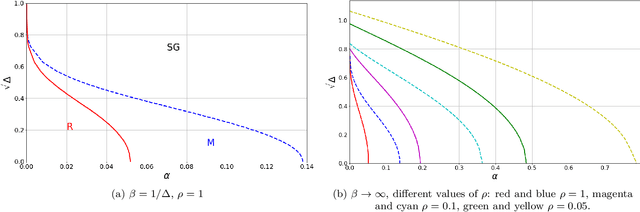
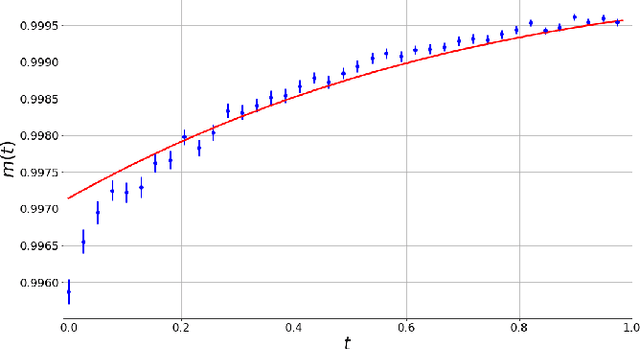
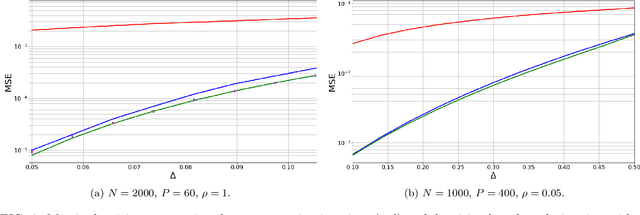
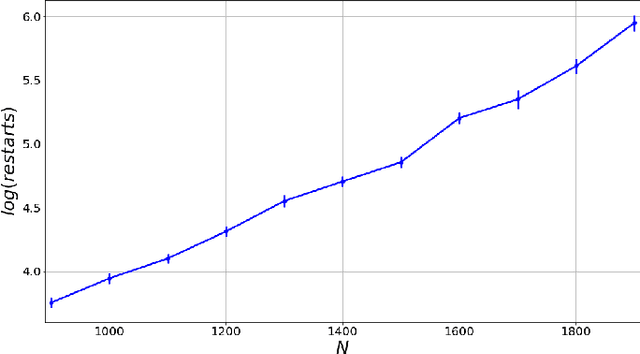
Matrix factorization is an important mathematical problem encountered in the context of dictionary learning, recommendation systems and machine learning. We introduce a new `decimation' scheme that maps it to neural network models of associative memory and provide a detailed theoretical analysis of its performance, showing that decimation is able to factorize extensive-rank matrices and to denoise them efficiently. We introduce a decimation algorithm based on ground-state search of the neural network, which shows performances that match the theoretical prediction.