 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic gradient descent in high dimensions for multi-spiked tensor PCA
Oct 23, 2024



We study the dynamics in high dimensions of online stochastic gradient descent for the multi-spiked tensor model. This multi-index model arises from the tensor principal component analysis (PCA) problem with multiple spikes, where the goal is to estimate $r$ unknown signal vectors within the $N$-dimensional unit sphere through maximum likelihood estimation from noisy observations of a $p$-tensor. We determine the number of samples and the conditions on the signal-to-noise ratios (SNRs) required to efficiently recover the unknown spikes from natural random initializations. We show that full recovery of all spikes is possible provided a number of sample scaling as $N^{p-2}$, matching the algorithmic threshold identified in the rank-one case [Ben Arous, Gheissari, Jagannath 2020, 2021]. Our results are obtained through a detailed analysis of a low-dimensional system that describes the evolution of the correlations between the estimators and the spikes, while controlling the noise in the dynamics. We find that the spikes are recovered sequentially in a process we term "sequential elimination": once a correlation exceeds a critical threshold, all correlations sharing a row or column index become sufficiently small, allowing the next correlation to grow and become macroscopic. The order in which correlations become macroscopic depends on their initial values and the corresponding SNRs, leading to either exact recovery or recovery of a permutation of the spikes. In the matrix case, when $p=2$, if the SNRs are sufficiently separated, we achieve exact recovery of the spikes, whereas equal SNRs lead to recovery of the subspace spanned by the spikes.
High-dimensional optimization for multi-spiked tensor PCA
Aug 12, 2024We study the dynamics of two local optimization algorithms, online stochastic gradient descent (SGD) and gradient flow, within the framework of the multi-spiked tensor model in the high-dimensional regime. This multi-index model arises from the tensor principal component analysis (PCA) problem, which aims to infer $r$ unknown, orthogonal signal vectors within the $N$-dimensional unit sphere through maximum likelihood estimation from noisy observations of an order-$p$ tensor. We determine the number of samples and the conditions on the signal-to-noise ratios (SNRs) required to efficiently recover the unknown spikes from natural initializations. Specifically, we distinguish between three types of recovery: exact recovery of each spike, recovery of a permutation of all spikes, and recovery of the correct subspace spanned by the signal vectors. We show that with online SGD, it is possible to recover all spikes provided a number of sample scaling as $N^{p-2}$, aligning with the computational threshold identified in the rank-one tensor PCA problem [Ben Arous, Gheissari, Jagannath 2020, 2021]. For gradient flow, we show that the algorithmic threshold to efficiently recover the first spike is also of order $N^{p-2}$. However, recovering the subsequent directions requires the number of samples to scale as $N^{p-1}$. Our results are obtained through a detailed analysis of a low-dimensional system that describes the evolution of the correlations between the estimators and the spikes. In particular, the hidden vectors are recovered one by one according to a sequential elimination phenomenon: as one correlation exceeds a critical threshold, all correlations sharing a row or column index decrease and become negligible, allowing the subsequent correlation to grow and become macroscopic. The sequence in which correlations become macroscopic depends on their initial values and on the associated SNRs.
Applying statistical learning theory to deep learning
Nov 26, 2023Although statistical learning theory provides a robust framework to understand supervised learning, many theoretical aspects of deep learning remain unclear, in particular how different architectures may lead to inductive bias when trained using gradient based methods. The goal of these lectures is to provide an overview of some of the main questions that arise when attempting to understand deep learning from a learning theory perspective. After a brief reminder on statistical learning theory and stochastic optimization, we discuss implicit bias in the context of benign overfitting. We then move to a general description of the mirror descent algorithm, showing how we may go back and forth between a parameter space and the corresponding function space for a given learning problem, as well as how the geometry of the learning problem may be represented by a metric tensor. Building on this framework, we provide a detailed study of the implicit bias of gradient descent on linear diagonal networks for various regression tasks, showing how the loss function, scale of parameters at initialization and depth of the network may lead to various forms of implicit bias, in particular transitioning between kernel or feature learning.
Learning curves for the multi-class teacher-student perceptron
Mar 22, 2022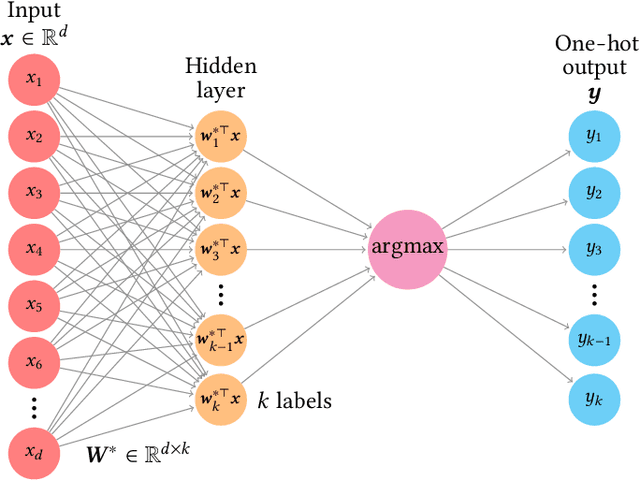
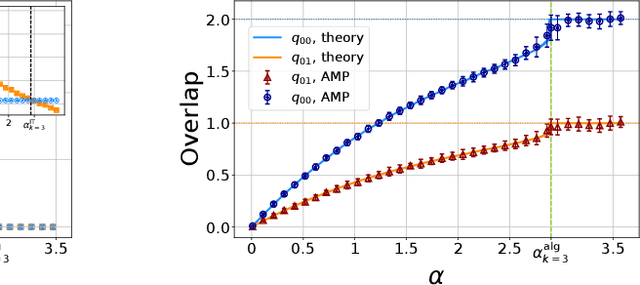
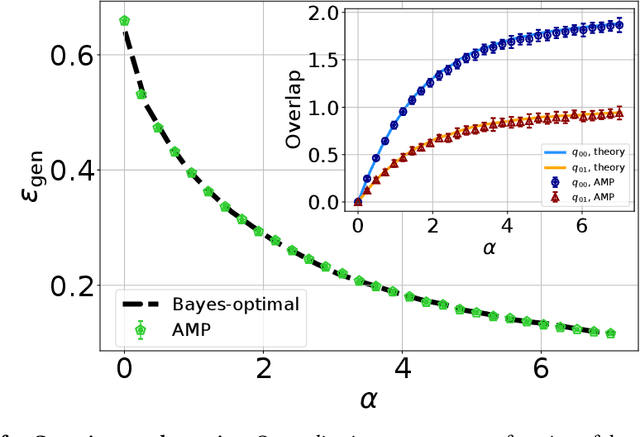
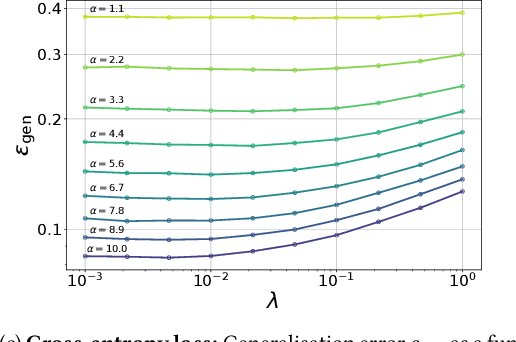
One of the most classical results in high-dimensional learning theory provides a closed-form expression for the generalisation error of binary classification with the single-layer teacher-student perceptron on i.i.d. Gaussian inputs. Both Bayes-optimal estimation and empirical risk minimisation (ERM) were extensively analysed for this setting. At the same time, a considerable part of modern machine learning practice concerns multi-class classification. Yet, an analogous analysis for the corresponding multi-class teacher-student perceptron was missing. In this manuscript we fill this gap by deriving and evaluating asymptotic expressions for both the Bayes-optimal and ERM generalisation errors in the high-dimensional regime. For Gaussian teacher weights, we investigate the performance of ERM with both cross-entropy and square losses, and explore the role of ridge regularisation in approaching Bayes-optimality. In particular, we observe that regularised cross-entropy minimisation yields close-to-optimal accuracy. Instead, for a binary teacher we show that a first-order phase transition arises in the Bayes-optimal performance.
Fluctuations, Bias, Variance & Ensemble of Learners: Exact Asymptotics for Convex Losses in High-Dimension
Jan 31, 2022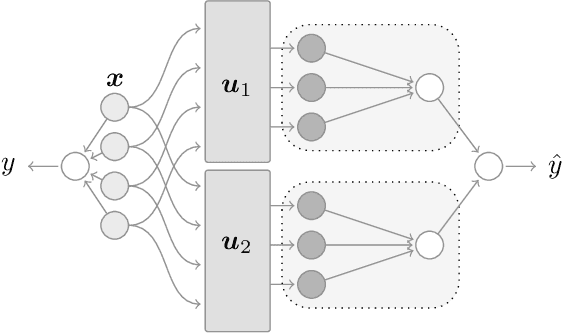
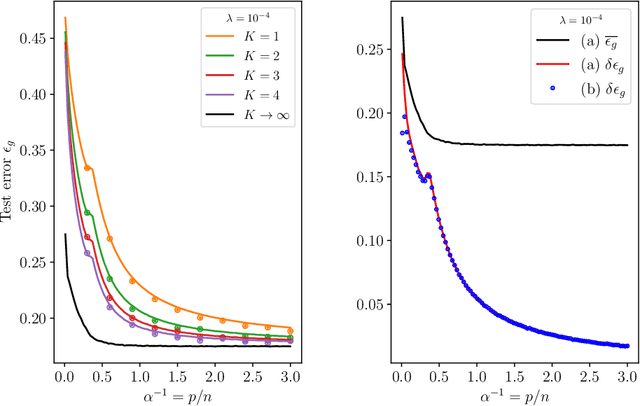
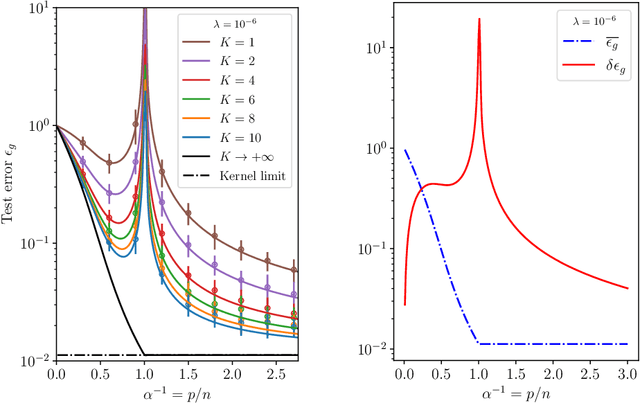
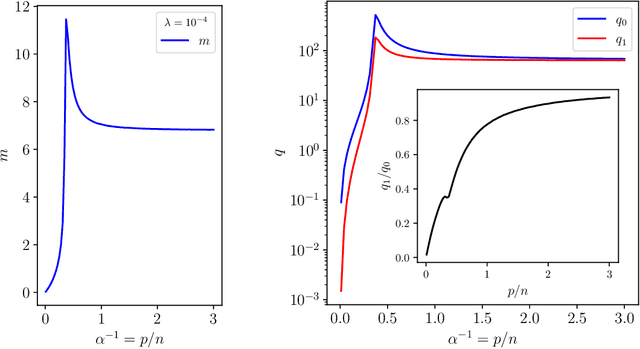
From the sampling of data to the initialisation of parameters, randomness is ubiquitous in modern Machine Learning practice. Understanding the statistical fluctuations engendered by the different sources of randomness in prediction is therefore key to understanding robust generalisation. In this manuscript we develop a quantitative and rigorous theory for the study of fluctuations in an ensemble of generalised linear models trained on different, but correlated, features in high-dimensions. In particular, we provide a complete description of the asymptotic joint distribution of the empirical risk minimiser for generic convex loss and regularisation in the high-dimensional limit. Our result encompasses a rich set of classification and regression tasks, such as the lazy regime of overparametrised neural networks, or equivalently the random features approximation of kernels. While allowing to study directly the mitigating effect of ensembling (or bagging) on the bias-variance decomposition of the test error, our analysis also helps disentangle the contribution of statistical fluctuations, and the singular role played by the interpolation threshold that are at the roots of the "double-descent" phenomenon.
Graph-based Approximate Message Passing Iterations
Sep 24, 2021Approximate-message passing (AMP) algorithms have become an important element of high-dimensional statistical inference, mostly due to their adaptability and concentration properties, the state evolution (SE) equations. This is demonstrated by the growing number of new iterations proposed for increasingly complex problems, ranging from multi-layer inference to low-rank matrix estimation with elaborate priors. In this paper, we address the following questions: is there a structure underlying all AMP iterations that unifies them in a common framework? Can we use such a structure to give a modular proof of state evolution equations, adaptable to new AMP iterations without reproducing each time the full argument ? We propose an answer to both questions, showing that AMP instances can be generically indexed by an oriented graph. This enables to give a unified interpretation of these iterations, independent from the problem they solve, and a way of composing them arbitrarily. We then show that all AMP iterations indexed by such a graph admit rigorous SE equations, extending the reach of previous proofs, and proving a number of recent heuristic derivations of those equations. Our proof naturally includes non-separable functions and we show how existing refinements, such as spatial coupling or matrix-valued variables, can be combined with our framework.
Learning Gaussian Mixtures with Generalised Linear Models: Precise Asymptotics in High-dimensions
Jun 07, 2021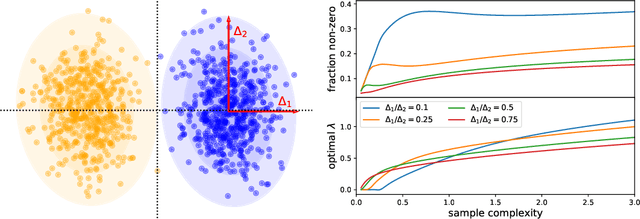
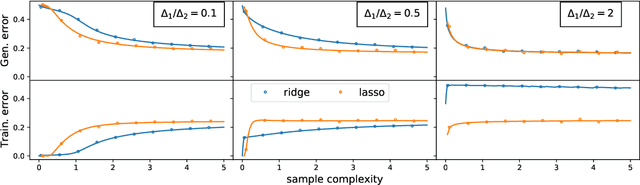
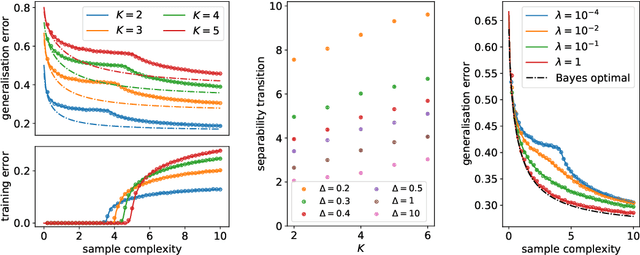
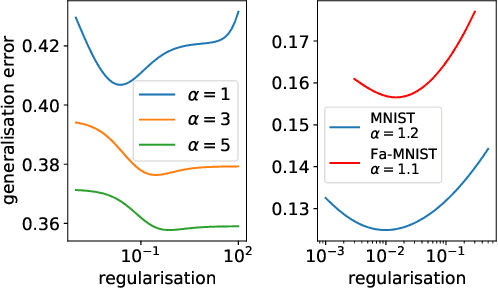
Generalised linear models for multi-class classification problems are one of the fundamental building blocks of modern machine learning tasks. In this manuscript, we characterise the learning of a mixture of $K$ Gaussians with generic means and covariances via empirical risk minimisation (ERM) with any convex loss and regularisation. In particular, we prove exact asymptotics characterising the ERM estimator in high-dimensions, extending several previous results about Gaussian mixture classification in the literature. We exemplify our result in two tasks of interest in statistical learning: a) classification for a mixture with sparse means, where we study the efficiency of $\ell_1$ penalty with respect to $\ell_2$; b) max-margin multi-class classification, where we characterise the phase transition on the existence of the multi-class logistic maximum likelihood estimator for $K>2$. Finally, we discuss how our theory can be applied beyond the scope of synthetic data, showing that in different cases Gaussian mixtures capture closely the learning curve of classification tasks in real data sets.
Capturing the learning curves of generic features maps for realistic data sets with a teacher-student model
Feb 16, 2021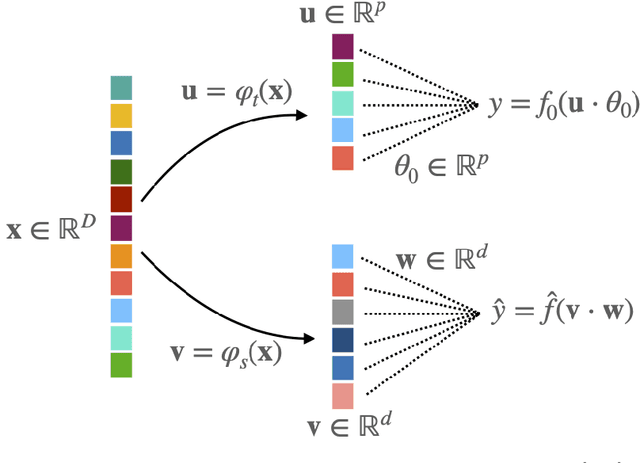
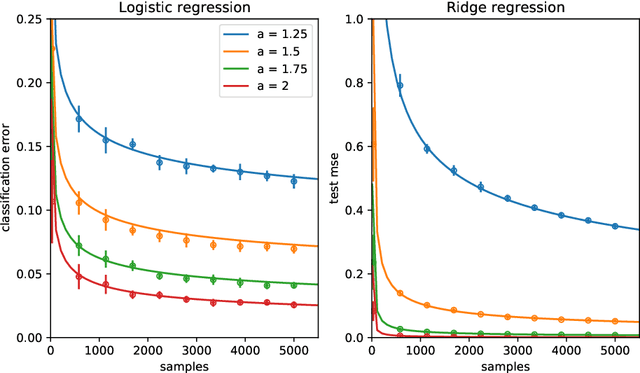
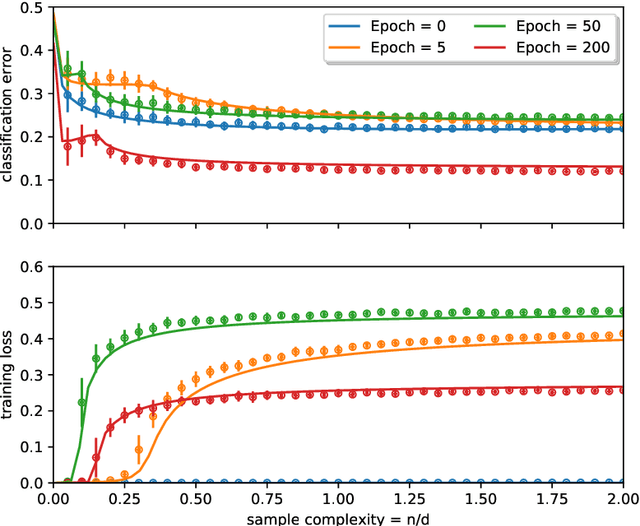
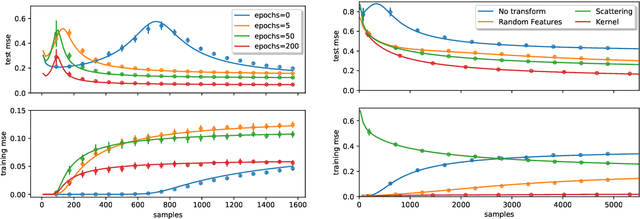
Teacher-student models provide a powerful framework in which the typical case performance of high-dimensional supervised learning tasks can be studied in closed form. In this setting, labels are assigned to data - often taken to be Gaussian i.i.d. - by a teacher model, and the goal is to characterise the typical performance of the student model in recovering the parameters that generated the labels. In this manuscript we discuss a generalisation of this setting where the teacher and student can act on different spaces, generated with fixed, but generic feature maps. This is achieved via the rigorous study of a high-dimensional Gaussian covariate model. Our contribution is two-fold: First, we prove a rigorous formula for the asymptotic training loss and generalisation error achieved by empirical risk minimization for this model. Second, we present a number of situations where the learning curve of the model captures the one of a \emph{realistic data set} learned with kernel regression and classification, with out-of-the-box feature maps such as random projections or scattering transforms, or with pre-learned ones - such as the features learned by training multi-layer neural networks. We discuss both the power and the limitations of the Gaussian teacher-student framework as a typical case analysis capturing learning curves as encountered in practice on real data sets.
Asymptotic errors for convex penalized linear regression beyond Gaussian matrices
Feb 11, 2020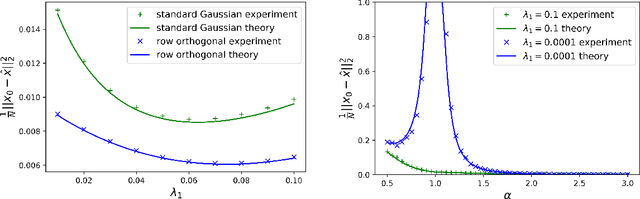
We consider the problem of learning a coefficient vector $x_{0}$ in $R^{N}$ from noisy linear observations $y=Fx_{0}+w$ in $R^{M}$ in the high dimensional limit $M,N$ to infinity with $\alpha=M/N$ fixed. We provide a rigorous derivation of an explicit formula -- first conjectured using heuristic methods from statistical physics -- for the asymptotic mean squared error obtained by penalized convex regression estimators such as the LASSO or the elastic net, for a class of very generic random matrices corresponding to rotationally invariant data matrices with arbitrary spectrum. The proof is based on a convergence analysis of an oracle version of vector approximate message-passing (oracle-VAMP) and on the properties of its state evolution equations. Our method leverages on and highlights the link between vector approximate message-passing, Douglas-Rachford splitting and proximal descent algorithms, extending previous results obtained with i.i.d. matrices for a large class of problems. We illustrate our results on some concrete examples and show that even though they are asymptotic, our predictions agree remarkably well with numerics even for very moderate sizes.