 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForward Learning with Top-Down Feedback: Empirical and Analytical Characterization
Feb 10, 2023



"Forward-only" algorithms, which train neural networks while avoiding a backward pass, have recently gained attention as a way of solving the biologically unrealistic aspects of backpropagation. Here, we first discuss the similarities between two "forward-only" algorithms, the Forward-Forward and PEPITA frameworks, and demonstrate that PEPITA is equivalent to a Forward-Forward with top-down feedback connections. Then, we focus on PEPITA to address compelling challenges related to the "forward-only" rules, which include providing an analytical understanding of their dynamics and reducing the gap between their performance and that of backpropagation. We propose a theoretical analysis of the dynamics of PEPITA. In particular, we show that PEPITA is well-approximated by an "adaptive-feedback-alignment" algorithm and we analytically track its performance during learning in a prototype high-dimensional setting. Finally, we develop a strategy to apply the weight mirroring algorithm on "forward-only" algorithms with top-down feedback and we show how it impacts PEPITA's accuracy and convergence rate.
Neural networks trained with SGD learn distributions of increasing complexity
Nov 21, 2022The ability of deep neural networks to generalise well even when they interpolate their training data has been explained using various "simplicity biases". These theories postulate that neural networks avoid overfitting by first learning simple functions, say a linear classifier, before learning more complex, non-linear functions. Meanwhile, data structure is also recognised as a key ingredient for good generalisation, yet its role in simplicity biases is not yet understood. Here, we show that neural networks trained using stochastic gradient descent initially classify their inputs using lower-order input statistics, like mean and covariance, and exploit higher-order statistics only later during training. We first demonstrate this distributional simplicity bias (DSB) in a solvable model of a neural network trained on synthetic data. We empirically demonstrate DSB in a range of deep convolutional networks and visual transformers trained on CIFAR10, and show that it even holds in networks pre-trained on ImageNet. We discuss the relation of DSB to other simplicity biases and consider its implications for the principle of Gaussian universality in learning.
Optimal learning rate schedules in high-dimensional non-convex optimization problems
Feb 09, 2022



Learning rate schedules are ubiquitously used to speed up and improve optimisation. Many different policies have been introduced on an empirical basis, and theoretical analyses have been developed for convex settings. However, in many realistic problems the loss-landscape is high-dimensional and non convex -- a case for which results are scarce. In this paper we present a first analytical study of the role of learning rate scheduling in this setting, focusing on Langevin optimization with a learning rate decaying as $\eta(t)=t^{-\beta}$. We begin by considering models where the loss is a Gaussian random function on the $N$-dimensional sphere ($N\rightarrow \infty$), featuring an extensive number of critical points. We find that to speed up optimization without getting stuck in saddles, one must choose a decay rate $\beta<1$, contrary to convex setups where $\beta=1$ is generally optimal. We then add to the problem a signal to be recovered. In this setting, the dynamics decompose into two phases: an \emph{exploration} phase where the dynamics navigates through rough parts of the landscape, followed by a \emph{convergence} phase where the signal is detected and the dynamics enter a convex basin. In this case, it is optimal to keep a large learning rate during the exploration phase to escape the non-convex region as quickly as possible, then use the convex criterion $\beta=1$ to converge rapidly to the solution. Finally, we demonstrate that our conclusions hold in a common regression task involving neural networks.
Fluctuations, Bias, Variance & Ensemble of Learners: Exact Asymptotics for Convex Losses in High-Dimension
Jan 31, 2022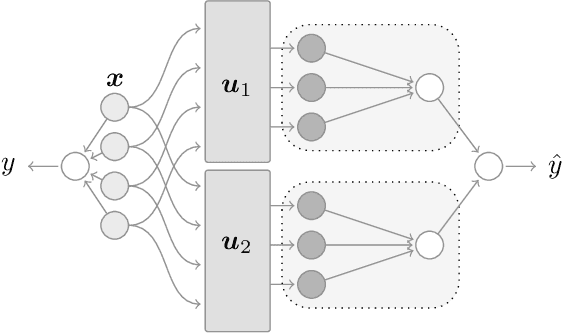
From the sampling of data to the initialisation of parameters, randomness is ubiquitous in modern Machine Learning practice. Understanding the statistical fluctuations engendered by the different sources of randomness in prediction is therefore key to understanding robust generalisation. In this manuscript we develop a quantitative and rigorous theory for the study of fluctuations in an ensemble of generalised linear models trained on different, but correlated, features in high-dimensions. In particular, we provide a complete description of the asymptotic joint distribution of the empirical risk minimiser for generic convex loss and regularisation in the high-dimensional limit. Our result encompasses a rich set of classification and regression tasks, such as the lazy regime of overparametrised neural networks, or equivalently the random features approximation of kernels. While allowing to study directly the mitigating effect of ensembling (or bagging) on the bias-variance decomposition of the test error, our analysis also helps disentangle the contribution of statistical fluctuations, and the singular role played by the interpolation threshold that are at the roots of the "double-descent" phenomenon.
The dynamics of representation learning in shallow, non-linear autoencoders
Jan 06, 2022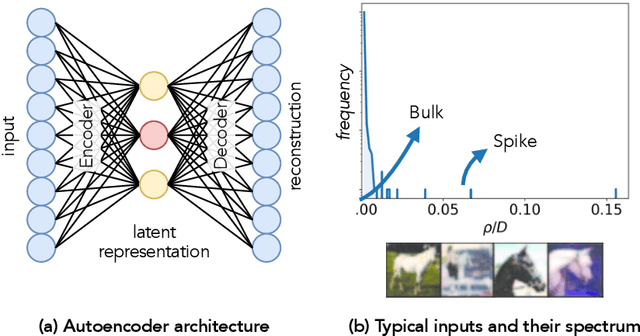
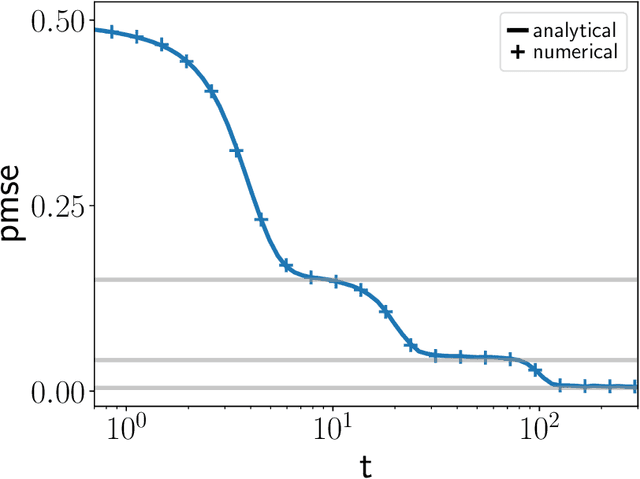

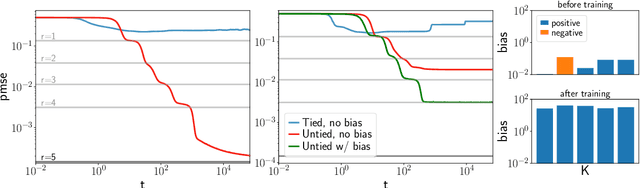
Autoencoders are the simplest neural network for unsupervised learning, and thus an ideal framework for studying feature learning. While a detailed understanding of the dynamics of linear autoencoders has recently been obtained, the study of non-linear autoencoders has been hindered by the technical difficulty of handling training data with non-trivial correlations - a fundamental prerequisite for feature extraction. Here, we study the dynamics of feature learning in non-linear, shallow autoencoders. We derive a set of asymptotically exact equations that describe the generalisation dynamics of autoencoders trained with stochastic gradient descent (SGD) in the limit of high-dimensional inputs. These equations reveal that autoencoders learn the leading principal components of their inputs sequentially. An analysis of the long-time dynamics explains the failure of sigmoidal autoencoders to learn with tied weights, and highlights the importance of training the bias in ReLU autoencoders. Building on previous results for linear networks, we analyse a modification of the vanilla SGD algorithm which allows learning of the exact principal components. Finally, we show that our equations accurately describe the generalisation dynamics of non-linear autoencoders on realistic datasets such as CIFAR10.
Classifying high-dimensional Gaussian mixtures: Where kernel methods fail and neural networks succeed
Feb 23, 2021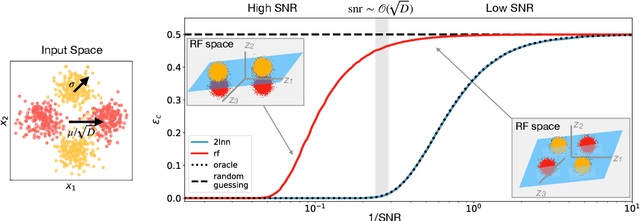
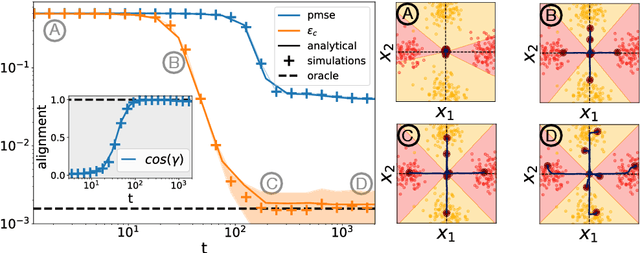
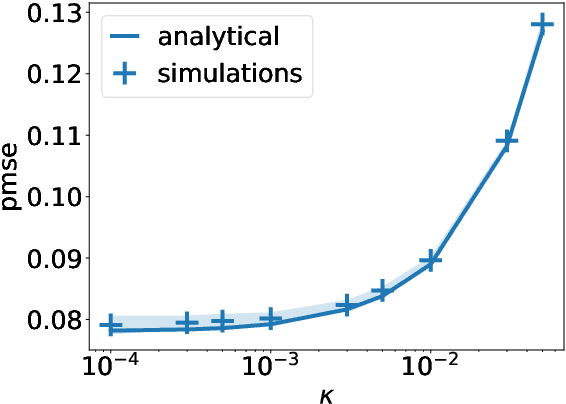
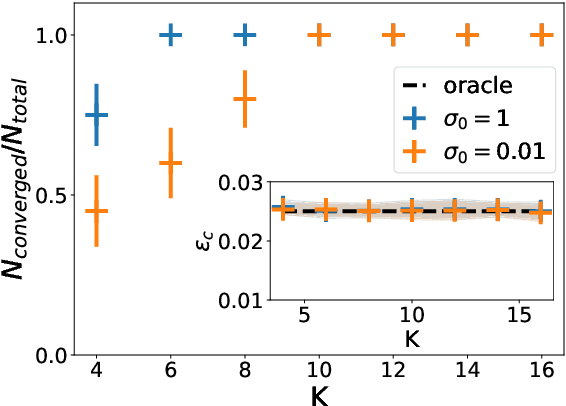
A recent series of theoretical works showed that the dynamics of neural networks with a certain initialisation are well-captured by kernel methods. Concurrent empirical work demonstrated that kernel methods can come close to the performance of neural networks on some image classification tasks. These results raise the question of whether neural networks only learn successfully if kernels also learn successfully, despite neural networks being more expressive. Here, we show theoretically that two-layer neural networks (2LNN) with only a few hidden neurons can beat the performance of kernel learning on a simple Gaussian mixture classification task. We study the high-dimensional limit where the number of samples is linearly proportional to the input dimension, and show that while small 2LNN achieve near-optimal performance on this task, lazy training approaches such as random features and kernel methods do not. Our analysis is based on the derivation of a closed set of equations that track the learning dynamics of the 2LNN and thus allow to extract the asymptotic performance of the network as a function of signal-to-noise ratio and other hyperparameters. We finally illustrate how over-parametrising the neural network leads to faster convergence, but does not improve its final performance.
The dynamics of learning with feedback alignment
Nov 24, 2020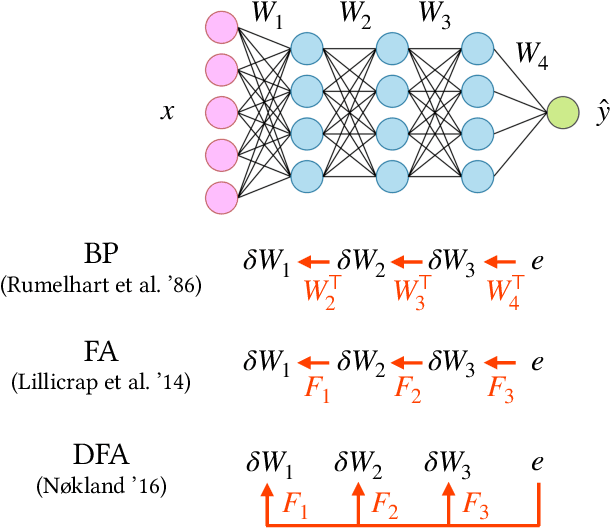
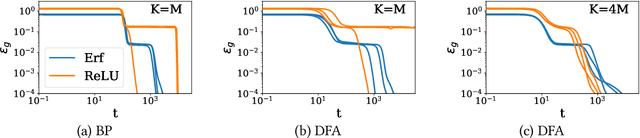
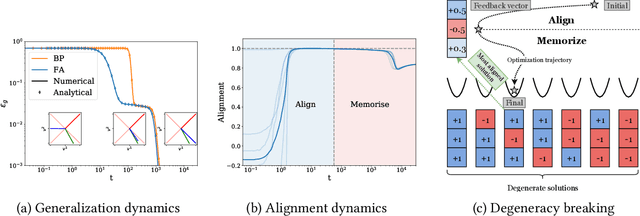
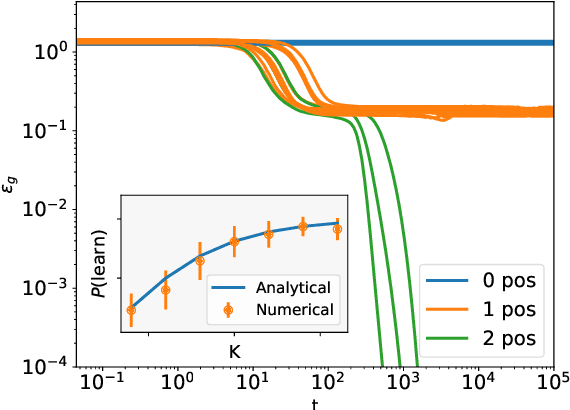
Direct Feedback Alignment (DFA) is emerging as an efficient and biologically plausible alternative to the ubiquitous backpropagation algorithm for training deep neural networks. Despite relying on random feedback weights for the backward pass, DFA successfully trains state-of-the-art models such as Transformers. On the other hand, it notoriously fails to train convolutional networks. An understanding of the inner workings of DFA to explain these diverging results remains elusive. Here, we propose a theory for the success of DFA. We first show that learning in shallow networks proceeds in two steps: an alignment phase, where the model adapts its weights to align the approximate gradient with the true gradient of the loss function, is followed by a memorisation phase, where the model focuses on fitting the data. This two-step process has a degeneracy breaking effect: out of all the low-loss solutions in the landscape, a network trained with DFA naturally converges to the solution which maximises gradient alignment. We also identify a key quantity underlying alignment in deep linear networks: the conditioning of the alignment matrices. The latter enables a detailed understanding of the impact of data structure on alignment, and suggests a simple explanation for the well-known failure of DFA to train convolutional neural networks. Numerical experiments on MNIST and CIFAR10 clearly demonstrate degeneracy breaking in deep non-linear networks and show that the align-then-memorize process occurs sequentially from the bottom layers of the network to the top.
Epidemic mitigation by statistical inference from contact tracing data
Sep 20, 2020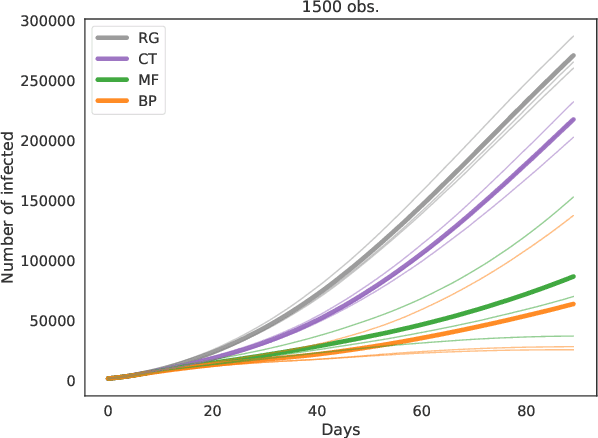
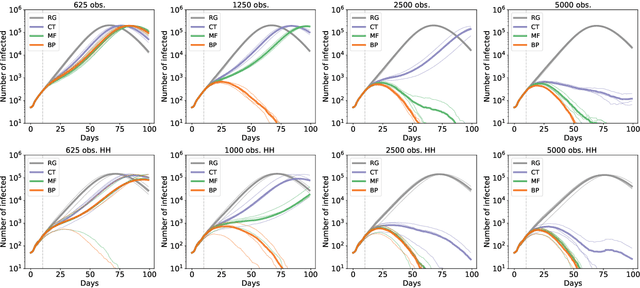
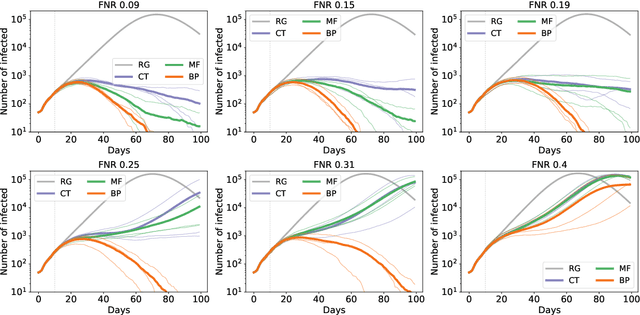

Contact-tracing is an essential tool in order to mitigate the impact of pandemic such as the COVID-19. In order to achieve efficient and scalable contact-tracing in real time, digital devices can play an important role. While a lot of attention has been paid to analyzing the privacy and ethical risks of the associated mobile applications, so far much less research has been devoted to optimizing their performance and assessing their impact on the mitigation of the epidemic. We develop Bayesian inference methods to estimate the risk that an individual is infected. This inference is based on the list of his recent contacts and their own risk levels, as well as personal information such as results of tests or presence of syndromes. We propose to use probabilistic risk estimation in order to optimize testing and quarantining strategies for the control of an epidemic. Our results show that in some range of epidemic spreading (typically when the manual tracing of all contacts of infected people becomes practically impossible, but before the fraction of infected people reaches the scale where a lock-down becomes unavoidable), this inference of individuals at risk could be an efficient way to mitigate the epidemic. Our approaches translate into fully distributed algorithms that only require communication between individuals who have recently been in contact. Such communication may be encrypted and anonymized and thus compatible with privacy preserving standards. We conclude that probabilistic risk estimation is capable to enhance performance of digital contact tracing and should be considered in the currently developed mobile applications.
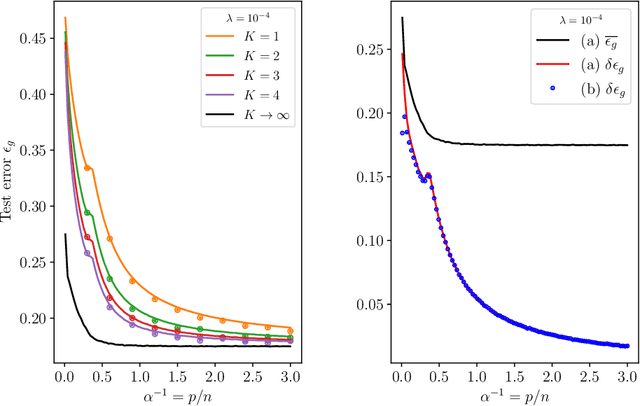
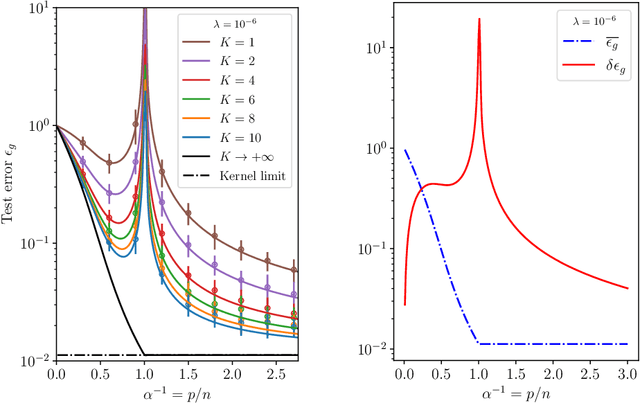
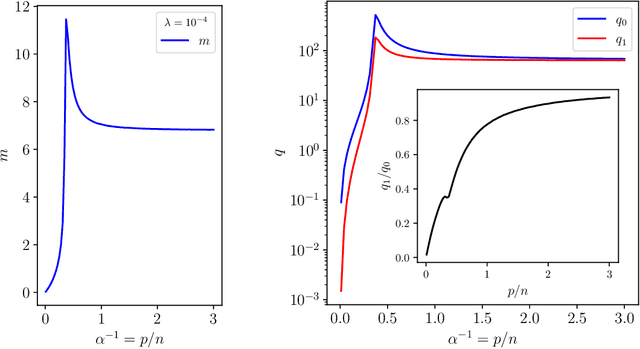
Double Trouble in Double Descent : Bias and Variance in the Lazy Regime
Apr 03, 2020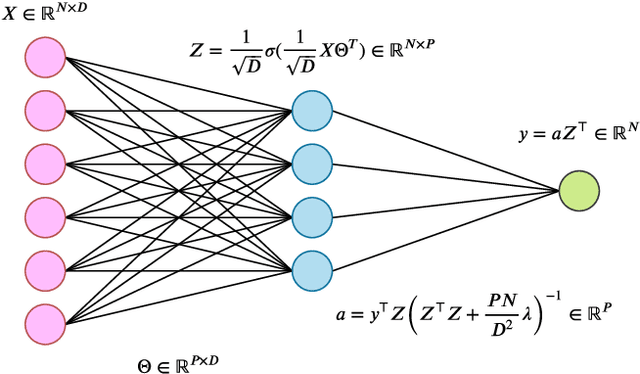
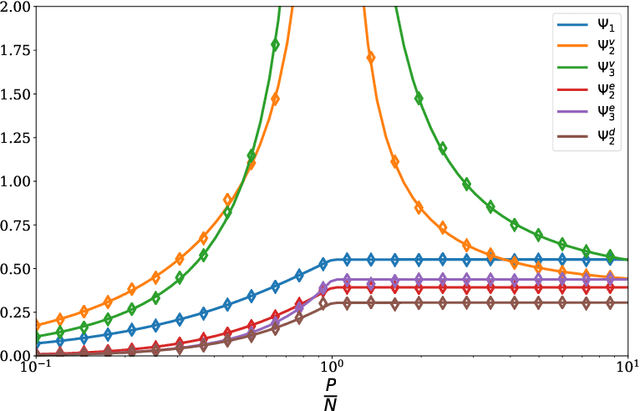
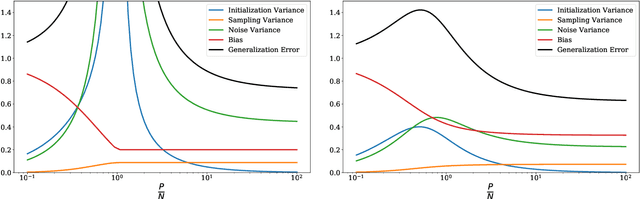
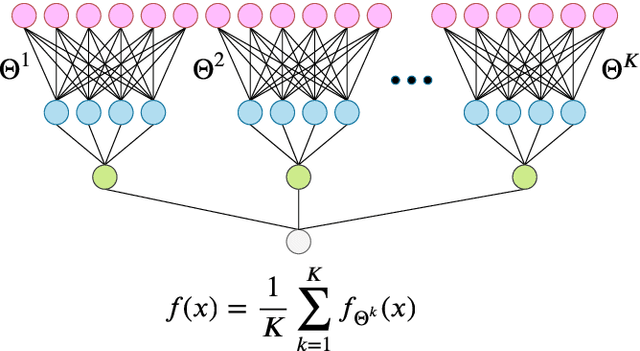
Deep neural networks can achieve remarkable generalization performances while interpolating the training data perfectly. Rather than the U-curve emblematic of the bias-variance trade-off, their test error often follows a "double descent" - a mark of the beneficial role of overparametrization. In this work, we develop a quantitative theory for this phenomenon in the so-called lazy learning regime of neural networks, by considering the problem of learning a high-dimensional function with random features regression. We obtain a precise asymptotic expression for the bias-variance decomposition of the test error, and show that the bias displays a phase transition at the interpolation threshold, beyond which it remains constant. We disentangle the variances stemming from the sampling of the dataset, from the additive noise corrupting the labels, and from the initialization of the weights. Following up on Geiger et al. 2019, we first show that the latter two contributions are the crux of the double descent: they lead to the overfitting peak at the interpolation threshold and to the decay of the test error upon overparametrization. We then quantify how they are suppressed by ensemble averaging the outputs of K independently initialized estimators. When K is sent to infinity, the test error remains constant beyond the interpolation threshold. We further compare the effects of overparametrizing, ensembling and regularizing. Finally, we present numerical experiments on classic deep learning setups to show that our results hold qualitatively in realistic lazy learning scenarios.