 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Biologically Plausible Adversarial Training
Oct 05, 2023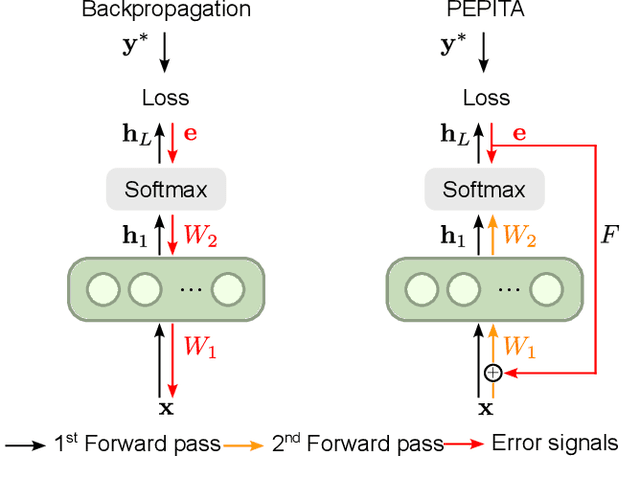


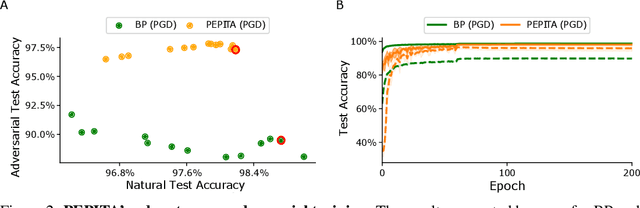
Artificial Neural Networks (ANNs) trained with Backpropagation (BP) show astounding performance and are increasingly often used in performing our daily life tasks. However, ANNs are highly vulnerable to adversarial attacks, which alter inputs with small targeted perturbations that drastically disrupt the models' performance. The most effective method to make ANNs robust against these attacks is adversarial training, in which the training dataset is augmented with exemplary adversarial samples. Unfortunately, this approach has the drawback of increased training complexity since generating adversarial samples is very computationally demanding. In contrast to ANNs, humans are not susceptible to adversarial attacks. Therefore, in this work, we investigate whether biologically-plausible learning algorithms are more robust against adversarial attacks than BP. In particular, we present an extensive comparative analysis of the adversarial robustness of BP and Present the Error to Perturb the Input To modulate Activity (PEPITA), a recently proposed biologically-plausible learning algorithm, on various computer vision tasks. We observe that PEPITA has higher intrinsic adversarial robustness and, with adversarial training, has a more favourable natural-vs-adversarial performance trade-off as, for the same natural accuracies, PEPITA's adversarial accuracies decrease in average by 0.26% and BP's by 8.05%.
Forward Learning with Top-Down Feedback: Empirical and Analytical Characterization
Feb 10, 2023



"Forward-only" algorithms, which train neural networks while avoiding a backward pass, have recently gained attention as a way of solving the biologically unrealistic aspects of backpropagation. Here, we first discuss the similarities between two "forward-only" algorithms, the Forward-Forward and PEPITA frameworks, and demonstrate that PEPITA is equivalent to a Forward-Forward with top-down feedback connections. Then, we focus on PEPITA to address compelling challenges related to the "forward-only" rules, which include providing an analytical understanding of their dynamics and reducing the gap between their performance and that of backpropagation. We propose a theoretical analysis of the dynamics of PEPITA. In particular, we show that PEPITA is well-approximated by an "adaptive-feedback-alignment" algorithm and we analytically track its performance during learning in a prototype high-dimensional setting. Finally, we develop a strategy to apply the weight mirroring algorithm on "forward-only" algorithms with top-down feedback and we show how it impacts PEPITA's accuracy and convergence rate.
Human or Machine? Turing Tests for Vision and Language
Nov 23, 2022As AI algorithms increasingly participate in daily activities that used to be the sole province of humans, we are inevitably called upon to consider how much machines are really like us. To address this question, we turn to the Turing test and systematically benchmark current AIs in their abilities to imitate humans. We establish a methodology to evaluate humans versus machines in Turing-like tests and systematically evaluate a representative set of selected domains, parameters, and variables. The experiments involved testing 769 human agents, 24 state-of-the-art AI agents, 896 human judges, and 8 AI judges, in 21,570 Turing tests across 6 tasks encompassing vision and language modalities. Surprisingly, the results reveal that current AIs are not far from being able to impersonate human judges across different ages, genders, and educational levels in complex visual and language challenges. In contrast, simple AI judges outperform human judges in distinguishing human answers versus machine answers. The curated large-scale Turing test datasets introduced here and their evaluation metrics provide valuable insights to assess whether an agent is human or not. The proposed formulation to benchmark human imitation ability in current AIs paves a way for the research community to expand Turing tests to other research areas and conditions. All of source code and data are publicly available at https://tinyurl.com/8x8nha7p
Error-driven Input Modulation: Solving the Credit Assignment Problem without a Backward Pass
Jan 27, 2022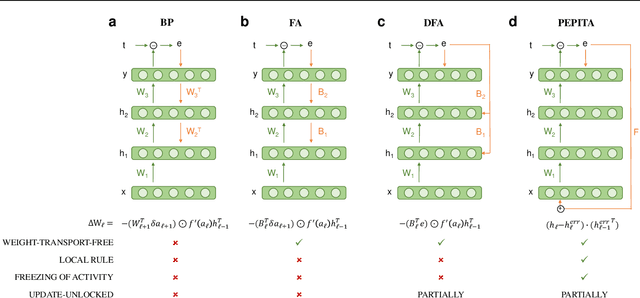

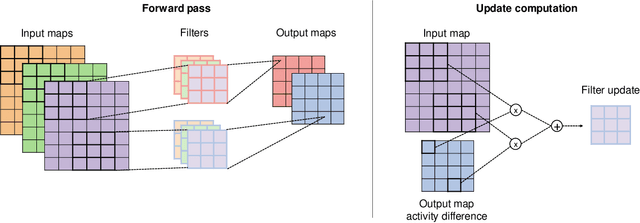
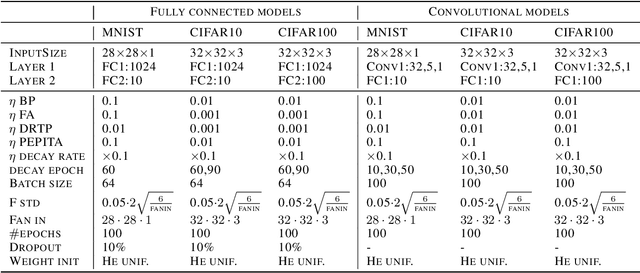
Supervised learning in artificial neural networks typically relies on backpropagation, where the weights are updated based on the error-function gradients and sequentially propagated from the output layer to the input layer. Although this approach has proven effective in a wide domain of applications, it lacks biological plausibility in many regards, including the weight symmetry problem, the dependence of learning on non-local signals, the freezing of neural activity during error propagation, and the update locking problem. Alternative training schemes - such as sign symmetry, feedback alignment, and direct feedback alignment - have been introduced, but invariably rely on a backward pass that hinders the possibility of solving all the issues simultaneously. Here, we propose to replace the backward pass with a second forward pass in which the input signal is modulated based on the error of the network. We show that this novel learning rule comprehensively addresses all the above-mentioned issues and can be applied to both fully connected and convolutional models. We test this learning rule on MNIST, CIFAR-10, and CIFAR-100. These results help incorporate biological principles into machine learning.
Modeling the Repetition-based Recovering of Acoustic and Visual Sources with Dendritic Neurons
Jan 16, 2022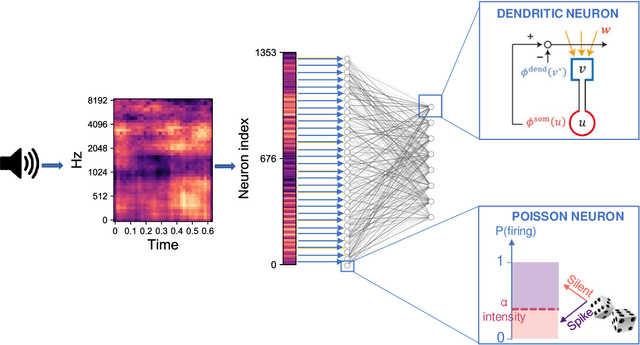
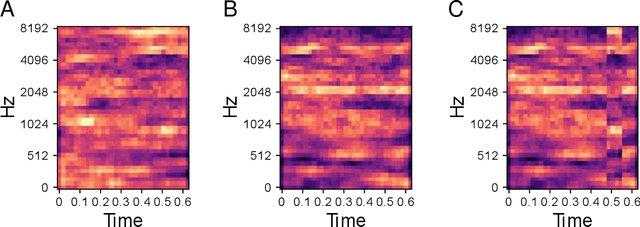
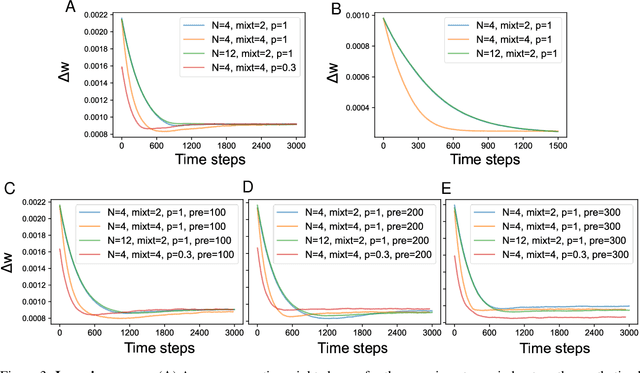
In natural auditory environments, acoustic signals originate from the temporal superimposition of different sound sources. The problem of inferring individual sources from ambiguous mixtures of sounds is known as blind source decomposition. Experiments on humans have demonstrated that the auditory system can identify sound sources as repeating patterns embedded in the acoustic input. Source repetition produces temporal regularities that can be detected and used for segregation. Specifically, listeners can identify sounds occurring more than once across different mixtures, but not sounds heard only in a single mixture. However, whether such a behaviour can be computationally modelled has not yet been explored. Here, we propose a biologically inspired computational model to perform blind source separation on sequences of mixtures of acoustic stimuli. Our method relies on a somatodendritic neuron model trained with a Hebbian-like learning rule which can detect spatio-temporal patterns recurring in synaptic inputs. We show that the segregation capabilities of our model are reminiscent of the features of human performance in a variety of experimental settings involving synthesized sounds with naturalistic properties. Furthermore, we extend the study to investigate the properties of segregation on task settings not yet explored with human subjects, namely natural sounds and images. Overall, our work suggests that somatodendritic neuron models offer a promising neuro-inspired learning strategy to account for the characteristics of the brain segregation capabilities as well as to make predictions on yet untested experimental settings.
Learning in Deep Neural Networks Using a Biologically Inspired Optimizer
Apr 23, 2021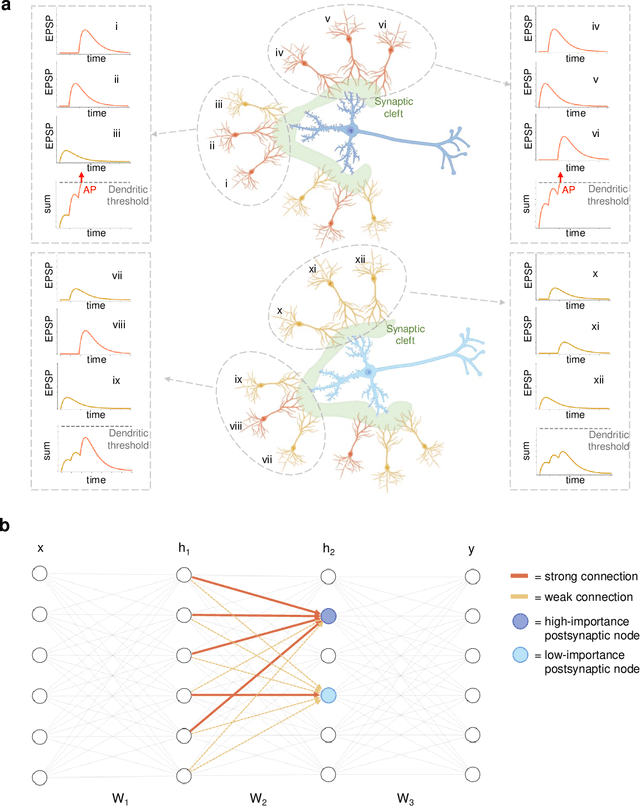
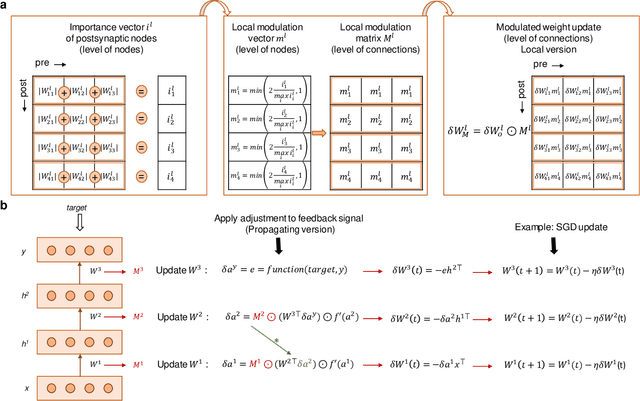
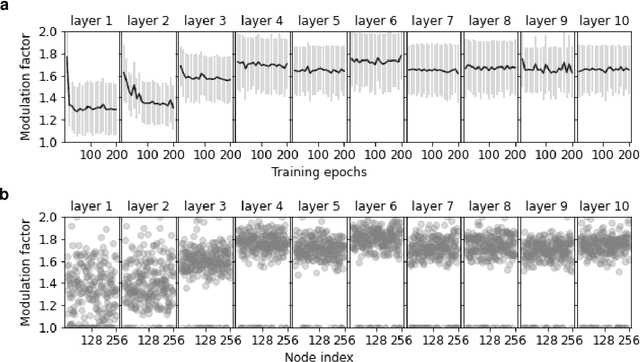
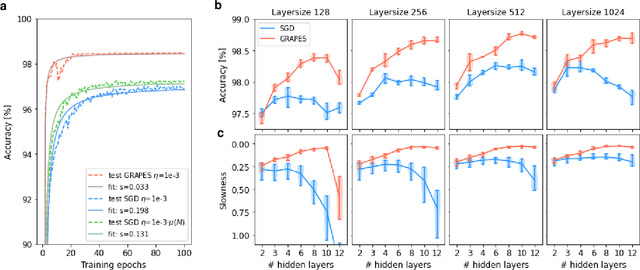
Plasticity circuits in the brain are known to be influenced by the distribution of the synaptic weights through the mechanisms of synaptic integration and local regulation of synaptic strength. However, the complex interplay of stimulation-dependent plasticity with local learning signals is disregarded by most of the artificial neural network training algorithms devised so far. Here, we propose a novel biologically inspired optimizer for artificial (ANNs) and spiking neural networks (SNNs) that incorporates key principles of synaptic integration observed in dendrites of cortical neurons: GRAPES (Group Responsibility for Adjusting the Propagation of Error Signals). GRAPES implements a weight-distribution dependent modulation of the error signal at each node of the neural network. We show that this biologically inspired mechanism leads to a systematic improvement of the convergence rate of the network, and substantially improves classification accuracy of ANNs and SNNs with both feedforward and recurrent architectures. Furthermore, we demonstrate that GRAPES supports performance scalability for models of increasing complexity and mitigates catastrophic forgetting by enabling networks to generalize to unseen tasks based on previously acquired knowledge. The local characteristics of GRAPES minimize the required memory resources, making it optimally suited for dedicated hardware implementations. Overall, our work indicates that reconciling neurophysiology insights with machine intelligence is key to boosting the performance of neural networks.
Spiking neural networks trained with backpropagation for low power neuromorphic implementation of voice activity detection
Oct 22, 2019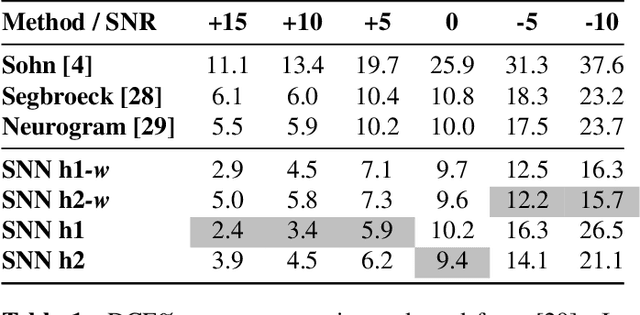
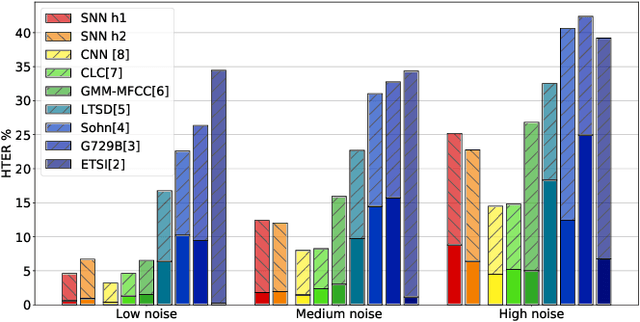
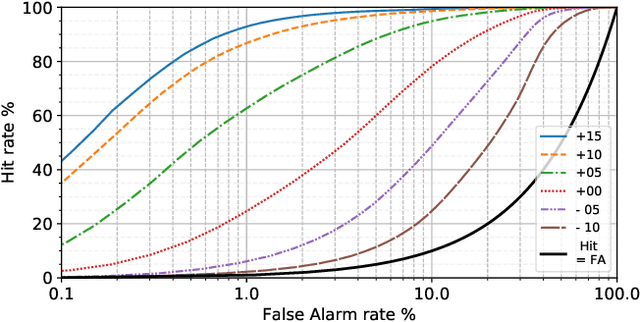
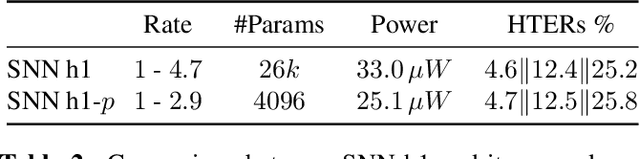
Recent advances in Voice Activity Detection (VAD) are driven by artificial and Recurrent Neural Networks (RNNs), however, using a VAD system in battery-operated devices requires further power efficiency. This can be achieved by neuromorphic hardware, which enables Spiking Neural Networks (SNNs) to perform inference at very low energy consumption. Spiking networks are characterized by their ability to process information efficiently, in a sparse cascade of binary events in time called spikes. However, a big performance gap separates artificial from spiking networks, mostly due to a lack of powerful SNN training algorithms. To overcome this problem we exploit an SNN model that can be recast into an RNN-like model and trained with known deep learning techniques. We describe an SNN training procedure that achieves low spiking activity and pruning algorithms to remove 85% of the network connections with no performance loss. The model achieves state-of-the-art performance with a fraction of power consumption comparing to other methods.