 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvertrained Language Models Are Harder to Fine-Tune
Mar 24, 2025



Large language models are pre-trained on ever-growing token budgets under the assumption that better pre-training performance translates to improved downstream models. In this work, we challenge this assumption and show that extended pre-training can make models harder to fine-tune, leading to degraded final performance. We term this phenomenon catastrophic overtraining. For example, the instruction-tuned OLMo-1B model pre-trained on 3T tokens leads to over 2% worse performance on multiple standard LLM benchmarks than its 2.3T token counterpart. Through controlled experiments and theoretical analysis, we show that catastrophic overtraining arises from a systematic increase in the broad sensitivity of pre-trained parameters to modifications, including but not limited to fine-tuning. Our findings call for a critical reassessment of pre-training design that considers the downstream adaptability of the model.
Scaling Laws for Precision
Nov 07, 2024Low precision training and inference affect both the quality and cost of language models, but current scaling laws do not account for this. In this work, we devise "precision-aware" scaling laws for both training and inference. We propose that training in lower precision reduces the model's "effective parameter count," allowing us to predict the additional loss incurred from training in low precision and post-train quantization. For inference, we find that the degradation introduced by post-training quantization increases as models are trained on more data, eventually making additional pretraining data actively harmful. For training, our scaling laws allow us to predict the loss of a model with different parts in different precisions, and suggest that training larger models in lower precision may be compute optimal. We unify the scaling laws for post and pretraining quantization to arrive at a single functional form that predicts degradation from training and inference in varied precisions. We fit on over 465 pretraining runs and validate our predictions on model sizes up to 1.7B parameters trained on up to 26B tokens.
Do Mice Grok? Glimpses of Hidden Progress During Overtraining in Sensory Cortex
Nov 05, 2024



Does learning of task-relevant representations stop when behavior stops changing? Motivated by recent theoretical advances in machine learning and the intuitive observation that human experts continue to learn from practice even after mastery, we hypothesize that task-specific representation learning can continue, even when behavior plateaus. In a novel reanalysis of recently published neural data, we find evidence for such learning in posterior piriform cortex of mice following continued training on a task, long after behavior saturates at near-ceiling performance ("overtraining"). This learning is marked by an increase in decoding accuracy from piriform neural populations and improved performance on held-out generalization tests. We demonstrate that class representations in cortex continue to separate during overtraining, so that examples that were incorrectly classified at the beginning of overtraining can abruptly be correctly classified later on, despite no changes in behavior during that time. We hypothesize this hidden yet rich learning takes the form of approximate margin maximization; we validate this and other predictions in the neural data, as well as build and interpret a simple synthetic model that recapitulates these phenomena. We conclude by showing how this model of late-time feature learning implies an explanation for the empirical puzzle of overtraining reversal in animal learning, where task-specific representations are more robust to particular task changes because the learned features can be reused.
No Free Prune: Information-Theoretic Barriers to Pruning at Initialization
Feb 02, 2024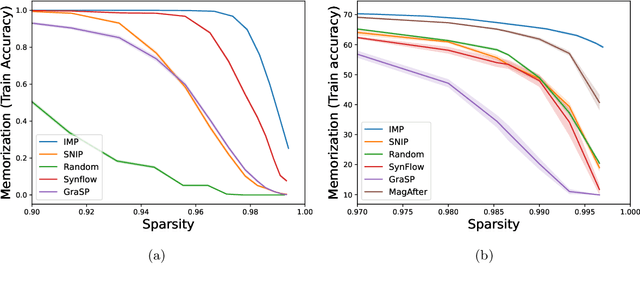
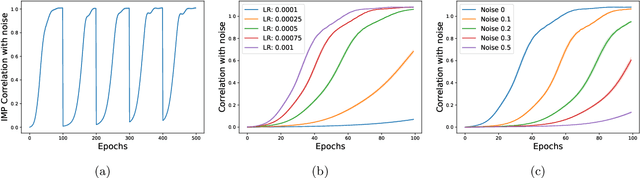
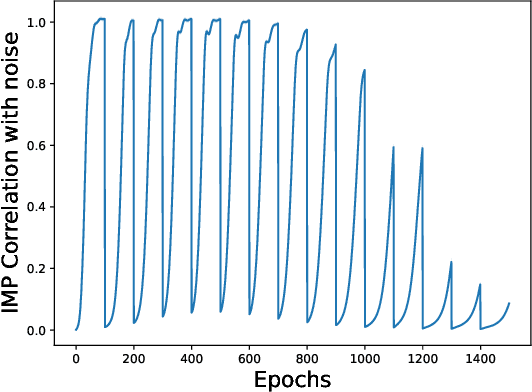
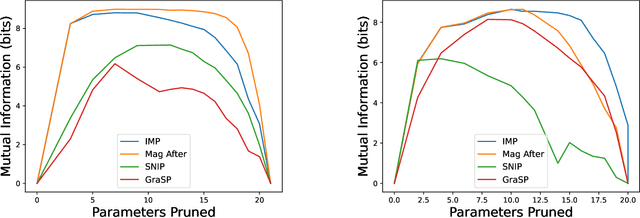
The existence of "lottery tickets" arXiv:1803.03635 at or near initialization raises the tantalizing question of whether large models are necessary in deep learning, or whether sparse networks can be quickly identified and trained without ever training the dense models that contain them. However, efforts to find these sparse subnetworks without training the dense model ("pruning at initialization") have been broadly unsuccessful arXiv:2009.08576. We put forward a theoretical explanation for this, based on the model's effective parameter count, $p_\text{eff}$, given by the sum of the number of non-zero weights in the final network and the mutual information between the sparsity mask and the data. We show the Law of Robustness of arXiv:2105.12806 extends to sparse networks with the usual parameter count replaced by $p_\text{eff}$, meaning a sparse neural network which robustly interpolates noisy data requires a heavily data-dependent mask. We posit that pruning during and after training outputs masks with higher mutual information than those produced by pruning at initialization. Thus two networks may have the same sparsities, but differ in effective parameter count based on how they were trained. This suggests that pruning near initialization may be infeasible and explains why lottery tickets exist, but cannot be found fast (i.e. without training the full network). Experiments on neural networks confirm that information gained during training may indeed affect model capacity.
Grokking as the Transition from Lazy to Rich Training Dynamics
Oct 09, 2023



We propose that the grokking phenomenon, where the train loss of a neural network decreases much earlier than its test loss, can arise due to a neural network transitioning from lazy training dynamics to a rich, feature learning regime. To illustrate this mechanism, we study the simple setting of vanilla gradient descent on a polynomial regression problem with a two layer neural network which exhibits grokking without regularization in a way that cannot be explained by existing theories. We identify sufficient statistics for the test loss of such a network, and tracking these over training reveals that grokking arises in this setting when the network first attempts to fit a kernel regression solution with its initial features, followed by late-time feature learning where a generalizing solution is identified after train loss is already low. We find that the key determinants of grokking are the rate of feature learning -- which can be controlled precisely by parameters that scale the network output -- and the alignment of the initial features with the target function $y(x)$. We argue this delayed generalization arises when (1) the top eigenvectors of the initial neural tangent kernel and the task labels $y(x)$ are misaligned, but (2) the dataset size is large enough so that it is possible for the network to generalize eventually, but not so large that train loss perfectly tracks test loss at all epochs, and (3) the network begins training in the lazy regime so does not learn features immediately. We conclude with evidence that this transition from lazy (linear model) to rich training (feature learning) can control grokking in more general settings, like on MNIST, one-layer Transformers, and student-teacher networks.
Human or Machine? Turing Tests for Vision and Language
Nov 23, 2022As AI algorithms increasingly participate in daily activities that used to be the sole province of humans, we are inevitably called upon to consider how much machines are really like us. To address this question, we turn to the Turing test and systematically benchmark current AIs in their abilities to imitate humans. We establish a methodology to evaluate humans versus machines in Turing-like tests and systematically evaluate a representative set of selected domains, parameters, and variables. The experiments involved testing 769 human agents, 24 state-of-the-art AI agents, 896 human judges, and 8 AI judges, in 21,570 Turing tests across 6 tasks encompassing vision and language modalities. Surprisingly, the results reveal that current AIs are not far from being able to impersonate human judges across different ages, genders, and educational levels in complex visual and language challenges. In contrast, simple AI judges outperform human judges in distinguishing human answers versus machine answers. The curated large-scale Turing test datasets introduced here and their evaluation metrics provide valuable insights to assess whether an agent is human or not. The proposed formulation to benchmark human imitation ability in current AIs paves a way for the research community to expand Turing tests to other research areas and conditions. All of source code and data are publicly available at https://tinyurl.com/8x8nha7p