 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Free Prune: Information-Theoretic Barriers to Pruning at Initialization
Paper and Code
Feb 02, 2024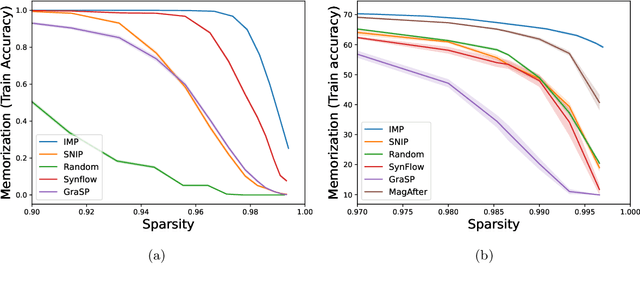
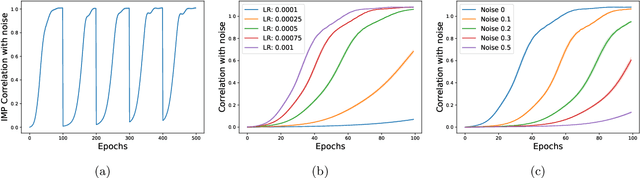
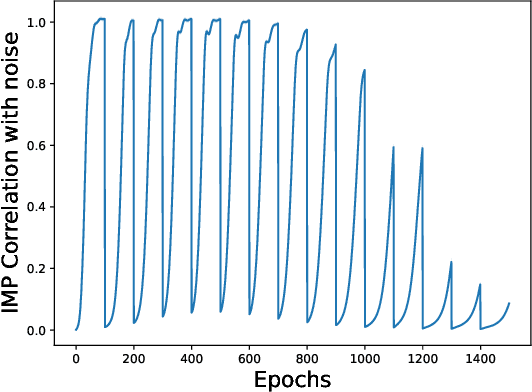
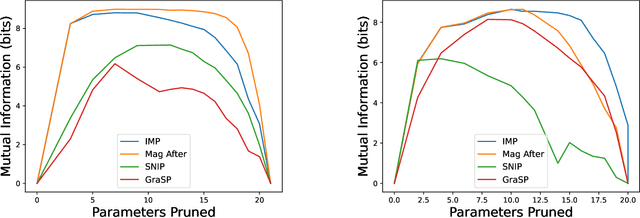
The existence of "lottery tickets" arXiv:1803.03635 at or near initialization raises the tantalizing question of whether large models are necessary in deep learning, or whether sparse networks can be quickly identified and trained without ever training the dense models that contain them. However, efforts to find these sparse subnetworks without training the dense model ("pruning at initialization") have been broadly unsuccessful arXiv:2009.08576. We put forward a theoretical explanation for this, based on the model's effective parameter count, $p_\text{eff}$, given by the sum of the number of non-zero weights in the final network and the mutual information between the sparsity mask and the data. We show the Law of Robustness of arXiv:2105.12806 extends to sparse networks with the usual parameter count replaced by $p_\text{eff}$, meaning a sparse neural network which robustly interpolates noisy data requires a heavily data-dependent mask. We posit that pruning during and after training outputs masks with higher mutual information than those produced by pruning at initialization. Thus two networks may have the same sparsities, but differ in effective parameter count based on how they were trained. This suggests that pruning near initialization may be infeasible and explains why lottery tickets exist, but cannot be found fast (i.e. without training the full network). Experiments on neural networks confirm that information gained during training may indeed affect model capacity.