 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Learning-Curve Monotonicity for Maximum Likelihood Estimators
Dec 11, 2025The property of learning-curve monotonicity, highlighted in a recent series of work by Loog, Mey and Viering, describes algorithms which only improve in average performance given more data, for any underlying data distribution within a given family. We establish the first nontrivial monotonicity guarantees for the maximum likelihood estimator in a variety of well-specified parametric settings. For sequential prediction with log loss, we show monotonicity (in fact complete monotonicity) of the forward KL divergence for Gaussian vectors with unknown covariance and either known or unknown mean, as well as for Gamma variables with unknown scale parameter. The Gaussian setting was explicitly highlighted as open in the aforementioned works, even in dimension 1. Finally we observe that for reverse KL divergence, a folklore trick yields monotonicity for very general exponential families. All results in this paper were derived by variants of GPT-5.2 Pro. Humans did not provide any proof strategies or intermediate arguments, but only prompted the model to continue developing additional results, and verified and transcribed its proofs.
Nonparametric MLE for Gaussian Location Mixtures: Certified Computation and Generic Behavior
Mar 26, 2025We study the nonparametric maximum likelihood estimator $\widehat{\pi}$ for Gaussian location mixtures in one dimension. It has been known since (Lindsay, 1983) that given an $n$-point dataset, this estimator always returns a mixture with at most $n$ components, and more recently (Wu-Polyanskiy, 2020) gave a sharp $O(\log n)$ bound for subgaussian data. In this work we study computational aspects of $\widehat{\pi}$. We provide an algorithm which for small enough $\varepsilon>0$ computes an $\varepsilon$-approximation of $\widehat\pi$ in Wasserstein distance in time $K+Cnk^2\log\log(1/\varepsilon)$. Here $K$ is data-dependent but independent of $\varepsilon$, while $C$ is an absolute constant and $k=|supp(\widehat{\pi})|\leq n$ is the number of atoms in $\widehat\pi$. We also certifiably compute the exact value of $|supp(\widehat\pi)|$ in finite time. These guarantees hold almost surely whenever the dataset $(x_1,\dots,x_n)\in [-cn^{1/4},cn^{1/4}]$ consists of independent points from a probability distribution with a density (relative to Lebesgue measure). We also show the distribution of $\widehat\pi$ conditioned to be $k$-atomic admits a density on the associated $2k-1$ dimensional parameter space for all $k\leq \sqrt{n}/3$, and almost sure locally linear convergence of the EM algorithm. One key tool is a classical Fourier analytic estimate for non-degenerate curves.
No Free Prune: Information-Theoretic Barriers to Pruning at Initialization
Feb 02, 2024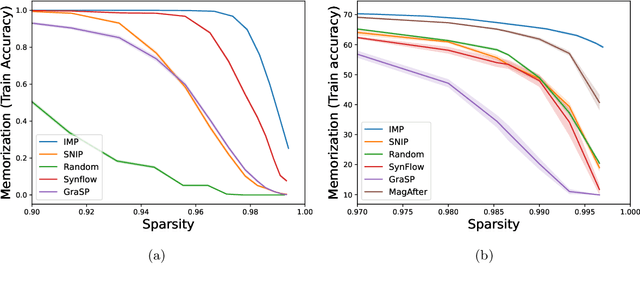
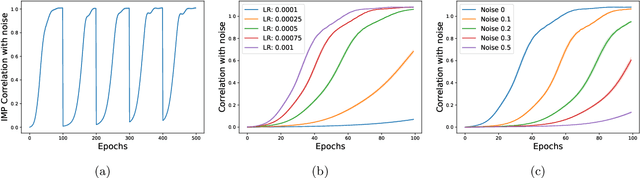
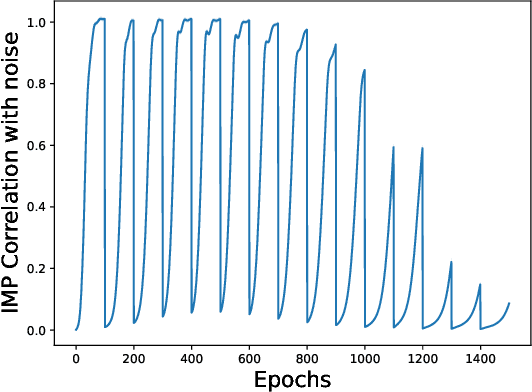
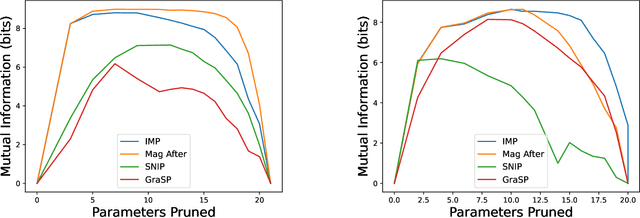
The existence of "lottery tickets" arXiv:1803.03635 at or near initialization raises the tantalizing question of whether large models are necessary in deep learning, or whether sparse networks can be quickly identified and trained without ever training the dense models that contain them. However, efforts to find these sparse subnetworks without training the dense model ("pruning at initialization") have been broadly unsuccessful arXiv:2009.08576. We put forward a theoretical explanation for this, based on the model's effective parameter count, $p_\text{eff}$, given by the sum of the number of non-zero weights in the final network and the mutual information between the sparsity mask and the data. We show the Law of Robustness of arXiv:2105.12806 extends to sparse networks with the usual parameter count replaced by $p_\text{eff}$, meaning a sparse neural network which robustly interpolates noisy data requires a heavily data-dependent mask. We posit that pruning during and after training outputs masks with higher mutual information than those produced by pruning at initialization. Thus two networks may have the same sparsities, but differ in effective parameter count based on how they were trained. This suggests that pruning near initialization may be infeasible and explains why lottery tickets exist, but cannot be found fast (i.e. without training the full network). Experiments on neural networks confirm that information gained during training may indeed affect model capacity.
Asymptotically Optimal Pure Exploration for Infinite-Armed Bandits
Jun 03, 2023We study pure exploration with infinitely many bandit arms generated i.i.d. from an unknown distribution. Our goal is to efficiently select a single high quality arm whose average reward is, with probability $1-\delta$, within $\varepsilon$ of being among the top $\eta$-fraction of arms; this is a natural adaptation of the classical PAC guarantee for infinite action sets. We consider both the fixed confidence and fixed budget settings, aiming respectively for minimal expected and fixed sample complexity. For fixed confidence, we give an algorithm with expected sample complexity $O\left(\frac{\log (1/\eta)\log (1/\delta)}{\eta\varepsilon^2}\right)$. This is optimal except for the $\log (1/\eta)$ factor, and the $\delta$-dependence closes a quadratic gap in the literature. For fixed budget, we show the asymptotically optimal sample complexity as $\delta\to 0$ is $c^{-1}\log(1/\delta)\big(\log\log(1/\delta)\big)^2$ to leading order. Equivalently, the optimal failure probability given exactly $N$ samples decays as $\exp\big(-cN/\log^2 N\big)$, up to a factor $1\pm o_N(1)$ inside the exponent. The constant $c$ depends explicitly on the problem parameters (including the unknown arm distribution) through a certain Fisher information distance. Even the strictly super-linear dependence on $\log(1/\delta)$ was not known and resolves a question of Grossman and Moshkovitz (FOCS 2016, SIAM Journal on Computing 2020).
Incentivizing Exploration with Linear Contexts and Combinatorial Actions
Jun 03, 2023We advance the study of incentivized bandit exploration, in which arm choices are viewed as recommendations and are required to be Bayesian incentive compatible. Recent work has shown under certain independence assumptions that after collecting enough initial samples, the popular Thompson sampling algorithm becomes incentive compatible. We give an analog of this result for linear bandits, where the independence of the prior is replaced by a natural convexity condition. This opens up the possibility of efficient and regret-optimal incentivized exploration in high-dimensional action spaces. In the semibandit model, we also improve the sample complexity for the pre-Thompson sampling phase of initial data collection.
On Size-Independent Sample Complexity of ReLU Networks
Jun 03, 2023We study the sample complexity of learning ReLU neural networks from the point of view of generalization. Given norm constraints on the weight matrices, a common approach is to estimate the Rademacher complexity of the associated function class. Previously Golowich-Rakhlin-Shamir (2020) obtained a bound independent of the network size (scaling with a product of Frobenius norms) except for a factor of the square-root depth. We give a refinement which often has no explicit depth-dependence at all.
Tight Bounds for State Tomography with Incoherent Measurements
Jun 10, 2022We consider the classic question of state tomography: given copies of an unknown quantum state $\rho\in\mathbb{C}^{d\times d}$, output $\widehat{\rho}$ for which $\|\rho - \widehat{\rho}\|_{\mathsf{tr}} \le \varepsilon$. When one is allowed to make coherent measurements entangled across all copies, $\Theta(d^2/\varepsilon^2)$ copies are necessary and sufficient [Haah et al. '17, O'Donnell-Wright '16]. Unfortunately, the protocols achieving this rate incur large quantum memory overheads that preclude implementation on current or near-term devices. On the other hand, the best known protocol using incoherent (single-copy) measurements uses $O(d^3/\varepsilon^2)$ copies [Kueng-Rauhut-Terstiege '17], and multiple papers have posed it as an open question to understand whether or not this rate is tight. In this work, we fully resolve this question, by showing that any protocol using incoherent measurements, even if they are chosen adaptively, requires $\Omega(d^3/\varepsilon^2)$ copies, matching the upper bound of [Kueng-Rauhut-Terstiege '17]. We do so by a new proof technique which directly bounds the "tilt" of the posterior distribution after measurements, which yields a surprisingly short proof of our lower bound, and which we believe may be of independent interest.
The Pareto Frontier of Instance-Dependent Guarantees in Multi-Player Multi-Armed Bandits with no Communication
Feb 19, 2022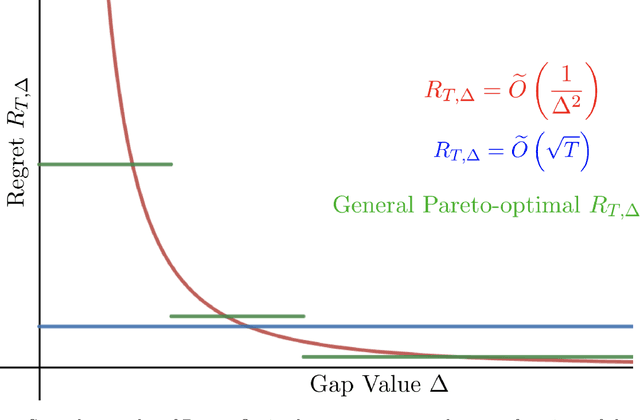
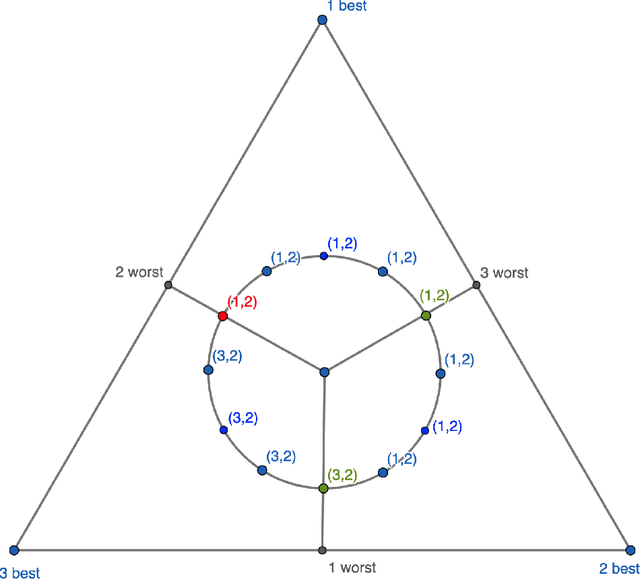
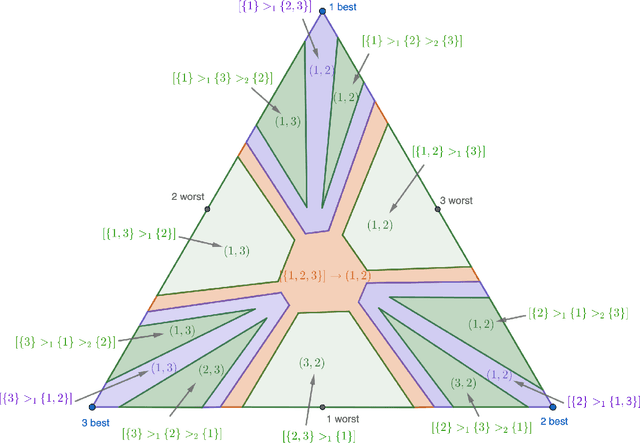
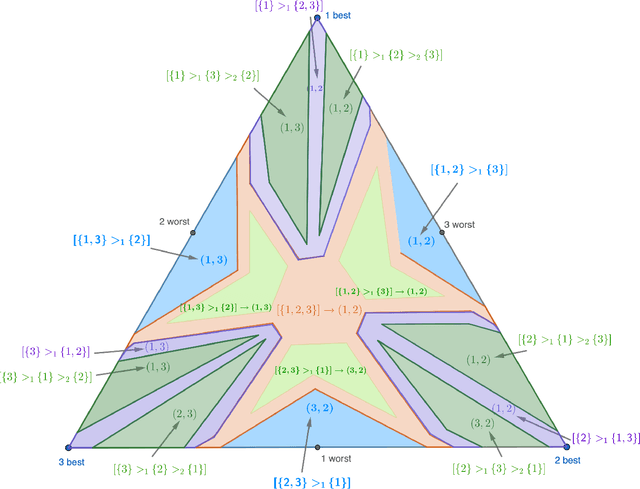
We study the stochastic multi-player multi-armed bandit problem. In this problem, $m$ players cooperate to maximize their total reward from $K > m$ arms. However the players cannot communicate and are penalized (e.g. receive no reward) if they pull the same arm at the same time. We ask whether it is possible to obtain optimal instance-dependent regret $\tilde{O}(1/\Delta)$ where $\Delta$ is the gap between the $m$-th and $m+1$-st best arms. Such guarantees were recently achieved in a model allowing the players to implicitly communicate through intentional collisions. We show that with no communication at all, such guarantees are, surprisingly, not achievable. In fact, obtaining the optimal $\tilde{O}(1/\Delta)$ regret for some regimes of $\Delta$ necessarily implies strictly sub-optimal regret in other regimes. Our main result is a complete characterization of the Pareto optimal instance-dependent trade-offs that are possible with no communication. Our algorithm generalizes that of Bubeck, Budzinski, and the second author and enjoys the same strong no-collision property, while our lower bound is based on a topological obstruction and holds even under full information.
Iterative Feature Matching: Toward Provable Domain Generalization with Logarithmic Environments
Jun 18, 2021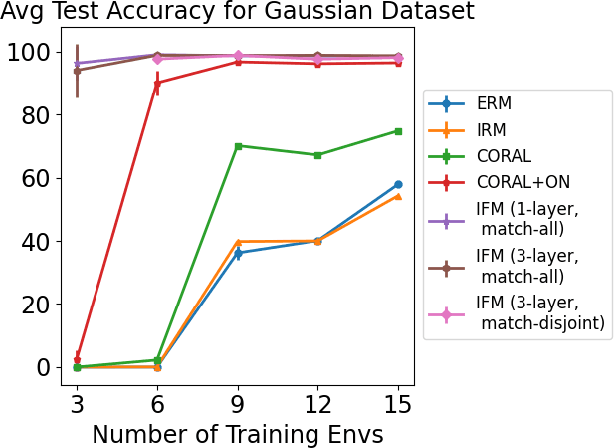

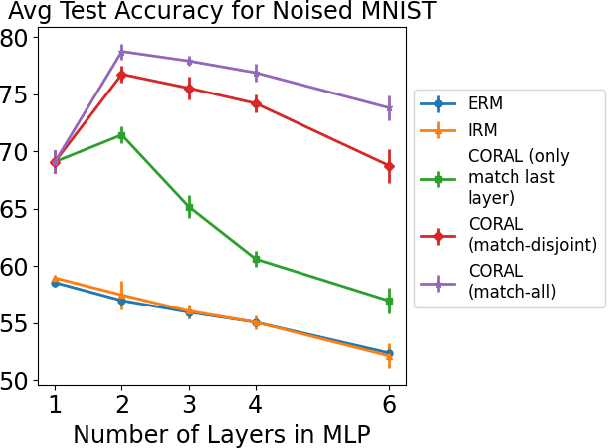
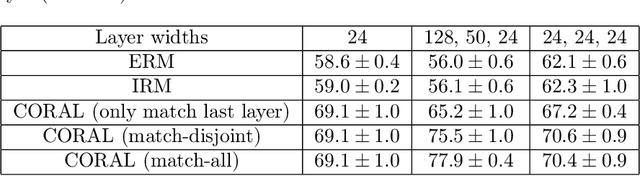
Domain generalization aims at performing well on unseen test environments with data from a limited number of training environments. Despite a proliferation of proposal algorithms for this task, assessing their performance, both theoretically and empirically is still very challenging. Moreover, recent approaches such as Invariant Risk Minimization (IRM) require a prohibitively large number of training environments - linear in the dimension of the spurious feature space $d_s$ - even on simple data models like the one proposed by [Rosenfeld et al., 2021]. Under a variant of this model, we show that both ERM and IRM cannot generalize with $o(d_s)$ environments. We then present a new algorithm based on performing iterative feature matching that is guaranteed with high probability to yield a predictor that generalizes after seeing only $O(\log{d_s})$ environments.
A Universal Law of Robustness via Isoperimetry
Jun 07, 2021Classically, data interpolation with a parametrized model class is possible as long as the number of parameters is larger than the number of equations to be satisfied. A puzzling phenomenon in deep learning is that models are trained with many more parameters than what this classical theory would suggest. We propose a theoretical explanation for this phenomenon. We prove that for a broad class of data distributions and model classes, overparametrization is necessary if one wants to interpolate the data smoothly. Namely we show that smooth interpolation requires $d$ times more parameters than mere interpolation, where $d$ is the ambient data dimension. We prove this universal law of robustness for any smoothly parametrized function class with polynomial size weights, and any covariate distribution verifying isoperimetry. In the case of two-layers neural networks and Gaussian covariates, this law was conjectured in prior work by Bubeck, Li and Nagaraj. We also give an interpretation of our result as an improved generalization bound for model classes consisting of smooth functions.