 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStealthy Multi-Task Adversarial Attacks
Nov 26, 2024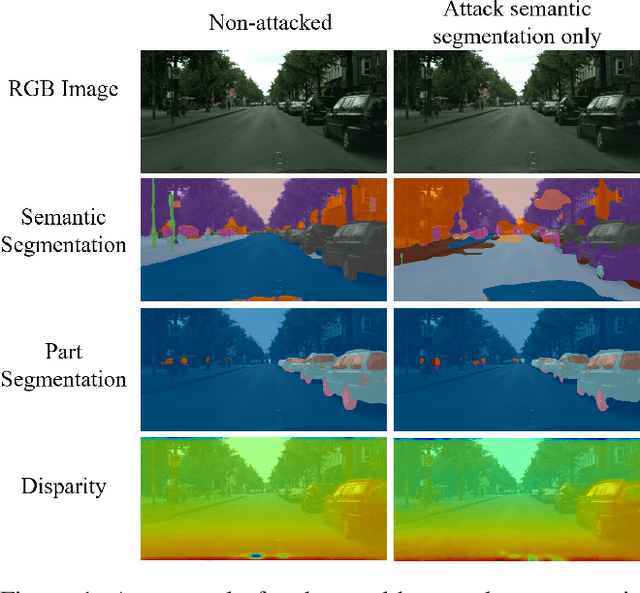
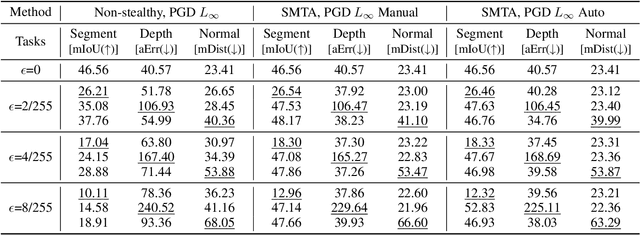
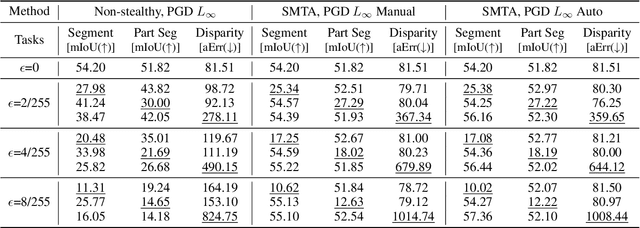
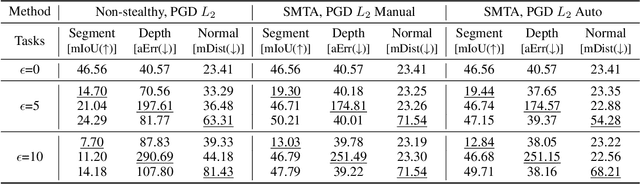
Deep Neural Networks exhibit inherent vulnerabilities to adversarial attacks, which can significantly compromise their outputs and reliability. While existing research primarily focuses on attacking single-task scenarios or indiscriminately targeting all tasks in multi-task environments, we investigate selectively targeting one task while preserving performance in others within a multi-task framework. This approach is motivated by varying security priorities among tasks in real-world applications, such as autonomous driving, where misinterpreting critical objects (e.g., signs, traffic lights) poses a greater security risk than minor depth miscalculations. Consequently, attackers may hope to target security-sensitive tasks while avoiding non-critical tasks from being compromised, thus evading being detected before compromising crucial functions. In this paper, we propose a method for the stealthy multi-task attack framework that utilizes multiple algorithms to inject imperceptible noise into the input. This novel method demonstrates remarkable efficacy in compromising the target task while simultaneously maintaining or even enhancing performance across non-targeted tasks - a criterion hitherto unexplored in the field. Additionally, we introduce an automated approach for searching the weighting factors in the loss function, further enhancing attack efficiency. Experimental results validate our framework's ability to successfully attack the target task while preserving the performance of non-targeted tasks. The automated loss function weight searching method demonstrates comparable efficacy to manual tuning, establishing a state-of-the-art multi-task attack framework.
Human or Machine? Turing Tests for Vision and Language
Nov 23, 2022As AI algorithms increasingly participate in daily activities that used to be the sole province of humans, we are inevitably called upon to consider how much machines are really like us. To address this question, we turn to the Turing test and systematically benchmark current AIs in their abilities to imitate humans. We establish a methodology to evaluate humans versus machines in Turing-like tests and systematically evaluate a representative set of selected domains, parameters, and variables. The experiments involved testing 769 human agents, 24 state-of-the-art AI agents, 896 human judges, and 8 AI judges, in 21,570 Turing tests across 6 tasks encompassing vision and language modalities. Surprisingly, the results reveal that current AIs are not far from being able to impersonate human judges across different ages, genders, and educational levels in complex visual and language challenges. In contrast, simple AI judges outperform human judges in distinguishing human answers versus machine answers. The curated large-scale Turing test datasets introduced here and their evaluation metrics provide valuable insights to assess whether an agent is human or not. The proposed formulation to benchmark human imitation ability in current AIs paves a way for the research community to expand Turing tests to other research areas and conditions. All of source code and data are publicly available at https://tinyurl.com/8x8nha7p
Improving Graph Representation Learning by Contrastive Regularization
Jan 27, 2021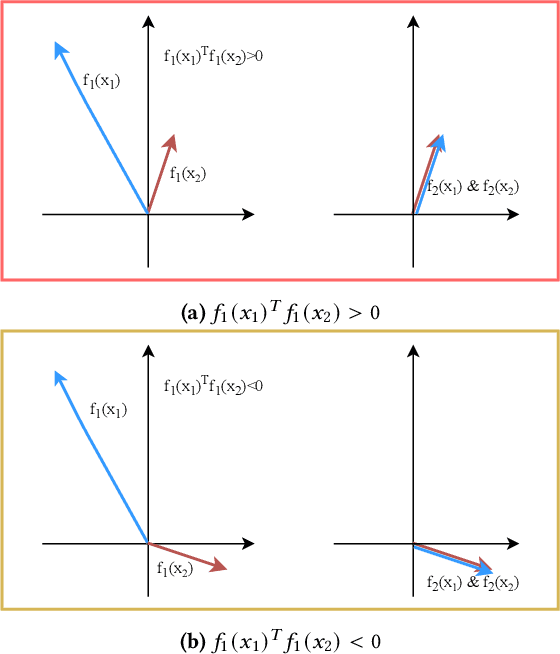
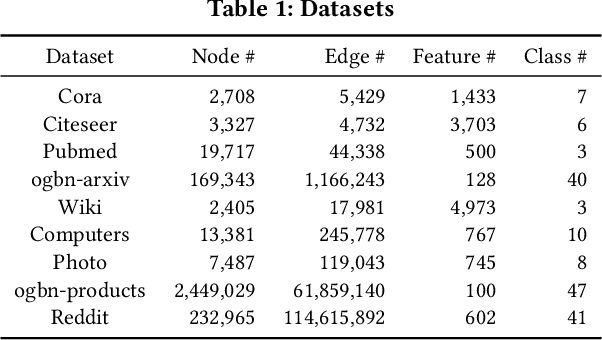
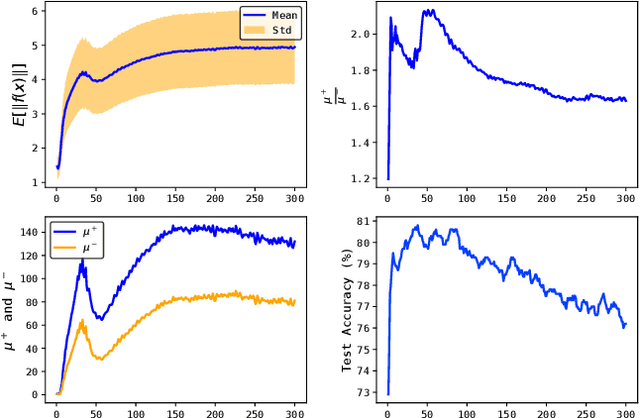
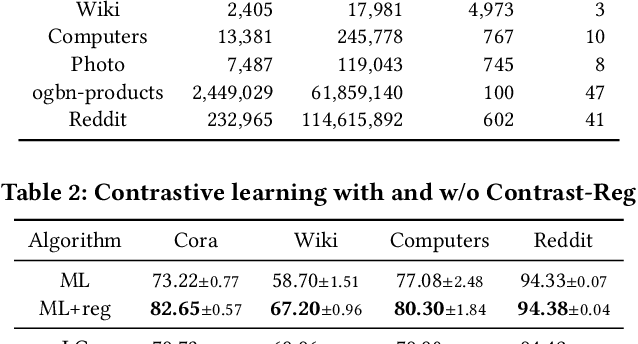
Graph representation learning is an important task with applications in various areas such as online social networks, e-commerce networks, WWW, and semantic webs. For unsupervised graph representation learning, many algorithms such as Node2Vec and Graph-SAGE make use of "negative sampling" and/or noise contrastive estimation loss. This bears similar ideas to contrastive learning, which "contrasts" the node representation similarities of semantically similar (positive) pairs against those of negative pairs. However, despite the success of contrastive learning, we found that directly applying this technique to graph representation learning models (e.g., graph convolutional networks) does not always work. We theoretically analyze the generalization performance and propose a light-weight regularization term that avoids the high scales of node representations' norms and the high variance among them to improve the generalization performance. Our experimental results further validate that this regularization term significantly improves the representation quality across different node similarity definitions and outperforms the state-of-the-art methods.