 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Perspective on Adversarial Membership Manipulation in Vision Models
Apr 03, 2026Membership inference attacks (MIAs) aim to determine whether a specific data point was part of a model's training set, serving as effective tools for evaluating privacy leakage of vision models. However, existing MIAs implicitly assume honest query inputs, and their adversarial robustness remains unexplored. We show that MIAs for vision models expose a previously overlooked adversarial surface: adversarial membership manipulation, where imperceptible perturbations can reliably push non-member images into the "member" region of state-of-the-art MIAs. In this paper, we provide the first unified perspective on this phenomenon by analyzing its mechanism and implications. We begin by demonstrating that adversarial membership fabrication is consistently effective across diverse architectures and datasets. We then reveal a distinctive geometric signature - a characteristic gradient-norm collapse trajectory - that reliably separates fabricated from true members despite their nearly identical semantic representations. Building on this insight, we introduce a principled detection strategy grounded in gradient-geometry signals and develop a robust inference framework that substantially mitigates adversarial manipulation. Extensive experiments show that fabrication is broadly effective, while our detection and robust inference strategies significantly enhance resilience. This work establishes the first comprehensive framework for adversarial membership manipulation in vision models.
CausalEvolve: Towards Open-Ended Discovery with Causal Scratchpad
Mar 15, 2026Evolve-based agent such as AlphaEvolve is one of the notable successes in using Large Language Models (LLMs) to build AI Scientists. These agents tackle open-ended scientific problems by iteratively improving and evolving programs, leveraging the prior knowledge and reasoning capabilities of LLMs. Despite the success, existing evolve-based agents lack targeted guidance for evolution and effective mechanisms for organizing and utilizing knowledge acquired from past evolutionary experience. Consequently, they suffer from decreasing evolution efficiency and exhibit oscillatory behavior when approaching known performance boundaries. To mitigate the gap, we develop CausalEvolve, equipped with a causal scratchpad that leverages LLMs to identify and reason about guiding factors for evolution. At the beginning, CausalEvolve first identifies outcome-level factors that offer complementary inspirations in improving the target objective. During the evolution, CausalEvolve also inspects surprise patterns during the evolution and abductive reasoning to hypothesize new factors, which in turn offer novel directions. Through comprehensive experiments, we show that CausalEvolve effectively improves the evolutionary efficiency and discovers better solutions in 4 challenging open-ended scientific tasks.
On Information Self-Locking in Reinforcement Learning for Active Reasoning of LLM agents
Mar 12, 2026Reinforcement learning (RL) with outcome-based rewards has achieved significant success in training large language model (LLM) agents for complex reasoning tasks. However, in active reasoning where agents need to strategically ask questions to acquire task-relevant information, we find that LLM agents trained with RL often suffer from information self-locking: the agent ceases to ask informative questions and struggles to internalize already-obtained information. To understand the phenomenon, we decompose active reasoning into two core capabilities: Action Selection (AS), which determines the observation stream through queries, and Belief Tracking (BT), which updates the agent's belief based on collected evidence. We show that deficient AS and BT capabilities will limit the information exploration during RL training. Furthermore, insufficient exploration in turn hinders the improvement of AS and BT, creating a feedback loop that locks the agent in a low-information regime. To resolve the issue, we propose a simple yet effective approach that reallocates the learning signal by injecting easy- to-obtain directional critiques to help the agent escape self-locking. Extensive experiments with 7 datasets show that our approach significantly mitigates the information self-locking, bringing up to 60% improvements.
ParamMem: Augmenting Language Agents with Parametric Reflective Memory
Feb 26, 2026Self-reflection enables language agents to iteratively refine solutions, yet often produces repetitive outputs that limit reasoning performance. Recent studies have attempted to address this limitation through various approaches, among which increasing reflective diversity has shown promise. Our empirical analysis reveals a strong positive correlation between reflective diversity and task success, further motivating the need for diverse reflection signals. We introduce ParamMem, a parametric memory module that encodes cross-sample reflection patterns into model parameters, enabling diverse reflection generation through temperature-controlled sampling. Building on this module, we propose ParamAgent, a reflection-based agent framework that integrates parametric memory with episodic and cross-sample memory. Extensive experiments on code generation, mathematical reasoning, and multi-hop question answering demonstrate consistent improvements over state-of-the-art baselines. Further analysis reveals that ParamMem is sample-efficient, enables weak-to-strong transfer across model scales, and supports self-improvement without reliance on stronger external model, highlighting the potential of ParamMem as an effective component for enhancing language agents.
TDGNet: Hallucination Detection in Diffusion Language Models via Temporal Dynamic Graphs
Feb 08, 2026Diffusion language models (D-LLMs) offer parallel denoising and bidirectional context, but hallucination detection for D-LLMs remains underexplored. Prior detectors developed for auto-regressive LLMs typically rely on single-pass cues and do not directly transfer to diffusion generation, where factuality evidence is distributed across the denoising trajectory and may appear, drift, or be self-corrected over time. We introduce TDGNet, a temporal dynamic graph framework that formulates hallucination detection as learning over evolving token-level attention graphs. At each denoising step, we sparsify the attention graph and update per-token memories via message passing, then apply temporal attention to aggregate trajectory-wide evidence for final prediction. Experiments on LLaDA-8B and Dream-7B across QA benchmarks show consistent AUROC improvements over output-based, latent-based, and static-graph baselines, with single-pass inference and modest overhead. These results highlight the importance of temporal reasoning on attention graphs for robust hallucination detection in diffusion language models.
MESH -- Understanding Videos Like Human: Measuring Hallucinations in Large Video Models
Sep 10, 2025Large Video Models (LVMs) build on the semantic capabilities of Large Language Models (LLMs) and vision modules by integrating temporal information to better understand dynamic video content. Despite their progress, LVMs are prone to hallucinations-producing inaccurate or irrelevant descriptions. Current benchmarks for video hallucination depend heavily on manual categorization of video content, neglecting the perception-based processes through which humans naturally interpret videos. We introduce MESH, a benchmark designed to evaluate hallucinations in LVMs systematically. MESH uses a Question-Answering framework with binary and multi-choice formats incorporating target and trap instances. It follows a bottom-up approach, evaluating basic objects, coarse-to-fine subject features, and subject-action pairs, aligning with human video understanding. We demonstrate that MESH offers an effective and comprehensive approach for identifying hallucinations in videos. Our evaluations show that while LVMs excel at recognizing basic objects and features, their susceptibility to hallucinations increases markedly when handling fine details or aligning multiple actions involving various subjects in longer videos.
Learning Causality for Modern Machine Learning
Jun 13, 2025In the past decades, machine learning with Empirical Risk Minimization (ERM) has demonstrated great capability in learning and exploiting the statistical patterns from data, or even surpassing humans. Despite the success, ERM avoids the modeling of causality the way of understanding and handling changes, which is fundamental to human intelligence. When deploying models beyond the training environment, distribution shifts are everywhere. For example, an autopilot system often needs to deal with new weather conditions that have not been seen during training, An Al-aided drug discovery system needs to predict the biochemical properties of molecules with respect to new viruses such as COVID-19. It renders the problem of Out-of-Distribution (OOD) generalization challenging to conventional machine learning. In this thesis, we investigate how to incorporate and realize the causality for broader tasks in modern machine learning. In particular, we exploit the invariance implied by the principle of independent causal mechanisms (ICM), that is, the causal mechanisms generating the effects from causes do not inform or influence each other. Therefore, the conditional distribution between the target variable given its causes is invariant under distribution shifts. With the causal invariance principle, we first instantiate it to graphs -- a general data structure ubiquitous in many real-world industry and scientific applications, such as financial networks and molecules. Then, we shall see how learning the causality benefits many of the desirable properties of modern machine learning, in terms of (i) OOD generalization capability; (ii) interpretability; and (iii) robustness to adversarial attacks. Realizing the causality in machine learning, on the other hand, raises a dilemma for optimization in conventional machine learning, as it often contradicts the objective of ERM...
Pruning Spurious Subgraphs for Graph Out-of-Distribtuion Generalization
Jun 06, 2025Graph Neural Networks (GNNs) often encounter significant performance degradation under distribution shifts between training and test data, hindering their applicability in real-world scenarios. Recent studies have proposed various methods to address the out-of-distribution generalization challenge, with many methods in the graph domain focusing on directly identifying an invariant subgraph that is predictive of the target label. However, we argue that identifying the edges from the invariant subgraph directly is challenging and error-prone, especially when some spurious edges exhibit strong correlations with the targets. In this paper, we propose PrunE, the first pruning-based graph OOD method that eliminates spurious edges to improve OOD generalizability. By pruning spurious edges, \mine{} retains the invariant subgraph more comprehensively, which is critical for OOD generalization. Specifically, PrunE employs two regularization terms to prune spurious edges: 1) graph size constraint to exclude uninformative spurious edges, and 2) $\epsilon$-probability alignment to further suppress the occurrence of spurious edges. Through theoretical analysis and extensive experiments, we show that PrunE achieves superior OOD performance and outperforms previous state-of-the-art methods significantly. Codes are available at: \href{https://github.com/tianyao-aka/PrunE-GraphOOD}{https://github.com/tianyao-aka/PrunE-GraphOOD}.
Does Representation Intervention Really Identify Desired Concepts and Elicit Alignment?
May 24, 2025Representation intervention aims to locate and modify the representations that encode the underlying concepts in Large Language Models (LLMs) to elicit the aligned and expected behaviors. Despite the empirical success, it has never been examined whether one could locate the faithful concepts for intervention. In this work, we explore the question in safety alignment. If the interventions are faithful, the intervened LLMs should erase the harmful concepts and be robust to both in-distribution adversarial prompts and the out-of-distribution (OOD) jailbreaks. While it is feasible to erase harmful concepts without degrading the benign functionalities of LLMs in linear settings, we show that it is infeasible in the general non-linear setting. To tackle the issue, we propose Concept Concentration (COCA). Instead of identifying the faithful locations to intervene, COCA refractors the training data with an explicit reasoning process, which firstly identifies the potential unsafe concepts and then decides the responses. Essentially, COCA simplifies the decision boundary between harmful and benign representations, enabling more effective linear erasure. Extensive experiments with multiple representation intervention methods and model architectures demonstrate that COCA significantly reduces both in-distribution and OOD jailbreak success rates, and meanwhile maintaining strong performance on regular tasks such as math and code generation.
On the Thinking-Language Modeling Gap in Large Language Models
May 19, 2025
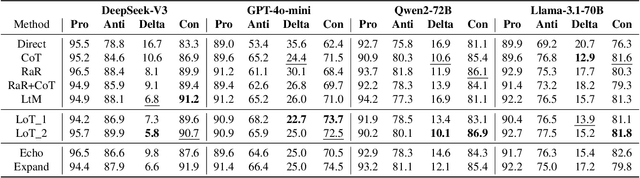

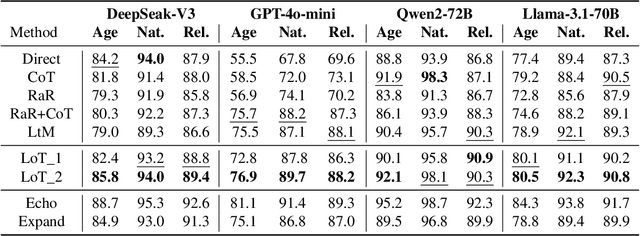
System 2 reasoning is one of the defining characteristics of intelligence, which requires slow and logical thinking. Human conducts System 2 reasoning via the language of thoughts that organizes the reasoning process as a causal sequence of mental language, or thoughts. Recently, it has been observed that System 2 reasoning can be elicited from Large Language Models (LLMs) pre-trained on large-scale natural languages. However, in this work, we show that there is a significant gap between the modeling of languages and thoughts. As language is primarily a tool for humans to share knowledge and thinking, modeling human language can easily absorb language biases into LLMs deviated from the chain of thoughts in minds. Furthermore, we show that the biases will mislead the eliciting of "thoughts" in LLMs to focus only on a biased part of the premise. To this end, we propose a new prompt technique termed Language-of-Thoughts (LoT) to demonstrate and alleviate this gap. Instead of directly eliciting the chain of thoughts from partial information, LoT instructs LLMs to adjust the order and token used for the expressions of all the relevant information. We show that the simple strategy significantly reduces the language modeling biases in LLMs and improves the performance of LLMs across a variety of reasoning tasks.