 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliciting Causal Abilities in Large Language Models for Reasoning Tasks
Dec 19, 2024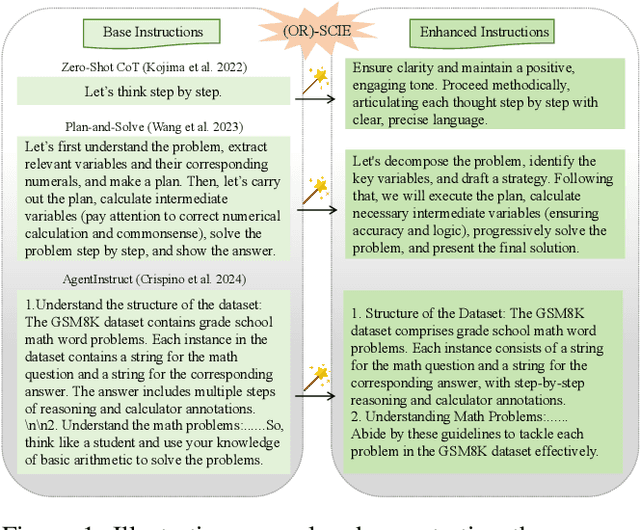
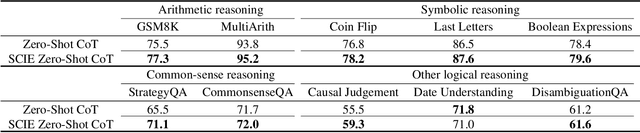
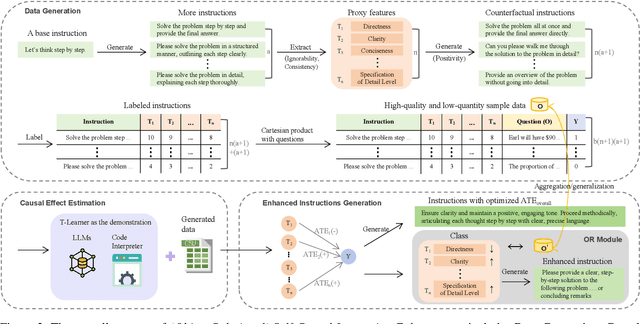

Prompt optimization automatically refines prompting expressions, unlocking the full potential of LLMs in downstream tasks. However, current prompt optimization methods are costly to train and lack sufficient interpretability. This paper proposes enhancing LLMs' reasoning performance by eliciting their causal inference ability from prompting instructions to correct answers. Specifically, we introduce the Self-Causal Instruction Enhancement (SCIE) method, which enables LLMs to generate high-quality, low-quantity observational data, then estimates the causal effect based on these data, and ultimately generates instructions with the optimized causal effect. In SCIE, the instructions are treated as the treatment, and textual features are used to process natural language, establishing causal relationships through treatments between instructions and downstream tasks. Additionally, we propose applying Object-Relational (OR) principles, where the uncovered causal relationships are treated as the inheritable class across task objects, ensuring low-cost reusability. Extensive experiments demonstrate that our method effectively generates instructions that enhance reasoning performance with reduced training cost of prompts, leveraging interpretable textual features to provide actionable insights.
Enhance Multi-domain Sentiment Analysis of Review Texts through Prompting Strategies
Sep 05, 2023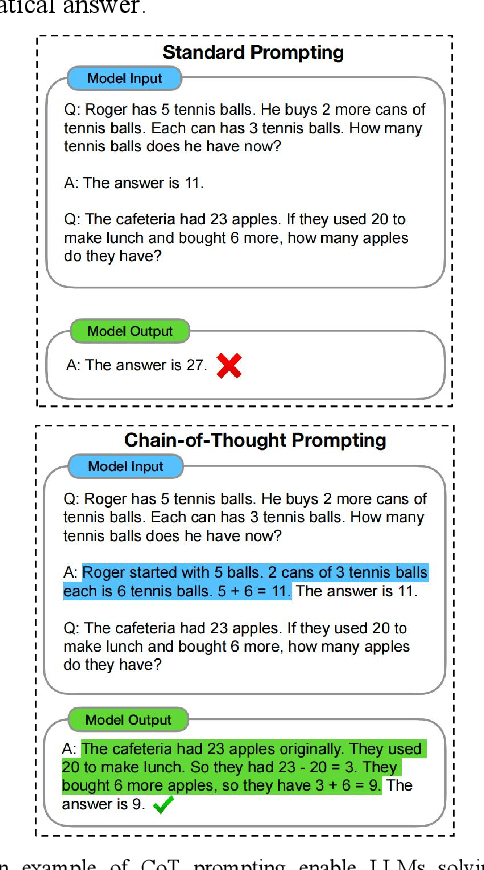
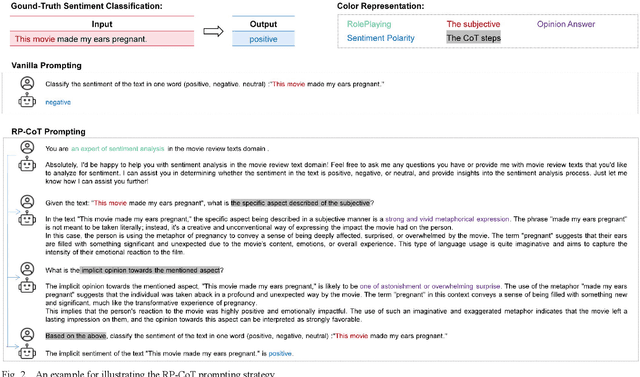
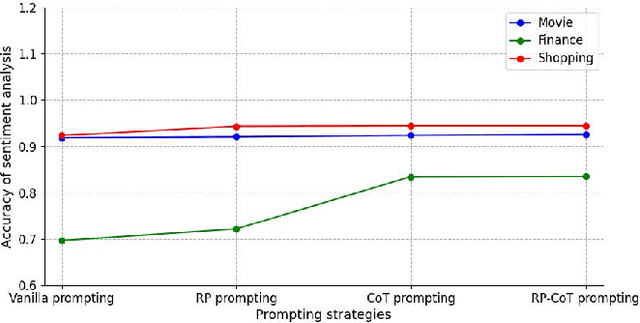
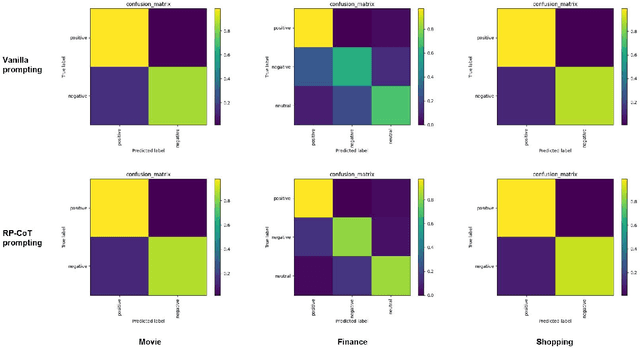
Large Language Models (LLMs) have made significant strides in both scientific research and practical applications. Existing studies have demonstrated the state-of-the-art (SOTA) performance of LLMs in various natural language processing tasks. However, the question of how to further enhance LLMs' performance in specific task using prompting strategies remains a pivotal concern. This paper explores the enhancement of LLMs' performance in sentiment analysis through the application of prompting strategies. We formulate the process of prompting for sentiment analysis tasks and introduce two novel strategies tailored for sentiment analysis: RolePlaying (RP) prompting and Chain-of-thought (CoT) prompting. Specifically, we also propose the RP-CoT prompting strategy which is a combination of RP prompting and CoT prompting. We conduct comparative experiments on three distinct domain datasets to evaluate the effectiveness of the proposed sentiment analysis strategies. The results demonstrate that the adoption of the proposed prompting strategies leads to a increasing enhancement in sentiment analysis accuracy. Further, the CoT prompting strategy exhibits a notable impact on implicit sentiment analysis, with the RP-CoT prompting strategy delivering the most superior performance among all strategies.