 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Efficient and Generalizable Graph Retriever for Knowledge-Graph Question Answering
Jun 11, 2025Large Language Models (LLMs) have shown strong inductive reasoning ability across various domains, but their reliability is hindered by the outdated knowledge and hallucinations. Retrieval-Augmented Generation mitigates these issues by grounding LLMs with external knowledge; however, most existing RAG pipelines rely on unstructured text, limiting interpretability and structured reasoning. Knowledge graphs, which represent facts as relational triples, offer a more structured and compact alternative. Recent studies have explored integrating knowledge graphs with LLMs for knowledge graph question answering (KGQA), with a significant proportion adopting the retrieve-then-reasoning paradigm. In this framework, graph-based retrievers have demonstrated strong empirical performance, yet they still face challenges in generalization ability. In this work, we propose RAPL, a novel framework for efficient and effective graph retrieval in KGQA. RAPL addresses these limitations through three aspects: (1) a two-stage labeling strategy that combines heuristic signals with parametric models to provide causally grounded supervision; (2) a model-agnostic graph transformation approach to capture both intra- and inter-triple interactions, thereby enhancing representational capacity; and (3) a path-based reasoning strategy that facilitates learning from the injected rational knowledge, and supports downstream reasoner through structured inputs. Empirically, RAPL outperforms state-of-the-art methods by $2.66\%-20.34\%$, and significantly reduces the performance gap between smaller and more powerful LLM-based reasoners, as well as the gap under cross-dataset settings, highlighting its superior retrieval capability and generalizability. Codes are available at: https://github.com/tianyao-aka/RAPL.
Pruning Spurious Subgraphs for Graph Out-of-Distribtuion Generalization
Jun 06, 2025Graph Neural Networks (GNNs) often encounter significant performance degradation under distribution shifts between training and test data, hindering their applicability in real-world scenarios. Recent studies have proposed various methods to address the out-of-distribution generalization challenge, with many methods in the graph domain focusing on directly identifying an invariant subgraph that is predictive of the target label. However, we argue that identifying the edges from the invariant subgraph directly is challenging and error-prone, especially when some spurious edges exhibit strong correlations with the targets. In this paper, we propose PrunE, the first pruning-based graph OOD method that eliminates spurious edges to improve OOD generalizability. By pruning spurious edges, \mine{} retains the invariant subgraph more comprehensively, which is critical for OOD generalization. Specifically, PrunE employs two regularization terms to prune spurious edges: 1) graph size constraint to exclude uninformative spurious edges, and 2) $\epsilon$-probability alignment to further suppress the occurrence of spurious edges. Through theoretical analysis and extensive experiments, we show that PrunE achieves superior OOD performance and outperforms previous state-of-the-art methods significantly. Codes are available at: \href{https://github.com/tianyao-aka/PrunE-GraphOOD}{https://github.com/tianyao-aka/PrunE-GraphOOD}.
Empowering Graph Invariance Learning with Deep Spurious Infomax
Jul 13, 2024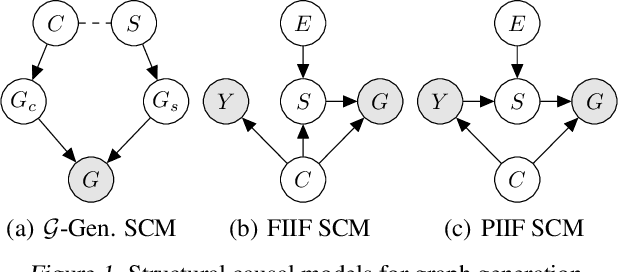
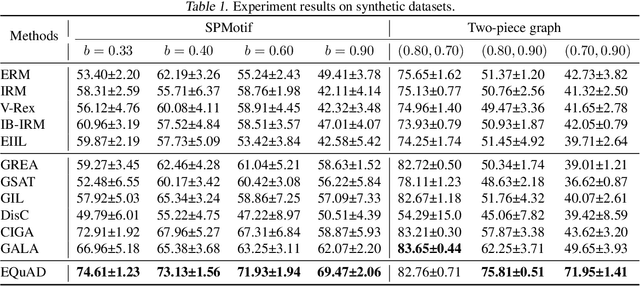
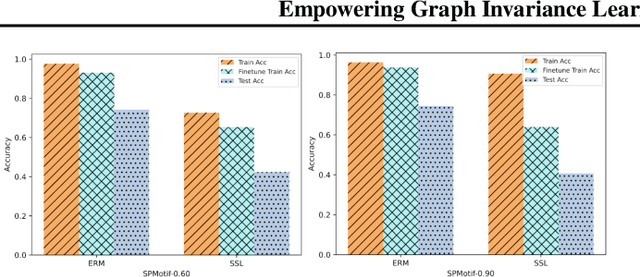
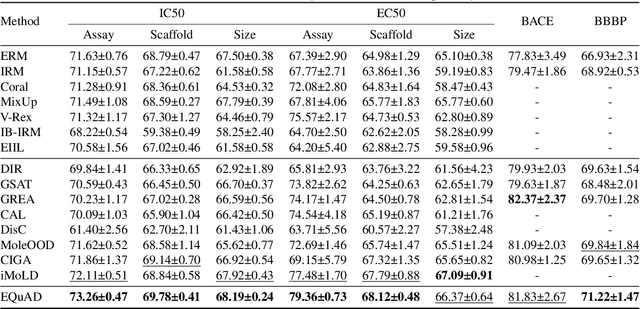
Recently, there has been a surge of interest in developing graph neural networks that utilize the invariance principle on graphs to generalize the out-of-distribution (OOD) data. Due to the limited knowledge about OOD data, existing approaches often pose assumptions about the correlation strengths of the underlying spurious features and the target labels. However, this prior is often unavailable and will change arbitrarily in the real-world scenarios, which may lead to severe failures of the existing graph invariance learning methods. To bridge this gap, we introduce a novel graph invariance learning paradigm, which induces a robust and general inductive bias. The paradigm is built upon the observation that the infomax principle encourages learning spurious features regardless of spurious correlation strengths. We further propose the EQuAD framework that realizes this learning paradigm and employs tailored learning objectives that provably elicit invariant features by disentangling them from the spurious features learned through infomax. Notably, EQuAD shows stable and enhanced performance across different degrees of bias in synthetic datasets and challenging real-world datasets up to $31.76\%$. Our code is available at \url{https://github.com/tianyao-aka/EQuAD}.
MuGSI: Distilling GNNs with Multi-Granularity Structural Information for Graph Classification
Jun 28, 2024



Recent works have introduced GNN-to-MLP knowledge distillation (KD) frameworks to combine both GNN's superior performance and MLP's fast inference speed. However, existing KD frameworks are primarily designed for node classification within single graphs, leaving their applicability to graph classification largely unexplored. Two main challenges arise when extending KD for node classification to graph classification: (1) The inherent sparsity of learning signals due to soft labels being generated at the graph level; (2) The limited expressiveness of student MLPs, especially in datasets with limited input feature spaces. To overcome these challenges, we introduce MuGSI, a novel KD framework that employs Multi-granularity Structural Information for graph classification. Specifically, we propose multi-granularity distillation loss in MuGSI to tackle the first challenge. This loss function is composed of three distinct components: graph-level distillation, subgraph-level distillation, and node-level distillation. Each component targets a specific granularity of the graph structure, ensuring a comprehensive transfer of structural knowledge from the teacher model to the student model. To tackle the second challenge, MuGSI proposes to incorporate a node feature augmentation component, thereby enhancing the expressiveness of the student MLPs and making them more capable learners. We perform extensive experiments across a variety of datasets and different teacher/student model architectures. The experiment results demonstrate the effectiveness, efficiency, and robustness of MuGSI. Codes are publicly available at: \textbf{\url{https://github.com/tianyao-aka/MuGSI}.}
Improving the Expressiveness of $K$-hop Message-Passing GNNs by Injecting Contextualized Substructure Information
Jun 27, 2024Graph neural networks (GNNs) have become the \textit{de facto} standard for representational learning in graphs, and have achieved state-of-the-art performance in many graph-related tasks; however, it has been shown that the expressive power of standard GNNs are equivalent maximally to 1-dimensional Weisfeiler-Lehman (1-WL) Test. Recently, there is a line of works aiming to enhance the expressive power of graph neural networks. One line of such works aim at developing $K$-hop message-passing GNNs where node representation is updated by aggregating information from not only direct neighbors but all neighbors within $K$-hop of the node. Another line of works leverages subgraph information to enhance the expressive power which is proven to be strictly more powerful than 1-WL test. In this work, we discuss the limitation of $K$-hop message-passing GNNs and propose \textit{substructure encoding function} to uplift the expressive power of any $K$-hop message-passing GNN. We further inject contextualized substructure information to enhance the expressiveness of $K$-hop message-passing GNNs. Our method is provably more powerful than previous works on $K$-hop graph neural networks and 1-WL subgraph GNNs, which is a specific type of subgraph based GNN models, and not less powerful than 3-WL. Empirically, our proposed method set new state-of-the-art performance or achieves comparable performance for a variety of datasets. Our code is available at \url{https://github.com/tianyao-aka/Expresive_K_hop_GNNs}.
Efficient LLM Jailbreak via Adaptive Dense-to-sparse Constrained Optimization
May 15, 2024
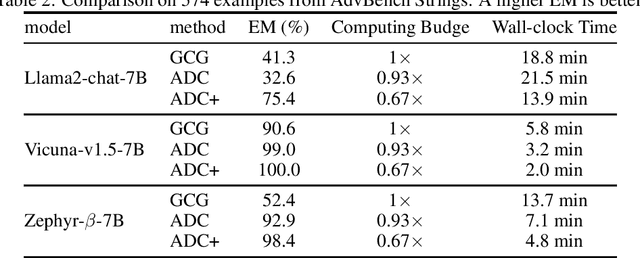


Recent research indicates that large language models (LLMs) are susceptible to jailbreaking attacks that can generate harmful content. This paper introduces a novel token-level attack method, Adaptive Dense-to-Sparse Constrained Optimization (ADC), which effectively jailbreaks several open-source LLMs. Our approach relaxes the discrete jailbreak optimization into a continuous optimization and progressively increases the sparsity of the optimizing vectors. Consequently, our method effectively bridges the gap between discrete and continuous space optimization. Experimental results demonstrate that our method is more effective and efficient than existing token-level methods. On Harmbench, our method achieves state of the art attack success rate on seven out of eight LLMs. Code will be made available. Trigger Warning: This paper contains model behavior that can be offensive in nature.