 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeServImage: An Image Generation and Editing Benchmark from Real-world Commercial Imaging Services
Apr 27, 2026Recent image generation and editing models demonstrate robust adherence to instructions and high visual quality on academic benchmarks. However, their performance on paid, real-world design projects remains uncertain. We introduce \textbf{ServImage}, a benchmark that explicitly correlates model outputs with economic value in commercial design projects. ServImage consists of (i) \textbf{\textit{ServImageBench}}: a dataset of 1.07k paid commercial design tasks and 2.05k designer deliverables totaling over \$295k, covering portrait, product, and digital content, along with 33k candidate images and 33k human annotations. (ii) \textbf{\textit{ServImageScore}}: an integrated scoring system that combines three quality dimensions: baseline requirements fulfilment, visual execution quality, and commercial necessity satisfaction. These three dimensions are designed to characterize the factors that drive human payment decisions and indicate whether an image is commercially acceptable. (iii) \textbf{\textit{ServImageModel}}: under this scoring system, we propose a payment prediction model trained on the human-annotated candidate images, achieving 82.00\% accuracy in predicting human payment decisions and producing calibrated payment probabilities. ServImage provides a comprehensive foundation for assessing the commercial viability of image generation models and offers a scalable resource for future research on economically grounded vision systems \href{https://github.com/FengxianJi/ServImage}{Github.}
CausalEvolve: Towards Open-Ended Discovery with Causal Scratchpad
Mar 15, 2026Evolve-based agent such as AlphaEvolve is one of the notable successes in using Large Language Models (LLMs) to build AI Scientists. These agents tackle open-ended scientific problems by iteratively improving and evolving programs, leveraging the prior knowledge and reasoning capabilities of LLMs. Despite the success, existing evolve-based agents lack targeted guidance for evolution and effective mechanisms for organizing and utilizing knowledge acquired from past evolutionary experience. Consequently, they suffer from decreasing evolution efficiency and exhibit oscillatory behavior when approaching known performance boundaries. To mitigate the gap, we develop CausalEvolve, equipped with a causal scratchpad that leverages LLMs to identify and reason about guiding factors for evolution. At the beginning, CausalEvolve first identifies outcome-level factors that offer complementary inspirations in improving the target objective. During the evolution, CausalEvolve also inspects surprise patterns during the evolution and abductive reasoning to hypothesize new factors, which in turn offer novel directions. Through comprehensive experiments, we show that CausalEvolve effectively improves the evolutionary efficiency and discovers better solutions in 4 challenging open-ended scientific tasks.
ManipLVM-R1: Reinforcement Learning for Reasoning in Embodied Manipulation with Large Vision-Language Models
May 22, 2025Large Vision-Language Models (LVLMs) have recently advanced robotic manipulation by leveraging vision for scene perception and language for instruction following. However, existing methods rely heavily on costly human-annotated training datasets, which limits their generalization and causes them to struggle in out-of-domain (OOD) scenarios, reducing real-world adaptability. To address these challenges, we propose ManipLVM-R1, a novel reinforcement learning framework that replaces traditional supervision with Reinforcement Learning using Verifiable Rewards (RLVR). By directly optimizing for task-aligned outcomes, our method enhances generalization and physical reasoning while removing the dependence on costly annotations. Specifically, we design two rule-based reward functions targeting key robotic manipulation subtasks: an Affordance Perception Reward to enhance localization of interaction regions, and a Trajectory Match Reward to ensure the physical plausibility of action paths. These rewards provide immediate feedback and impose spatial-logical constraints, encouraging the model to go beyond shallow pattern matching and instead learn deeper, more systematic reasoning about physical interactions.
Audio Jailbreak: An Open Comprehensive Benchmark for Jailbreaking Large Audio-Language Models
May 21, 2025



The rise of Large Audio Language Models (LAMs) brings both potential and risks, as their audio outputs may contain harmful or unethical content. However, current research lacks a systematic, quantitative evaluation of LAM safety especially against jailbreak attacks, which are challenging due to the temporal and semantic nature of speech. To bridge this gap, we introduce AJailBench, the first benchmark specifically designed to evaluate jailbreak vulnerabilities in LAMs. We begin by constructing AJailBench-Base, a dataset of 1,495 adversarial audio prompts spanning 10 policy-violating categories, converted from textual jailbreak attacks using realistic text to speech synthesis. Using this dataset, we evaluate several state-of-the-art LAMs and reveal that none exhibit consistent robustness across attacks. To further strengthen jailbreak testing and simulate more realistic attack conditions, we propose a method to generate dynamic adversarial variants. Our Audio Perturbation Toolkit (APT) applies targeted distortions across time, frequency, and amplitude domains. To preserve the original jailbreak intent, we enforce a semantic consistency constraint and employ Bayesian optimization to efficiently search for perturbations that are both subtle and highly effective. This results in AJailBench-APT, an extended dataset of optimized adversarial audio samples. Our findings demonstrate that even small, semantically preserved perturbations can significantly reduce the safety performance of leading LAMs, underscoring the need for more robust and semantically aware defense mechanisms.
Reflection-Window Decoding: Text Generation with Selective Refinement
Feb 05, 2025



The autoregressive decoding for text generation in large language models (LLMs), while widely used, is inherently suboptimal due to the lack of a built-in mechanism to perform refinement and/or correction of the generated content. In this paper, we consider optimality in terms of the joint probability over the generated response, when jointly considering all tokens at the same time. We theoretically characterize the potential deviation of the autoregressively generated response from its globally optimal counterpart that is of the same length. Our analysis suggests that we need to be cautious when noticeable uncertainty arises during text generation, which may signal the sub-optimality of the generation history. To address the pitfall of autoregressive decoding for text generation, we propose an approach that incorporates a sliding reflection window and a pausing criterion, such that refinement and generation can be carried out interchangeably as the decoding proceeds. Our selective refinement framework strikes a balance between efficiency and optimality, and our extensive experimental results demonstrate the effectiveness of our approach.
Empowering Graph Invariance Learning with Deep Spurious Infomax
Jul 13, 2024
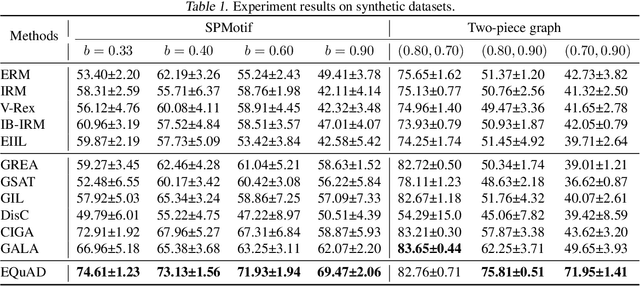
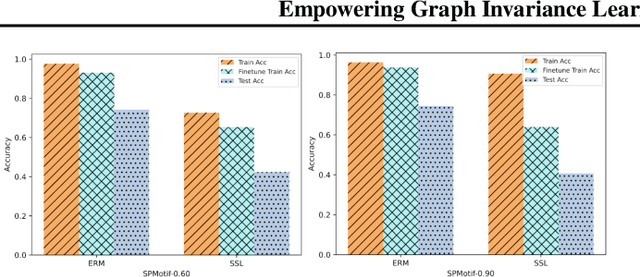
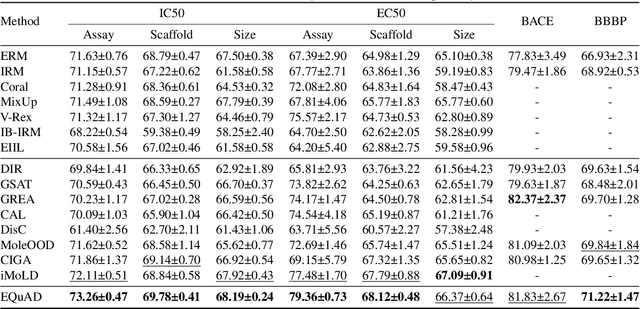
Recently, there has been a surge of interest in developing graph neural networks that utilize the invariance principle on graphs to generalize the out-of-distribution (OOD) data. Due to the limited knowledge about OOD data, existing approaches often pose assumptions about the correlation strengths of the underlying spurious features and the target labels. However, this prior is often unavailable and will change arbitrarily in the real-world scenarios, which may lead to severe failures of the existing graph invariance learning methods. To bridge this gap, we introduce a novel graph invariance learning paradigm, which induces a robust and general inductive bias. The paradigm is built upon the observation that the infomax principle encourages learning spurious features regardless of spurious correlation strengths. We further propose the EQuAD framework that realizes this learning paradigm and employs tailored learning objectives that provably elicit invariant features by disentangling them from the spurious features learned through infomax. Notably, EQuAD shows stable and enhanced performance across different degrees of bias in synthetic datasets and challenging real-world datasets up to $31.76\%$. Our code is available at \url{https://github.com/tianyao-aka/EQuAD}.
MMAC-Copilot: Multi-modal Agent Collaboration Operating System Copilot
Apr 28, 2024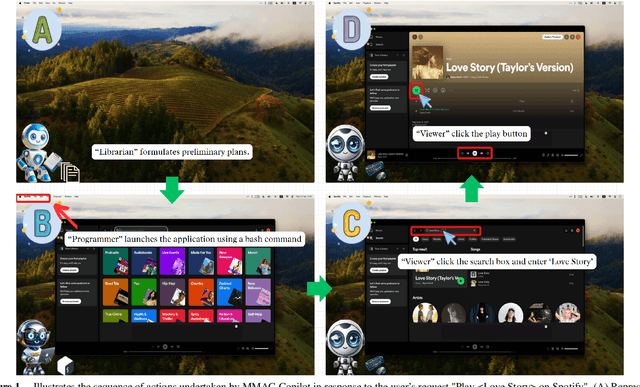
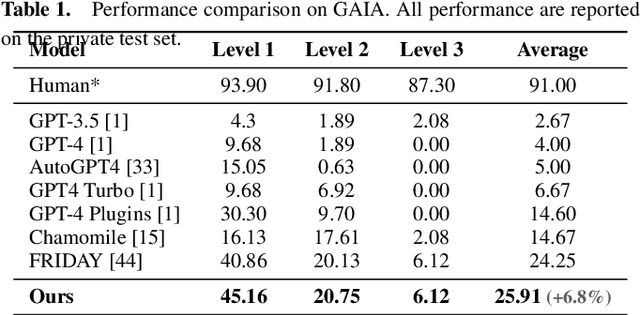
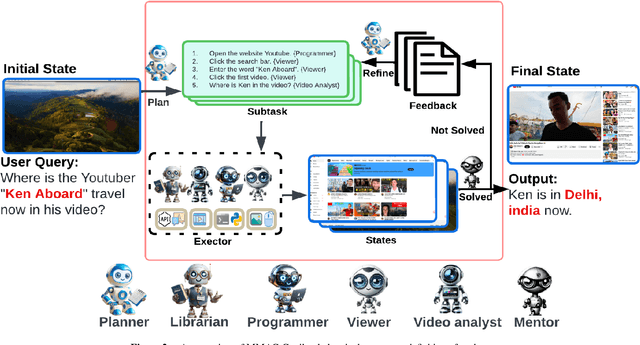

Autonomous virtual agents are often limited by their singular mode of interaction with real-world environments, restricting their versatility. To address this, we propose the Multi-Modal Agent Collaboration framework (MMAC-Copilot), a framework utilizes the collective expertise of diverse agents to enhance interaction ability with operating systems. The framework introduces a team collaboration chain, enabling each participating agent to contribute insights based on their specific domain knowledge, effectively reducing the hallucination associated with knowledge domain gaps. To evaluate the performance of MMAC-Copilot, we conducted experiments using both the GAIA benchmark and our newly introduced Visual Interaction Benchmark (VIBench). VIBench focuses on non-API-interactable applications across various domains, including 3D gaming, recreation, and office scenarios. MMAC-Copilot achieved exceptional performance on GAIA, with an average improvement of 6.8\% over existing leading systems. Furthermore, it demonstrated remarkable capability on VIBench, particularly in managing various methods of interaction within systems and applications. These results underscore MMAC-Copilot's potential in advancing the field of autonomous virtual agents through its innovative approach to agent collaboration.
Confidence Matters: Revisiting Intrinsic Self-Correction Capabilities of Large Language Models
Feb 27, 2024The recent success of Large Language Models (LLMs) has catalyzed an increasing interest in their self-correction capabilities. This paper presents a comprehensive investigation into the intrinsic self-correction of LLMs, attempting to address the ongoing debate about its feasibility. Our research has identified an important latent factor - the "confidence" of LLMs - during the self-correction process. Overlooking this factor may cause the models to over-criticize themselves, resulting in unreliable conclusions regarding the efficacy of self-correction. We have experimentally observed that LLMs possess the capability to understand the "confidence" in their own responses. It motivates us to develop an "If-or-Else" (IoE) prompting framework, designed to guide LLMs in assessing their own "confidence", facilitating intrinsic self-corrections. We conduct extensive experiments and demonstrate that our IoE-based Prompt can achieve a consistent improvement regarding the accuracy of self-corrected responses over the initial answers. Our study not only sheds light on the underlying factors affecting self-correction in LLMs, but also introduces a practical framework that utilizes the IoE prompting principle to efficiently improve self-correction capabilities with "confidence". The code is available at https://github.com/MBZUAI-CLeaR/IoE-Prompting.git.
CaRiNG: Learning Temporal Causal Representation under Non-Invertible Generation Process
Jan 25, 2024



Identifying the underlying time-delayed latent causal processes in sequential data is vital for grasping temporal dynamics and making downstream reasoning. While some recent methods can robustly identify these latent causal variables, they rely on strict assumptions about the invertible generation process from latent variables to observed data. However, these assumptions are often hard to satisfy in real-world applications containing information loss. For instance, the visual perception process translates a 3D space into 2D images, or the phenomenon of persistence of vision incorporates historical data into current perceptions. To address this challenge, we establish an identifiability theory that allows for the recovery of independent latent components even when they come from a nonlinear and non-invertible mix. Using this theory as a foundation, we propose a principled approach, CaRiNG, to learn the CAusal RepresentatIon of Non-invertible Generative temporal data with identifiability guarantees. Specifically, we utilize temporal context to recover lost latent information and apply the conditions in our theory to guide the training process. Through experiments conducted on synthetic datasets, we validate that our CaRiNG method reliably identifies the causal process, even when the generation process is non-invertible. Moreover, we demonstrate that our approach considerably improves temporal understanding and reasoning in practical applications.
BenchLMM: Benchmarking Cross-style Visual Capability of Large Multimodal Models
Dec 06, 2023



Large Multimodal Models (LMMs) such as GPT-4V and LLaVA have shown remarkable capabilities in visual reasoning with common image styles. However, their robustness against diverse style shifts, crucial for practical applications, remains largely unexplored. In this paper, we propose a new benchmark, BenchLMM, to assess the robustness of LMMs against three different styles: artistic image style, imaging sensor style, and application style, where each style has five sub-styles. Utilizing BenchLMM, we comprehensively evaluate state-of-the-art LMMs and reveal: 1) LMMs generally suffer performance degradation when working with other styles; 2) An LMM performs better than another model in common style does not guarantee its superior performance in other styles; 3) LMMs' reasoning capability can be enhanced by prompting LMMs to predict the style first, based on which we propose a versatile and training-free method for improving LMMs; 4) An intelligent LMM is expected to interpret the causes of its errors when facing stylistic variations. We hope that our benchmark and analysis can shed new light on developing more intelligent and versatile LMMs.