 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Temporal-IRL: Modeling Port Congestion and Berth Scheduling with Inverse Reinforcement Learning
Jun 24, 2025Predicting port congestion is crucial for maintaining reliable global supply chains. Accurate forecasts enableimprovedshipment planning, reducedelaysand costs, and optimizeinventoryanddistributionstrategies, thereby ensuring timely deliveries and enhancing supply chain resilience. To achieve accurate predictions, analyzing vessel behavior and their stay times at specific port terminals is essential, focusing particularly on berth scheduling under various conditions. Crucially, the model must capture and learn the underlying priorities and patterns of berth scheduling. Berth scheduling and planning are influenced by a range of factors, including incoming vessel size, waiting times, and the status of vessels within the port terminal. By observing historical Automatic Identification System (AIS) positions of vessels, we reconstruct berth schedules, which are subsequently utilized to determine the reward function via Inverse Reinforcement Learning (IRL). For this purpose, we modeled a specific terminal at the Port of New York/New Jersey and developed Temporal-IRL. This Temporal-IRL model learns berth scheduling to predict vessel sequencing at the terminal and estimate vessel port stay, encompassing both waiting and berthing times, to forecast port congestion. Utilizing data from Maher Terminal spanning January 2015 to September 2023, we trained and tested the model, achieving demonstrably excellent results.
SocialMaze: A Benchmark for Evaluating Social Reasoning in Large Language Models
May 29, 2025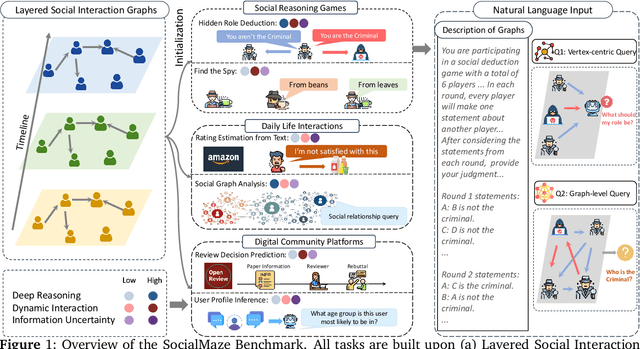
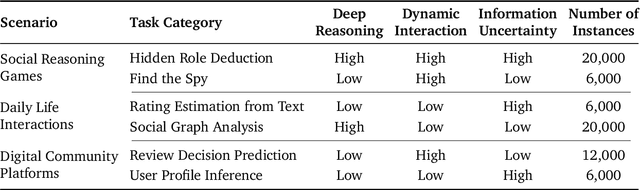
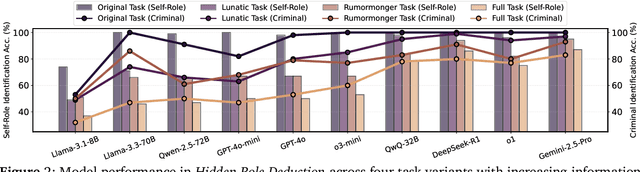
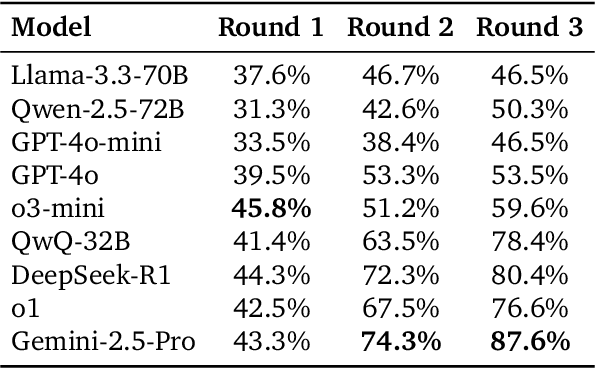
Large language models (LLMs) are increasingly applied to socially grounded tasks, such as online community moderation, media content analysis, and social reasoning games. Success in these contexts depends on a model's social reasoning ability - the capacity to interpret social contexts, infer others' mental states, and assess the truthfulness of presented information. However, there is currently no systematic evaluation framework that comprehensively assesses the social reasoning capabilities of LLMs. Existing efforts often oversimplify real-world scenarios and consist of tasks that are too basic to challenge advanced models. To address this gap, we introduce SocialMaze, a new benchmark specifically designed to evaluate social reasoning. SocialMaze systematically incorporates three core challenges: deep reasoning, dynamic interaction, and information uncertainty. It provides six diverse tasks across three key settings: social reasoning games, daily-life interactions, and digital community platforms. Both automated and human validation are used to ensure data quality. Our evaluation reveals several key insights: models vary substantially in their ability to handle dynamic interactions and integrate temporally evolving information; models with strong chain-of-thought reasoning perform better on tasks requiring deeper inference beyond surface-level cues; and model reasoning degrades significantly under uncertainty. Furthermore, we show that targeted fine-tuning on curated reasoning examples can greatly improve model performance in complex social scenarios. The dataset is publicly available at: https://huggingface.co/datasets/MBZUAI/SocialMaze
Cross-Lingual Pitfalls: Automatic Probing Cross-Lingual Weakness of Multilingual Large Language Models
May 24, 2025Large Language Models (LLMs) have achieved remarkable success in Natural Language Processing (NLP), yet their cross-lingual performance consistency remains a significant challenge. This paper introduces a novel methodology for efficiently identifying inherent cross-lingual weaknesses in LLMs. Our approach leverages beam search and LLM-based simulation to generate bilingual question pairs that expose performance discrepancies between English and target languages. We construct a new dataset of over 6,000 bilingual pairs across 16 languages using this methodology, demonstrating its effectiveness in revealing weaknesses even in state-of-the-art models. The extensive experiments demonstrate that our method precisely and cost-effectively pinpoints cross-lingual weaknesses, consistently revealing over 50\% accuracy drops in target languages across a wide range of models. Moreover, further experiments investigate the relationship between linguistic similarity and cross-lingual weaknesses, revealing that linguistically related languages share similar performance patterns and benefit from targeted post-training. Code is available at https://github.com/xzx34/Cross-Lingual-Pitfalls.
ManipLVM-R1: Reinforcement Learning for Reasoning in Embodied Manipulation with Large Vision-Language Models
May 22, 2025Large Vision-Language Models (LVLMs) have recently advanced robotic manipulation by leveraging vision for scene perception and language for instruction following. However, existing methods rely heavily on costly human-annotated training datasets, which limits their generalization and causes them to struggle in out-of-domain (OOD) scenarios, reducing real-world adaptability. To address these challenges, we propose ManipLVM-R1, a novel reinforcement learning framework that replaces traditional supervision with Reinforcement Learning using Verifiable Rewards (RLVR). By directly optimizing for task-aligned outcomes, our method enhances generalization and physical reasoning while removing the dependence on costly annotations. Specifically, we design two rule-based reward functions targeting key robotic manipulation subtasks: an Affordance Perception Reward to enhance localization of interaction regions, and a Trajectory Match Reward to ensure the physical plausibility of action paths. These rewards provide immediate feedback and impose spatial-logical constraints, encouraging the model to go beyond shallow pattern matching and instead learn deeper, more systematic reasoning about physical interactions.
Audio Jailbreak: An Open Comprehensive Benchmark for Jailbreaking Large Audio-Language Models
May 21, 2025



The rise of Large Audio Language Models (LAMs) brings both potential and risks, as their audio outputs may contain harmful or unethical content. However, current research lacks a systematic, quantitative evaluation of LAM safety especially against jailbreak attacks, which are challenging due to the temporal and semantic nature of speech. To bridge this gap, we introduce AJailBench, the first benchmark specifically designed to evaluate jailbreak vulnerabilities in LAMs. We begin by constructing AJailBench-Base, a dataset of 1,495 adversarial audio prompts spanning 10 policy-violating categories, converted from textual jailbreak attacks using realistic text to speech synthesis. Using this dataset, we evaluate several state-of-the-art LAMs and reveal that none exhibit consistent robustness across attacks. To further strengthen jailbreak testing and simulate more realistic attack conditions, we propose a method to generate dynamic adversarial variants. Our Audio Perturbation Toolkit (APT) applies targeted distortions across time, frequency, and amplitude domains. To preserve the original jailbreak intent, we enforce a semantic consistency constraint and employ Bayesian optimization to efficiently search for perturbations that are both subtle and highly effective. This results in AJailBench-APT, an extended dataset of optimized adversarial audio samples. Our findings demonstrate that even small, semantically preserved perturbations can significantly reduce the safety performance of leading LAMs, underscoring the need for more robust and semantically aware defense mechanisms.
Evaluate Bias without Manual Test Sets: A Concept Representation Perspective for LLMs
May 21, 2025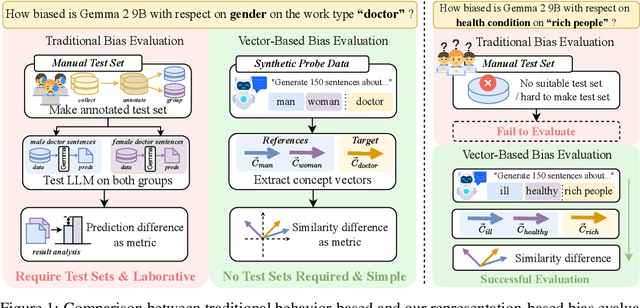
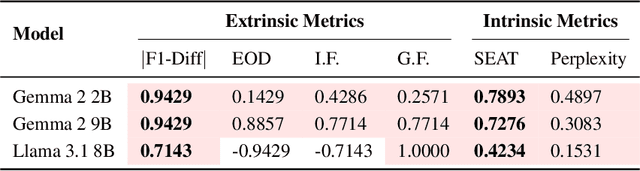
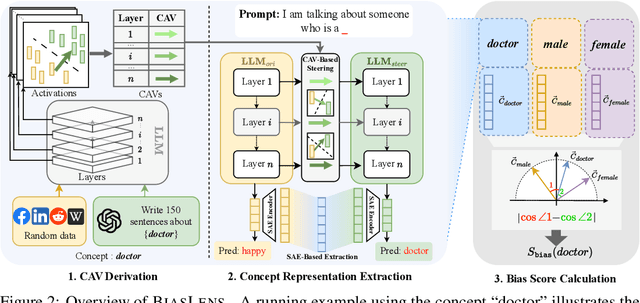
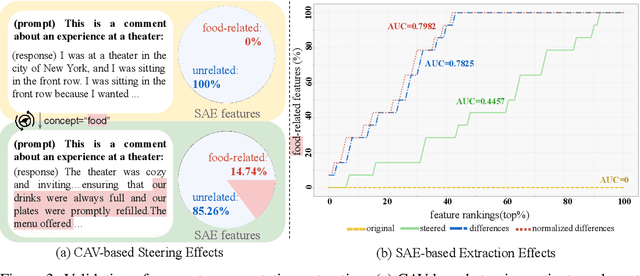
Bias in Large Language Models (LLMs) significantly undermines their reliability and fairness. We focus on a common form of bias: when two reference concepts in the model's concept space, such as sentiment polarities (e.g., "positive" and "negative"), are asymmetrically correlated with a third, target concept, such as a reviewing aspect, the model exhibits unintended bias. For instance, the understanding of "food" should not skew toward any particular sentiment. Existing bias evaluation methods assess behavioral differences of LLMs by constructing labeled data for different social groups and measuring model responses across them, a process that requires substantial human effort and captures only a limited set of social concepts. To overcome these limitations, we propose BiasLens, a test-set-free bias analysis framework based on the structure of the model's vector space. BiasLens combines Concept Activation Vectors (CAVs) with Sparse Autoencoders (SAEs) to extract interpretable concept representations, and quantifies bias by measuring the variation in representational similarity between the target concept and each of the reference concepts. Even without labeled data, BiasLens shows strong agreement with traditional bias evaluation metrics (Spearman correlation r > 0.85). Moreover, BiasLens reveals forms of bias that are difficult to detect using existing methods. For example, in simulated clinical scenarios, a patient's insurance status can cause the LLM to produce biased diagnostic assessments. Overall, BiasLens offers a scalable, interpretable, and efficient paradigm for bias discovery, paving the way for improving fairness and transparency in LLMs.
Breaking Focus: Contextual Distraction Curse in Large Language Models
Feb 03, 2025



Recent advances in Large Language Models (LLMs) have revolutionized generative systems, achieving excellent performance across diverse domains. Although these models perform well in controlled environments, their real-world applications frequently encounter inputs containing both essential and irrelevant details. Our investigation has revealed a critical vulnerability in LLMs, which we term Contextual Distraction Vulnerability (CDV). This phenomenon arises when models fail to maintain consistent performance on questions modified with semantically coherent but irrelevant context. To systematically investigate this vulnerability, we propose an efficient tree-based search methodology to automatically generate CDV examples. Our approach successfully generates CDV examples across four datasets, causing an average performance degradation of approximately 45% in state-of-the-art LLMs. To address this critical issue, we explore various mitigation strategies and find that post-targeted training approaches can effectively enhance model robustness against contextual distractions. Our findings highlight the fundamental nature of CDV as an ability-level challenge rather than a knowledge-level issue since models demonstrate the necessary knowledge by answering correctly in the absence of distractions. This calls the community's attention to address CDV during model development to ensure reliability. The code is available at https://github.com/wyf23187/LLM_CDV.
MTFusion: Reconstructing Any 3D Object from Single Image Using Multi-word Textual Inversion
Nov 19, 2024Reconstructing 3D models from single-view images is a long-standing problem in computer vision. The latest advances for single-image 3D reconstruction extract a textual description from the input image and further utilize it to synthesize 3D models. However, existing methods focus on capturing a single key attribute of the image (e.g., object type, artistic style) and fail to consider the multi-perspective information required for accurate 3D reconstruction, such as object shape and material properties. Besides, the reliance on Neural Radiance Fields hinders their ability to reconstruct intricate surfaces and texture details. In this work, we propose MTFusion, which leverages both image data and textual descriptions for high-fidelity 3D reconstruction. Our approach consists of two stages. First, we adopt a novel multi-word textual inversion technique to extract a detailed text description capturing the image's characteristics. Then, we use this description and the image to generate a 3D model with FlexiCubes. Additionally, MTFusion enhances FlexiCubes by employing a special decoder network for Signed Distance Functions, leading to faster training and finer surface representation. Extensive evaluations demonstrate that our MTFusion surpasses existing image-to-3D methods on a wide range of synthetic and real-world images. Furthermore, the ablation study proves the effectiveness of our network designs.
* PRCV 2024
GenUDC: High Quality 3D Mesh Generation with Unsigned Dual Contouring Representation
Oct 23, 2024Generating high-quality meshes with complex structures and realistic surfaces is the primary goal of 3D generative models. Existing methods typically employ sequence data or deformable tetrahedral grids for mesh generation. However, sequence-based methods have difficulty producing complex structures with many faces due to memory limits. The deformable tetrahedral grid-based method MeshDiffusion fails to recover realistic surfaces due to the inherent ambiguity in deformable grids. We propose the GenUDC framework to address these challenges by leveraging the Unsigned Dual Contouring (UDC) as the mesh representation. UDC discretizes a mesh in a regular grid and divides it into the face and vertex parts, recovering both complex structures and fine details. As a result, the one-to-one mapping between UDC and mesh resolves the ambiguity problem. In addition, GenUDC adopts a two-stage, coarse-to-fine generative process for 3D mesh generation. It first generates the face part as a rough shape and then the vertex part to craft a detailed shape. Extensive evaluations demonstrate the superiority of UDC as a mesh representation and the favorable performance of GenUDC in mesh generation. The code and trained models are available at https://github.com/TrepangCat/GenUDC.