 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePASDiff: Physics-Aware Semantic Guidance for Joint Real-world Low-Light Face Enhancement and Restoration
Mar 26, 2026Face images captured in real-world low light suffer multiple degradations-low illumination, blur, noise, and low visibility, etc. Existing cascaded solutions often suffer from severe error accumulation, while generic joint models lack explicit facial priors and struggle to resolve clear face structures. In this paper, we propose PASDiff, a Physics-Aware Semantic Diffusion with a training-free manner. To achieve a plausible illumination and color distribution, we leverage inverse intensity weighting and Retinex theory to introduce photometric constraints, thereby reliably recovering visibility and natural chromaticity. To faithfully reconstruct facial details, our Style-Agnostic Structural Injection (SASI) extracts structures from an off-the-shelf facial prior while filtering out its intrinsic photometric biases, seamlessly harmonizing identity features with physical constraints. Furthermore, we construct WildDark-Face, a real-world benchmark of 700 low-light facial images with complex degradations. Extensive experiments demonstrate that PASDiff significantly outperforms existing methods, achieving a superior balance among natural illumination, color recovery, and identity consistency.
Measurement-Constrained Sampling for Text-Prompted Blind Face Restoration
Nov 18, 2025



Blind face restoration (BFR) may correspond to multiple plausible high-quality (HQ) reconstructions under extremely low-quality (LQ) inputs. However, existing methods typically produce deterministic results, struggling to capture this one-to-many nature. In this paper, we propose a Measurement-Constrained Sampling (MCS) approach that enables diverse LQ face reconstructions conditioned on different textual prompts. Specifically, we formulate BFR as a measurement-constrained generative task by constructing an inverse problem through controlled degradations of coarse restorations, which allows posterior-guided sampling within text-to-image diffusion. Measurement constraints include both Forward Measurement, which ensures results align with input structures, and Reverse Measurement, which produces projection spaces, ensuring that the solution can align with various prompts. Experiments show that our MCS can generate prompt-aligned results and outperforms existing BFR methods. Codes will be released after acceptance.
FADPNet: Frequency-Aware Dual-Path Network for Face Super-Resolution
Jun 17, 2025Face super-resolution (FSR) under limited computational costs remains an open problem. Existing approaches typically treat all facial pixels equally, resulting in suboptimal allocation of computational resources and degraded FSR performance. CNN is relatively sensitive to high-frequency facial features, such as component contours and facial outlines. Meanwhile, Mamba excels at capturing low-frequency features like facial color and fine-grained texture, and does so with lower complexity than Transformers. Motivated by these observations, we propose FADPNet, a Frequency-Aware Dual-Path Network that decomposes facial features into low- and high-frequency components and processes them via dedicated branches. For low-frequency regions, we introduce a Mamba-based Low-Frequency Enhancement Block (LFEB), which combines state-space attention with squeeze-and-excitation operations to extract low-frequency global interactions and emphasize informative channels. For high-frequency regions, we design a CNN-based Deep Position-Aware Attention (DPA) module to enhance spatially-dependent structural details, complemented by a lightweight High-Frequency Refinement (HFR) module that further refines frequency-specific representations. Through the above designs, our method achieves an excellent balance between FSR quality and model efficiency, outperforming existing approaches.
S2AFormer: Strip Self-Attention for Efficient Vision Transformer
May 28, 2025Vision Transformer (ViT) has made significant advancements in computer vision, thanks to its token mixer's sophisticated ability to capture global dependencies between all tokens. However, the quadratic growth in computational demands as the number of tokens increases limits its practical efficiency. Although recent methods have combined the strengths of convolutions and self-attention to achieve better trade-offs, the expensive pairwise token affinity and complex matrix operations inherent in self-attention remain a bottleneck. To address this challenge, we propose S2AFormer, an efficient Vision Transformer architecture featuring novel Strip Self-Attention (SSA). We design simple yet effective Hybrid Perception Blocks (HPBs) to effectively integrate the local perception capabilities of CNNs with the global context modeling of Transformer's attention mechanisms. A key innovation of SSA lies in its reducing the spatial dimensions of $K$ and $V$ while compressing the channel dimensions of $Q$ and $K$. This design significantly reduces computational overhead while preserving accuracy, striking an optimal balance between efficiency and effectiveness. We evaluate the robustness and efficiency of S2AFormer through extensive experiments on multiple vision benchmarks, including ImageNet-1k for image classification, ADE20k for semantic segmentation, and COCO for object detection and instance segmentation. Results demonstrate that S2AFormer achieves significant accuracy gains with superior efficiency in both GPU and non-GPU environments, making it a strong candidate for efficient vision Transformers.
Cross Paradigm Representation and Alignment Transformer for Image Deraining
Apr 23, 2025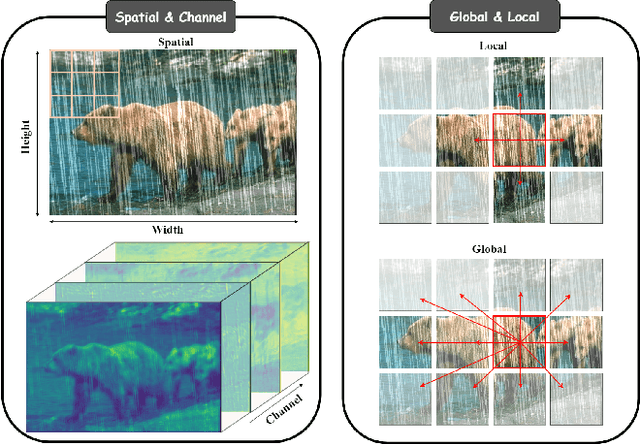
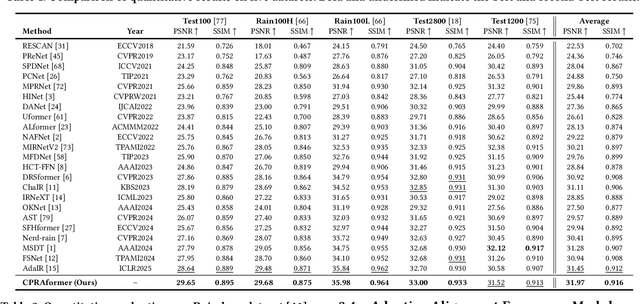
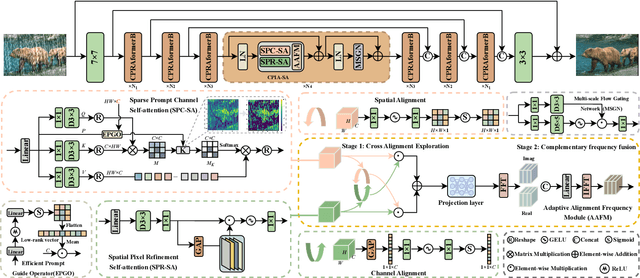
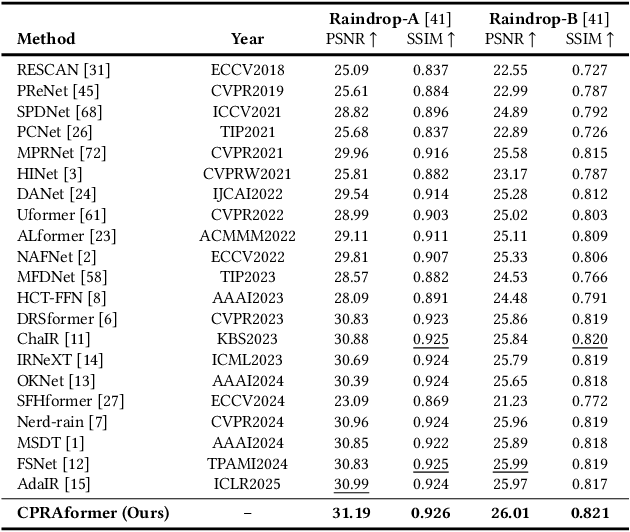
Transformer-based networks have achieved strong performance in low-level vision tasks like image deraining by utilizing spatial or channel-wise self-attention. However, irregular rain patterns and complex geometric overlaps challenge single-paradigm architectures, necessitating a unified framework to integrate complementary global-local and spatial-channel representations. To address this, we propose a novel Cross Paradigm Representation and Alignment Transformer (CPRAformer). Its core idea is the hierarchical representation and alignment, leveraging the strengths of both paradigms (spatial-channel and global-local) to aid image reconstruction. It bridges the gap within and between paradigms, aligning and coordinating them to enable deep interaction and fusion of features. Specifically, we use two types of self-attention in the Transformer blocks: sparse prompt channel self-attention (SPC-SA) and spatial pixel refinement self-attention (SPR-SA). SPC-SA enhances global channel dependencies through dynamic sparsity, while SPR-SA focuses on spatial rain distribution and fine-grained texture recovery. To address the feature misalignment and knowledge differences between them, we introduce the Adaptive Alignment Frequency Module (AAFM), which aligns and interacts with features in a two-stage progressive manner, enabling adaptive guidance and complementarity. This reduces the information gap within and between paradigms. Through this unified cross-paradigm dynamic interaction framework, we achieve the extraction of the most valuable interactive fusion information from the two paradigms. Extensive experiments demonstrate that our model achieves state-of-the-art performance on eight benchmark datasets and further validates CPRAformer's robustness in other image restoration tasks and downstream applications.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
Fraesormer: Learning Adaptive Sparse Transformer for Efficient Food Recognition
Mar 15, 2025In recent years, Transformer has witnessed significant progress in food recognition. However, most existing approaches still face two critical challenges in lightweight food recognition: (1) the quadratic complexity and redundant feature representation from interactions with irrelevant tokens; (2) static feature recognition and single-scale representation, which overlook the unstructured, non-fixed nature of food images and the need for multi-scale features. To address these, we propose an adaptive and efficient sparse Transformer architecture (Fraesormer) with two core designs: Adaptive Top-k Sparse Partial Attention (ATK-SPA) and Hierarchical Scale-Sensitive Feature Gating Network (HSSFGN). ATK-SPA uses a learnable Gated Dynamic Top-K Operator (GDTKO) to retain critical attention scores, filtering low query-key matches that hinder feature aggregation. It also introduces a partial channel mechanism to reduce redundancy and promote expert information flow, enabling local-global collaborative modeling. HSSFGN employs gating mechanism to achieve multi-scale feature representation, enhancing contextual semantic information. Extensive experiments show that Fraesormer outperforms state-of-the-art methods. code is available at https://zs1314.github.io/Fraesormer.
Learning Dual-Domain Multi-Scale Representations for Single Image Deraining
Mar 15, 2025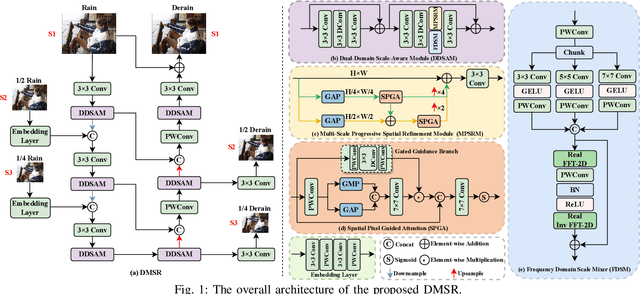
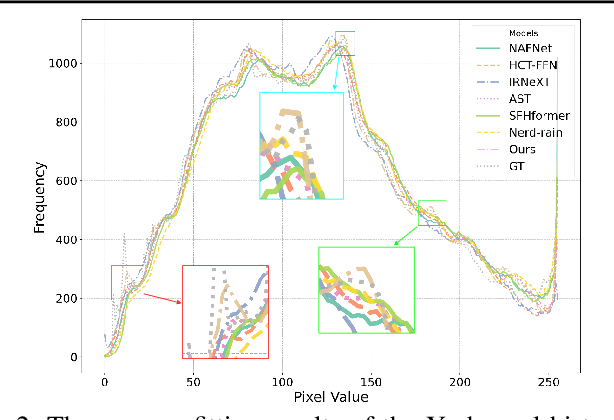

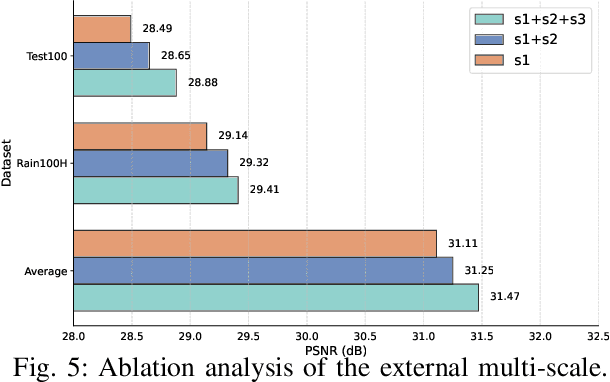
Existing image deraining methods typically rely on single-input, single-output, and single-scale architectures, which overlook the joint multi-scale information between external and internal features. Furthermore, single-domain representations are often too restrictive, limiting their ability to handle the complexities of real-world rain scenarios. To address these challenges, we propose a novel Dual-Domain Multi-Scale Representation Network (DMSR). The key idea is to exploit joint multi-scale representations from both external and internal domains in parallel while leveraging the strengths of both spatial and frequency domains to capture more comprehensive properties. Specifically, our method consists of two main components: the Multi-Scale Progressive Spatial Refinement Module (MPSRM) and the Frequency Domain Scale Mixer (FDSM). The MPSRM enables the interaction and coupling of multi-scale expert information within the internal domain using a hierarchical modulation and fusion strategy. The FDSM extracts multi-scale local information in the spatial domain, while also modeling global dependencies in the frequency domain. Extensive experiments show that our model achieves state-of-the-art performance across six benchmark datasets.
Dual-domain Modulation Network for Lightweight Image Super-Resolution
Mar 13, 2025Lightweight image super-resolution (SR) aims to reconstruct high-resolution images from low-resolution images with limited computational costs. We find existing frequency-based SR methods cannot balance the reconstruction of overall structures and high-frequency parts. Meanwhile, these methods are inefficient for handling frequency features and unsuitable for lightweight SR. In this paper, we show introducing both wavelet and Fourier information allows our model to consider both high-frequency features and overall SR structure reconstruction while reducing costs. Specifically, we propose a dual-domain modulation network that utilize wavelet-domain modulation self-Transformer (WMT) plus Fourier supervision to modulate frequency features in addition to spatial domain modulation. Compared to existing frequency-based SR modules, our WMT is more suitable for frequency learning in lightweight SR. Experimental results show that our method achieves a comparable PSNR of SRFormer and MambaIR while with less than 50% and 60% of their FLOPs and achieving inference speeds 15.4x and 5.4x faster, respectively, demonstrating the effectiveness of our method on SR quality and lightweight. Codes will be released upon acceptance.
SCASeg: Strip Cross-Attention for Efficient Semantic Segmentation
Nov 26, 2024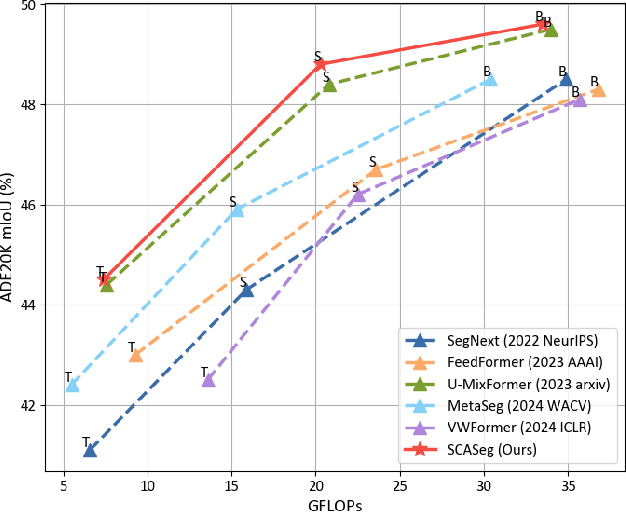

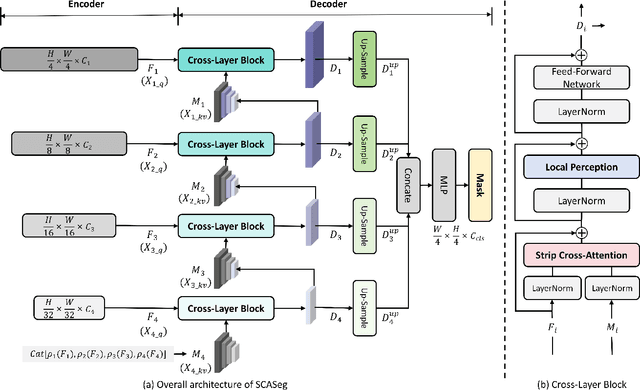

The Vision Transformer (ViT) has achieved notable success in computer vision, with its variants extensively validated across various downstream tasks, including semantic segmentation. However, designed as general-purpose visual encoders, ViT backbones often overlook the specific needs of task decoders, revealing opportunities to design decoders tailored to efficient semantic segmentation. This paper proposes Strip Cross-Attention (SCASeg), an innovative decoder head explicitly designed for semantic segmentation. Instead of relying on the simple conventional skip connections, we employ lateral connections between the encoder and decoder stages, using encoder features as Queries for the cross-attention modules. Additionally, we introduce a Cross-Layer Block that blends hierarchical feature maps from different encoder and decoder stages to create a unified representation for Keys and Values. To further boost computational efficiency, SCASeg compresses queries and keys into strip-like patterns to optimize memory usage and inference speed over the traditional vanilla cross-attention. Moreover, the Cross-Layer Block incorporates the local perceptual strengths of convolution, enabling SCASeg to capture both global and local context dependencies across multiple layers. This approach facilitates effective feature interaction at different scales, improving the overall performance. Experiments show that the adaptable decoder of SCASeg produces competitive performance across different setups, surpassing leading segmentation architectures on all benchmark datasets, including ADE20K, Cityscapes, COCO-Stuff 164k, and Pascal VOC2012, even under varying computational limitations.