 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCASeg: Strip Cross-Attention for Efficient Semantic Segmentation
Paper and Code
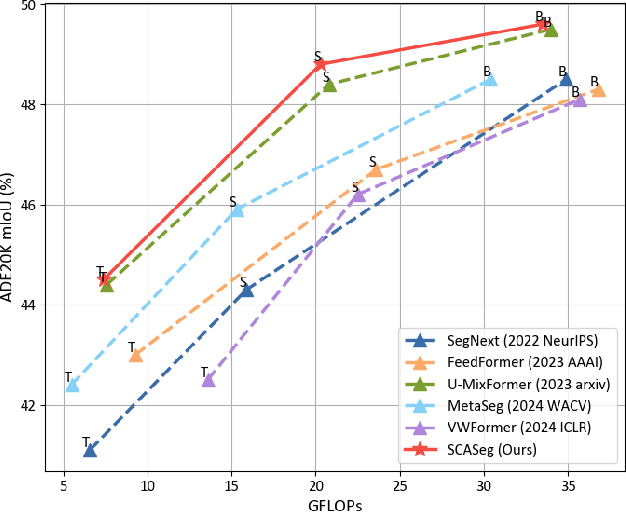

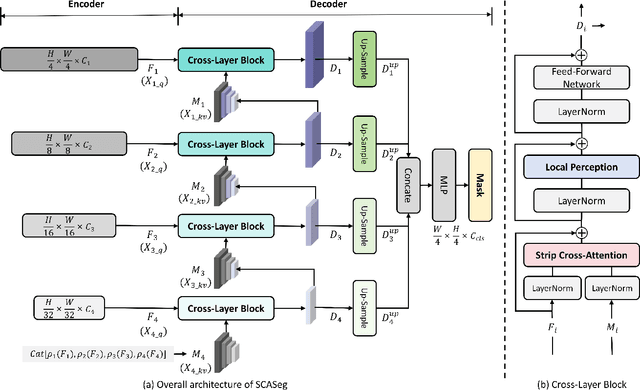

The Vision Transformer (ViT) has achieved notable success in computer vision, with its variants extensively validated across various downstream tasks, including semantic segmentation. However, designed as general-purpose visual encoders, ViT backbones often overlook the specific needs of task decoders, revealing opportunities to design decoders tailored to efficient semantic segmentation. This paper proposes Strip Cross-Attention (SCASeg), an innovative decoder head explicitly designed for semantic segmentation. Instead of relying on the simple conventional skip connections, we employ lateral connections between the encoder and decoder stages, using encoder features as Queries for the cross-attention modules. Additionally, we introduce a Cross-Layer Block that blends hierarchical feature maps from different encoder and decoder stages to create a unified representation for Keys and Values. To further boost computational efficiency, SCASeg compresses queries and keys into strip-like patterns to optimize memory usage and inference speed over the traditional vanilla cross-attention. Moreover, the Cross-Layer Block incorporates the local perceptual strengths of convolution, enabling SCASeg to capture both global and local context dependencies across multiple layers. This approach facilitates effective feature interaction at different scales, improving the overall performance. Experiments show that the adaptable decoder of SCASeg produces competitive performance across different setups, surpassing leading segmentation architectures on all benchmark datasets, including ADE20K, Cityscapes, COCO-Stuff 164k, and Pascal VOC2012, even under varying computational limitations.